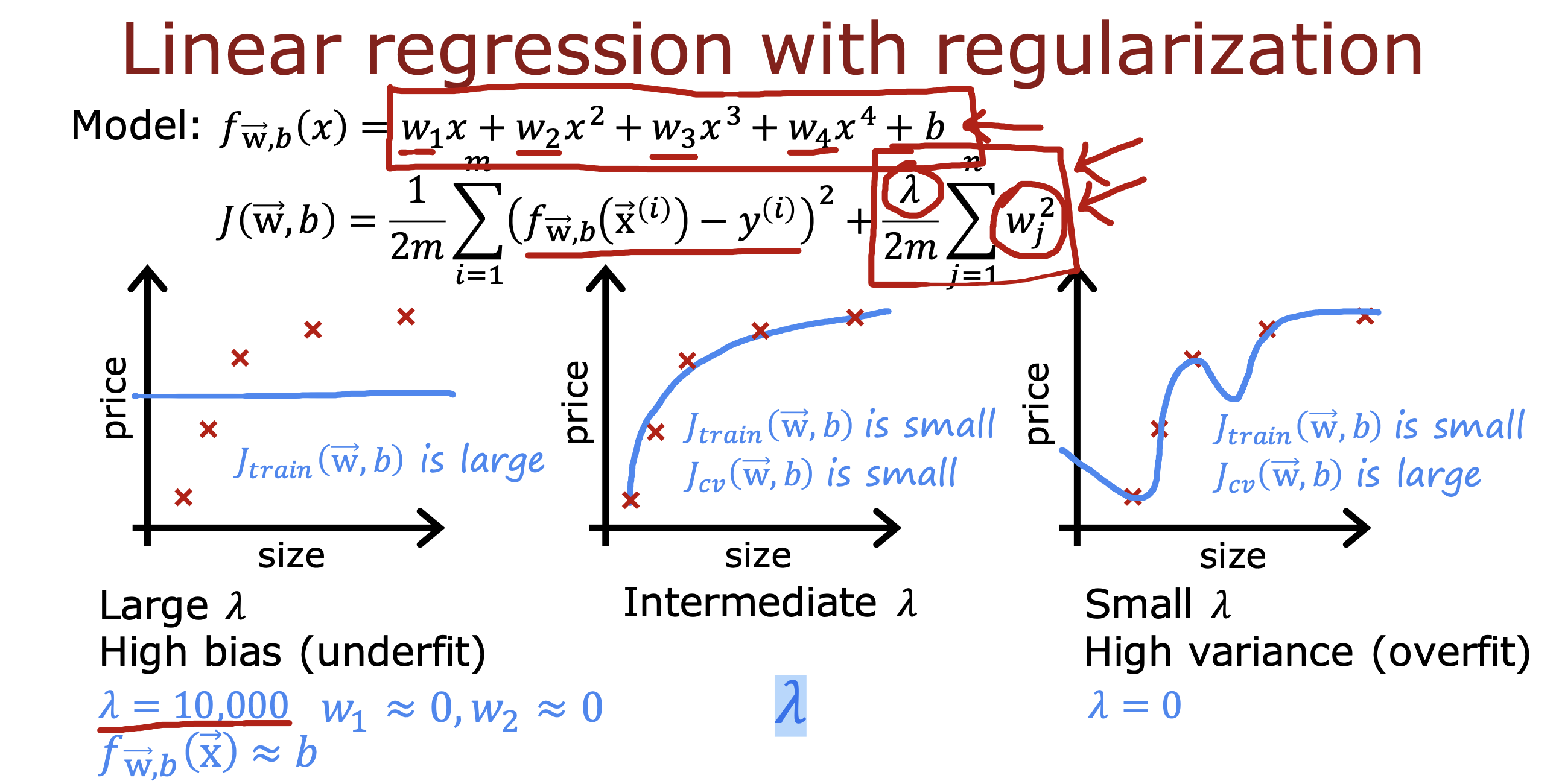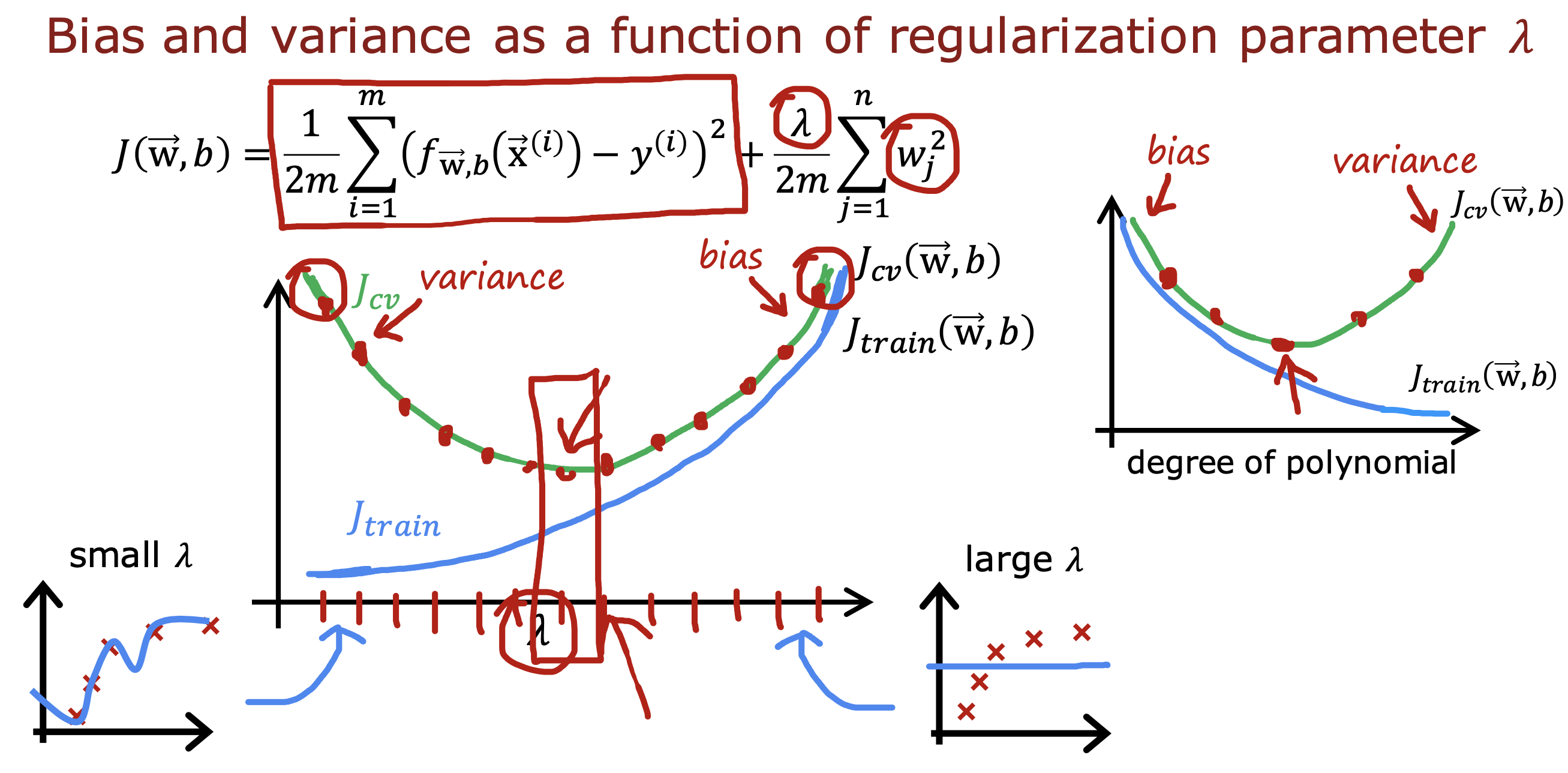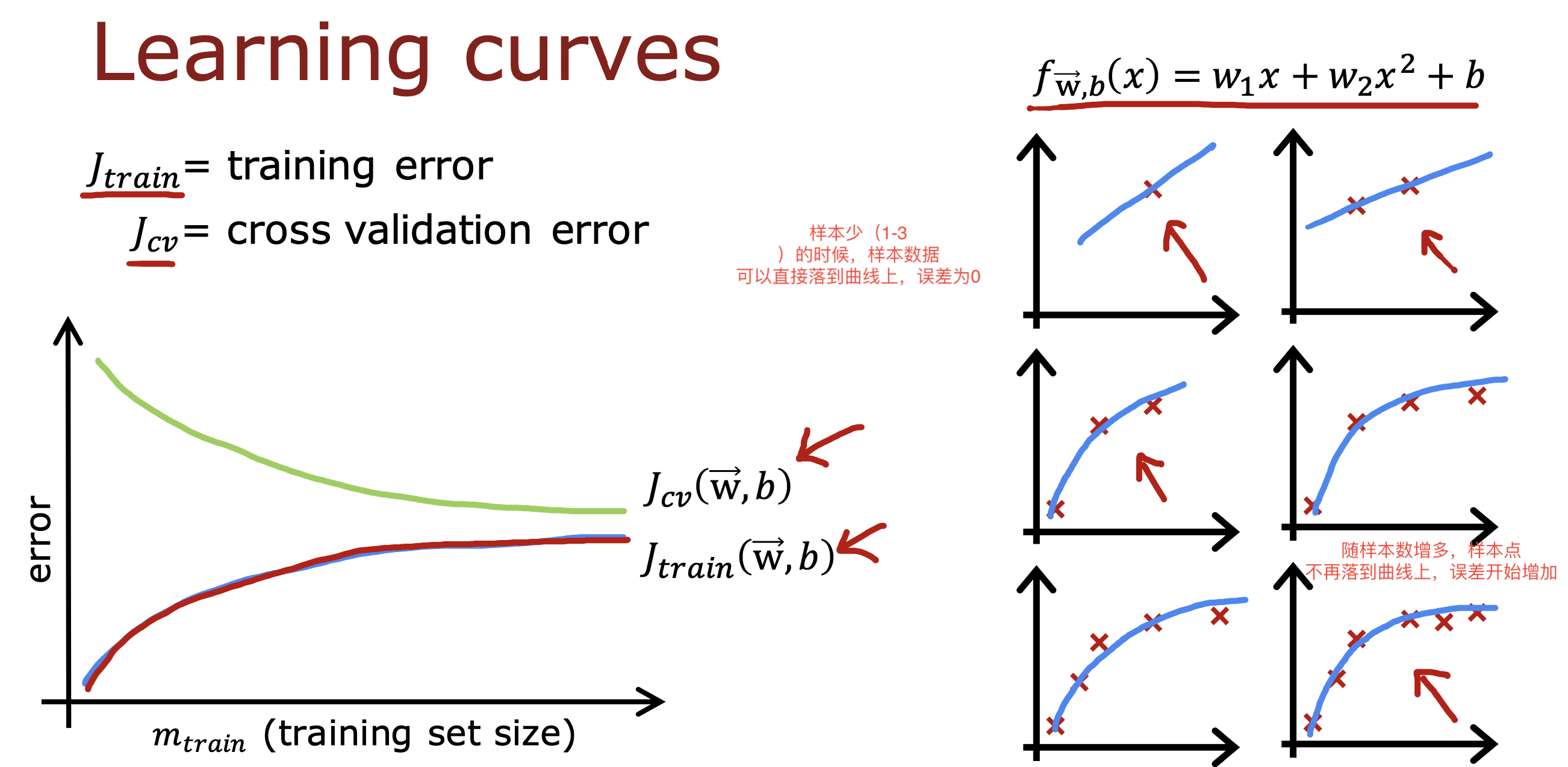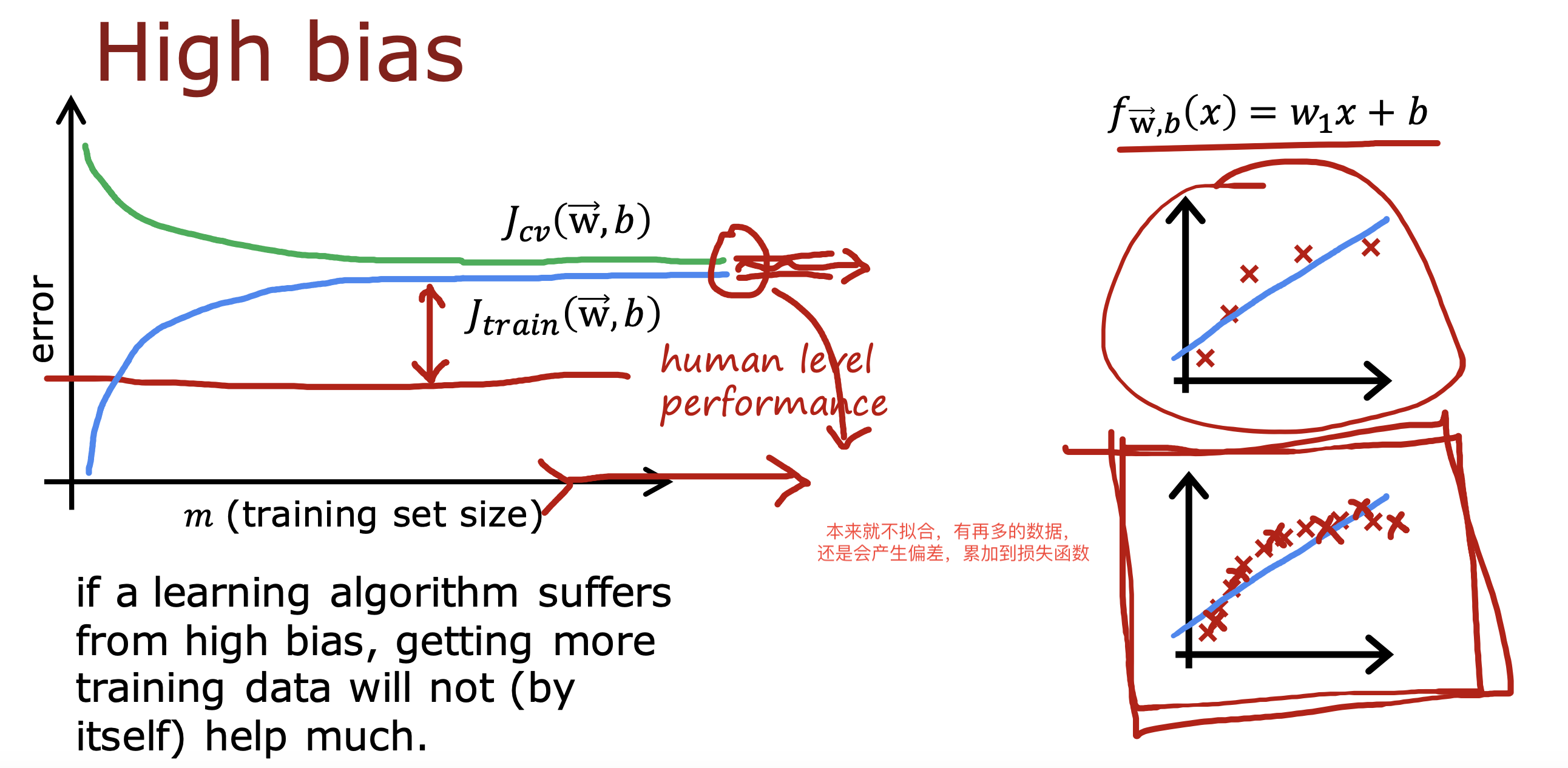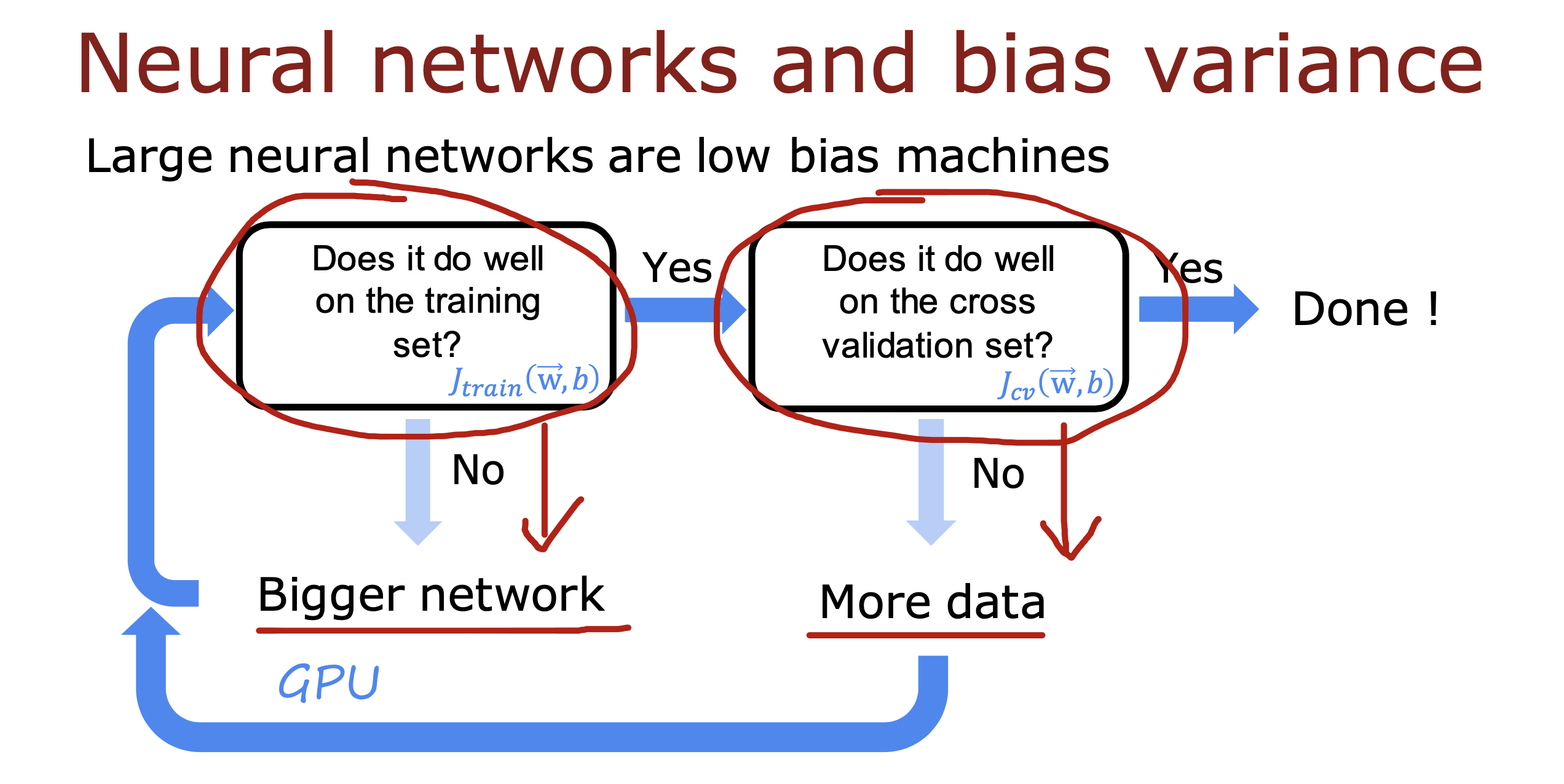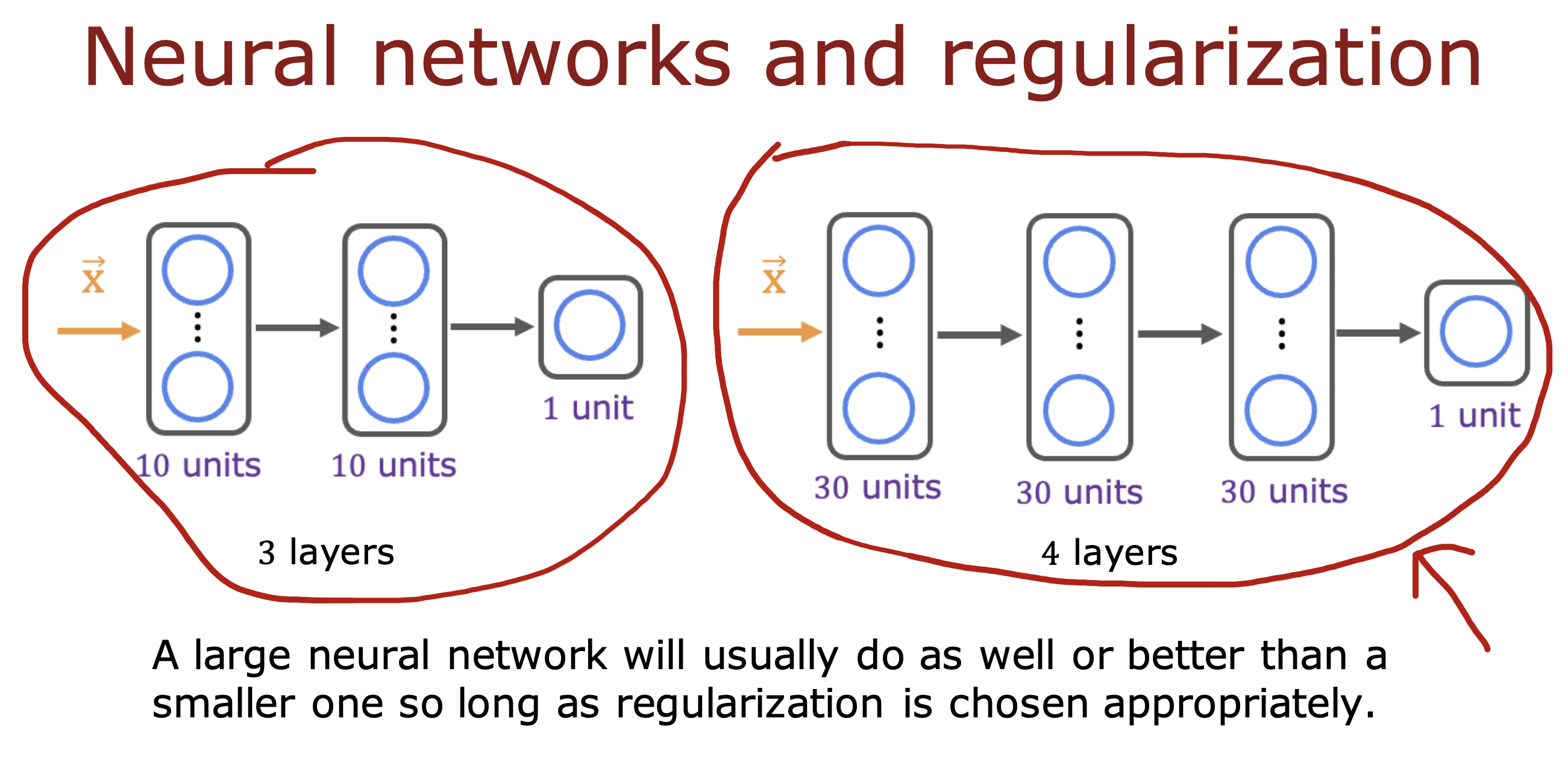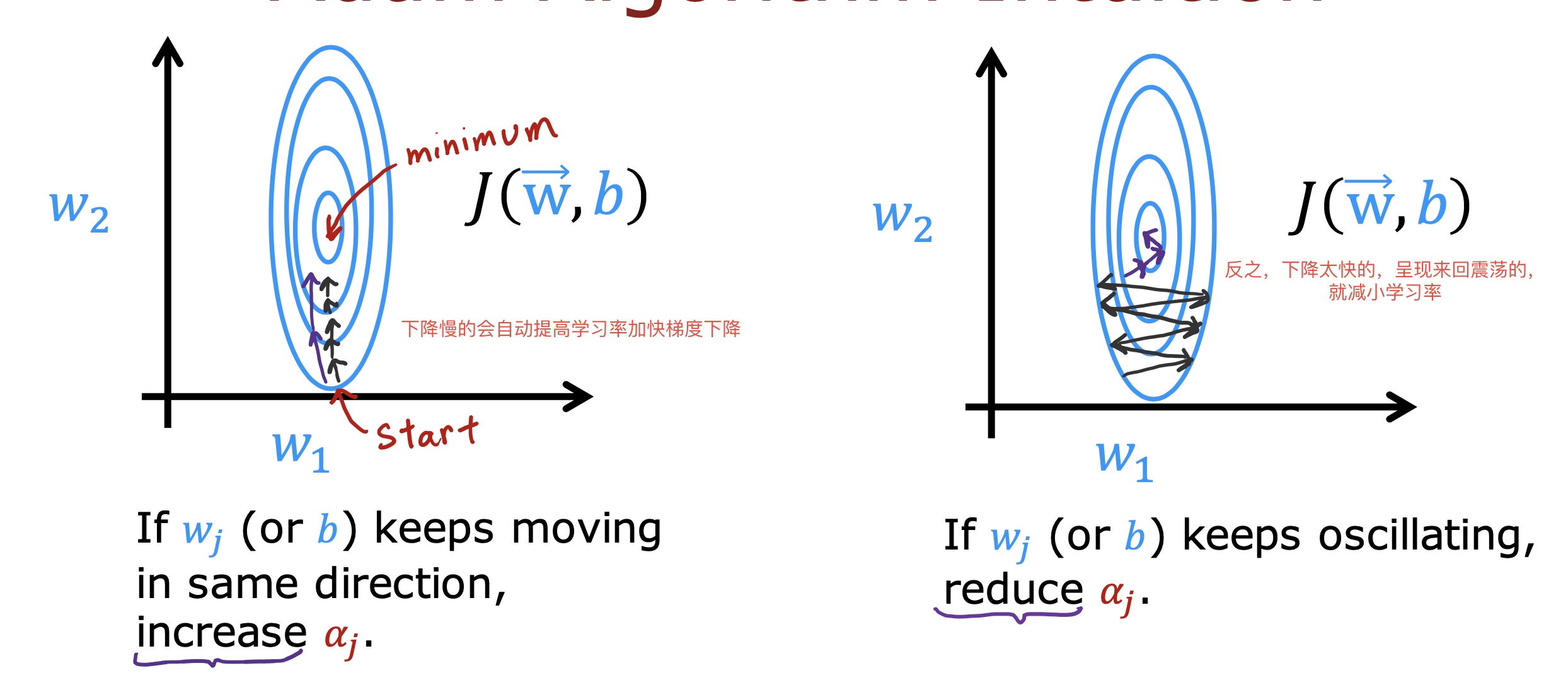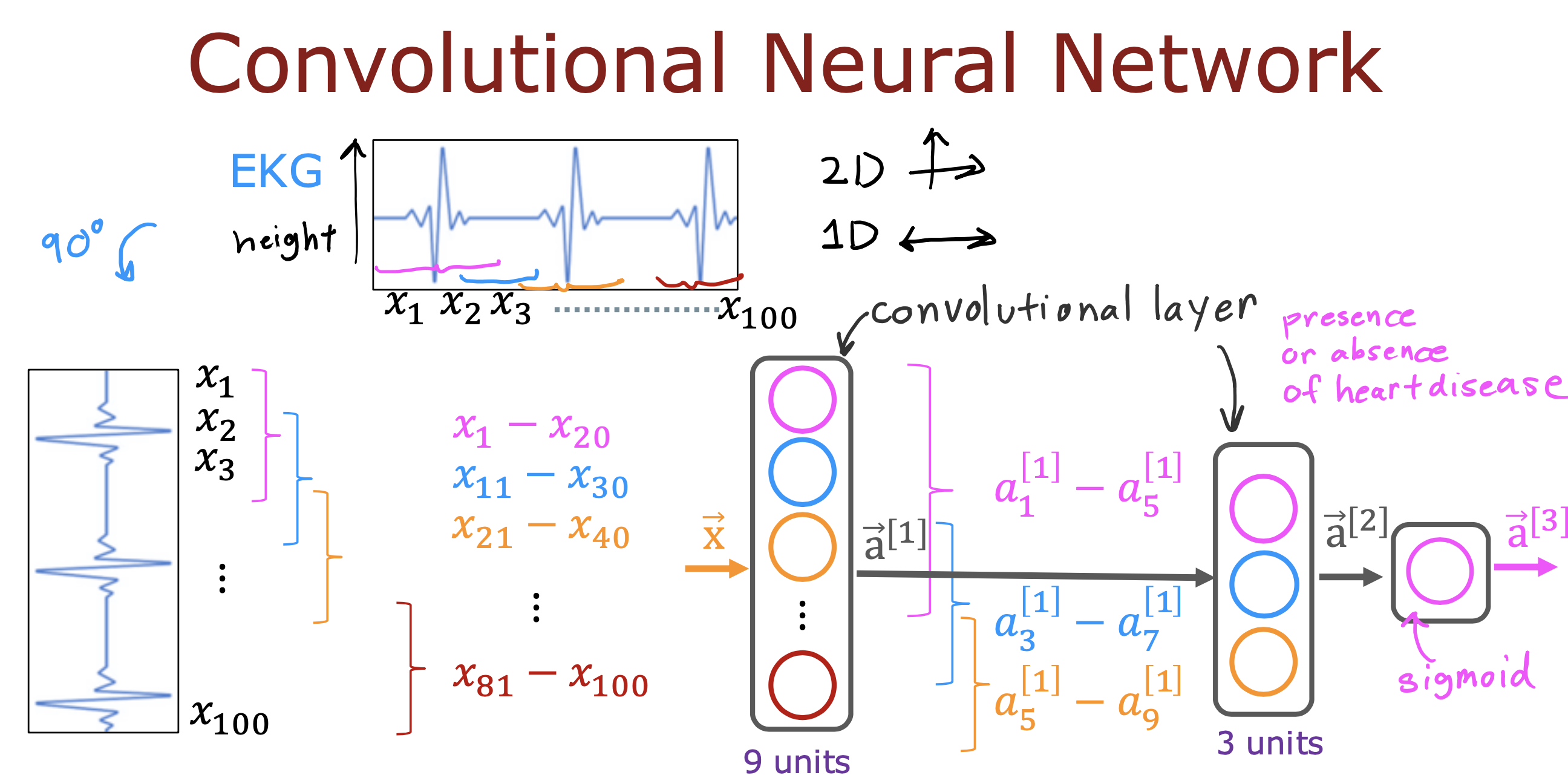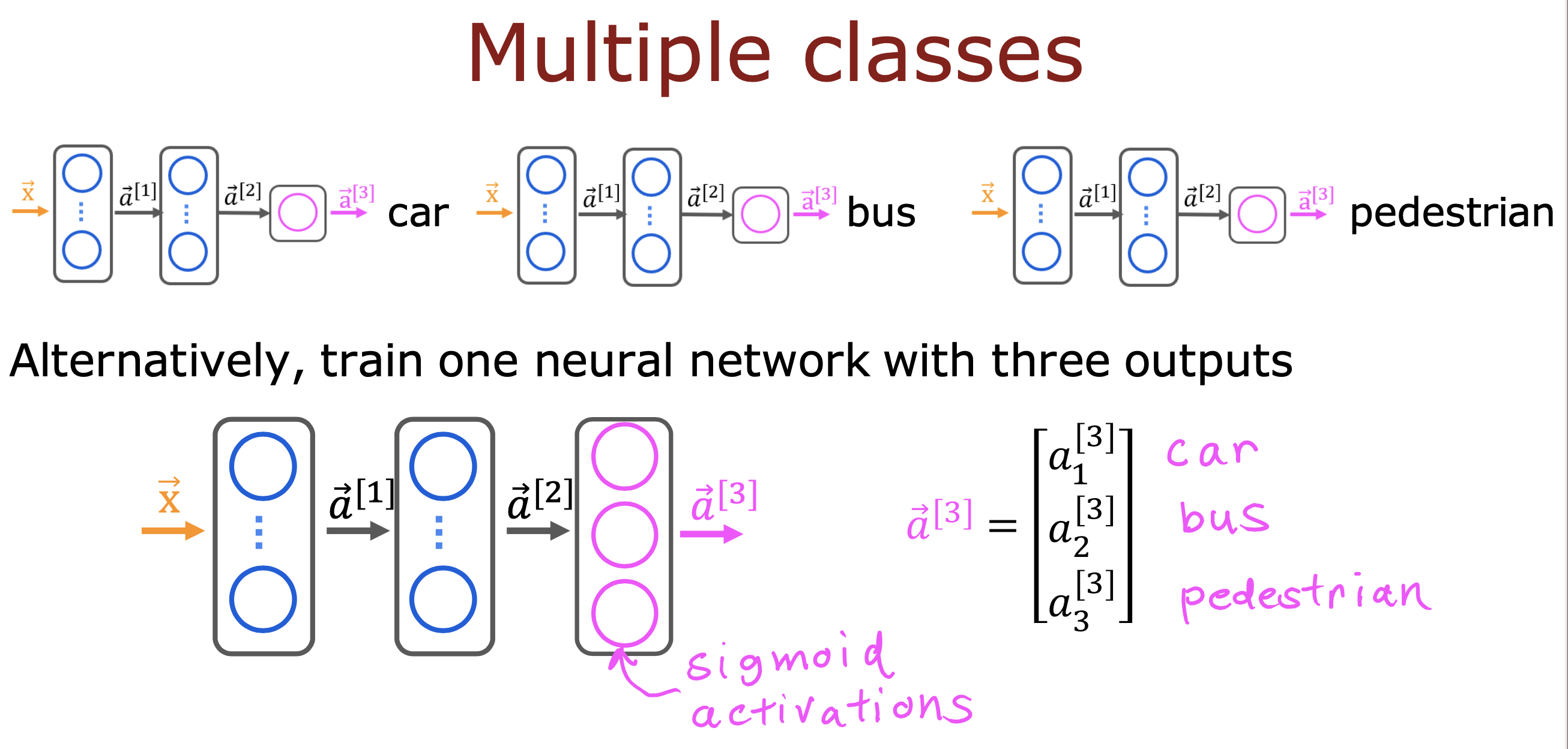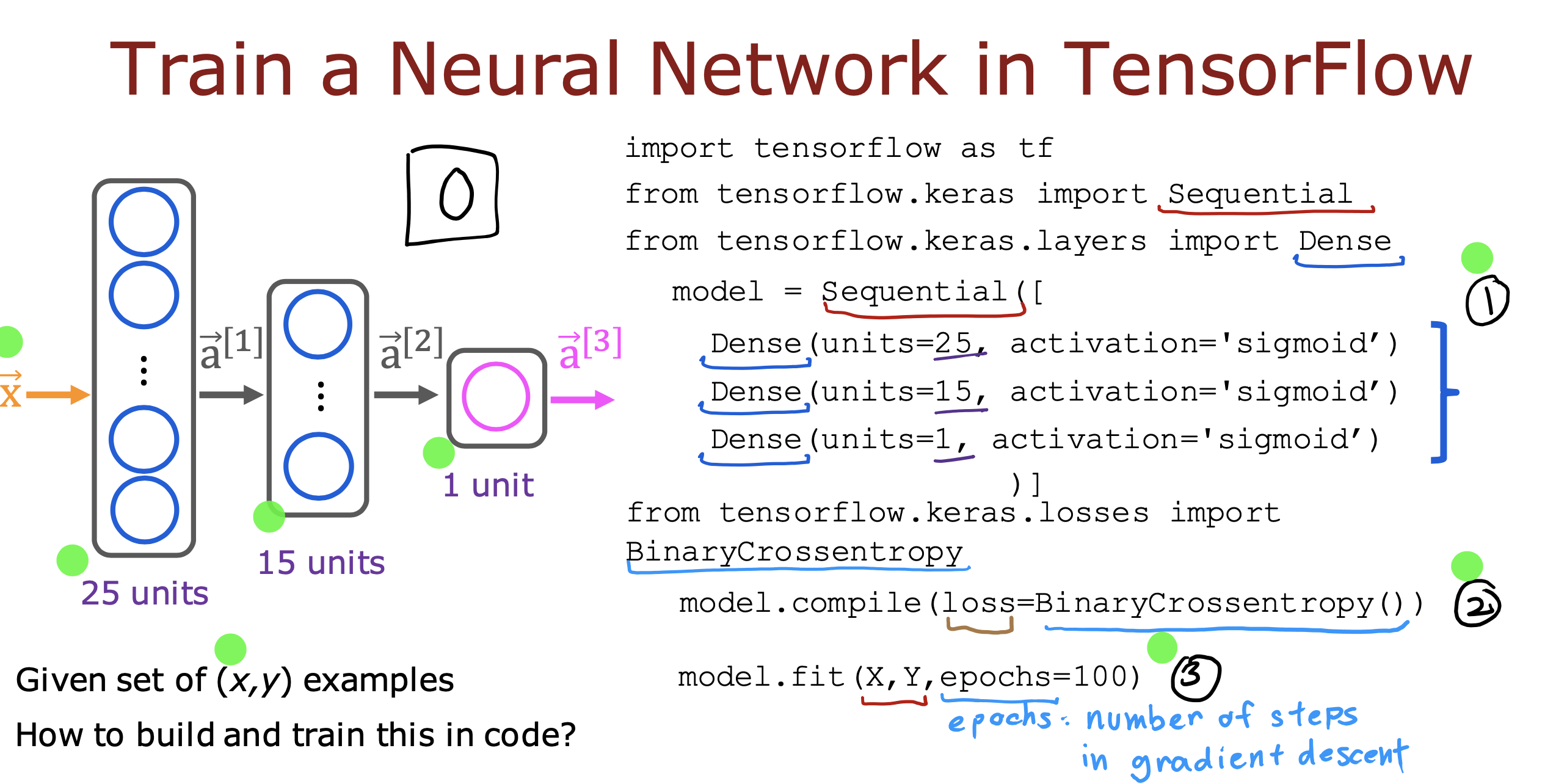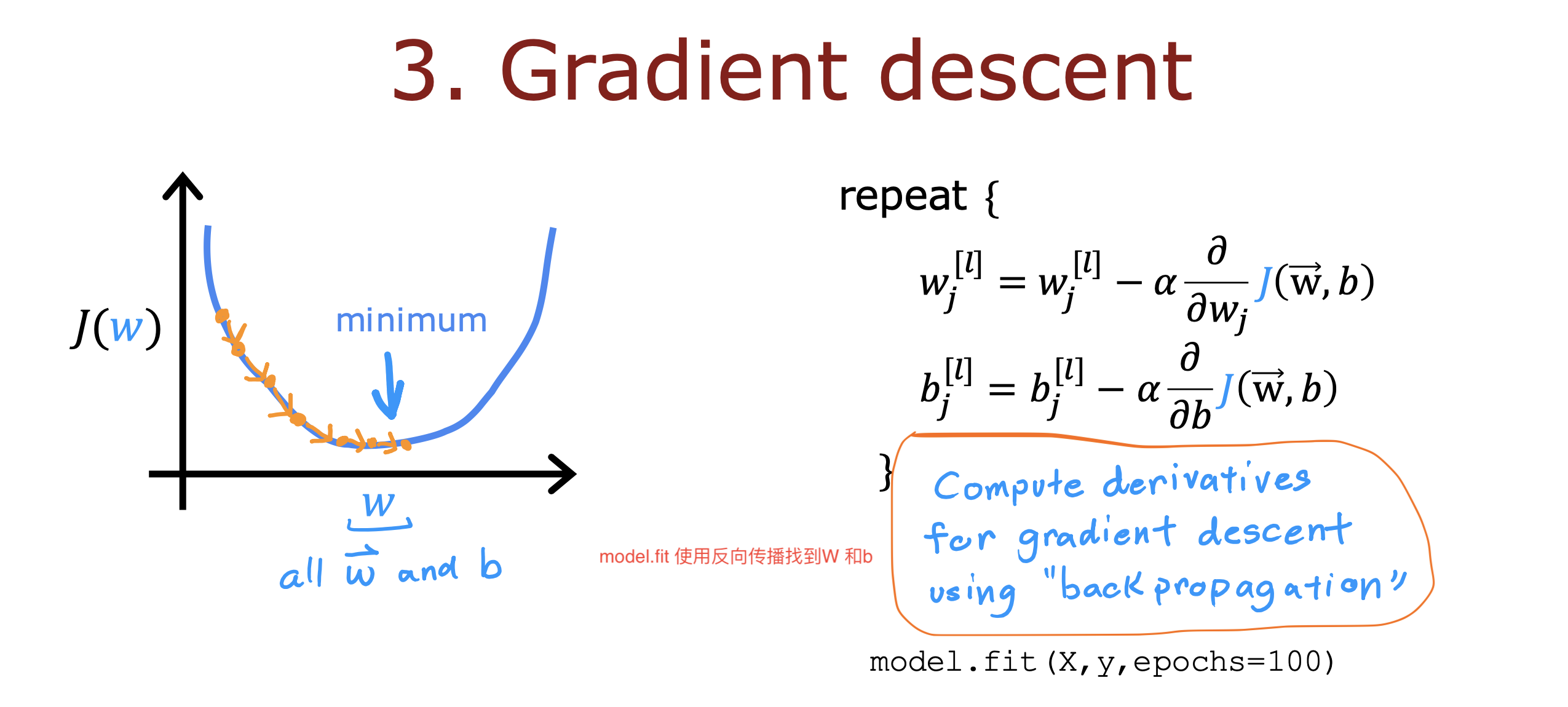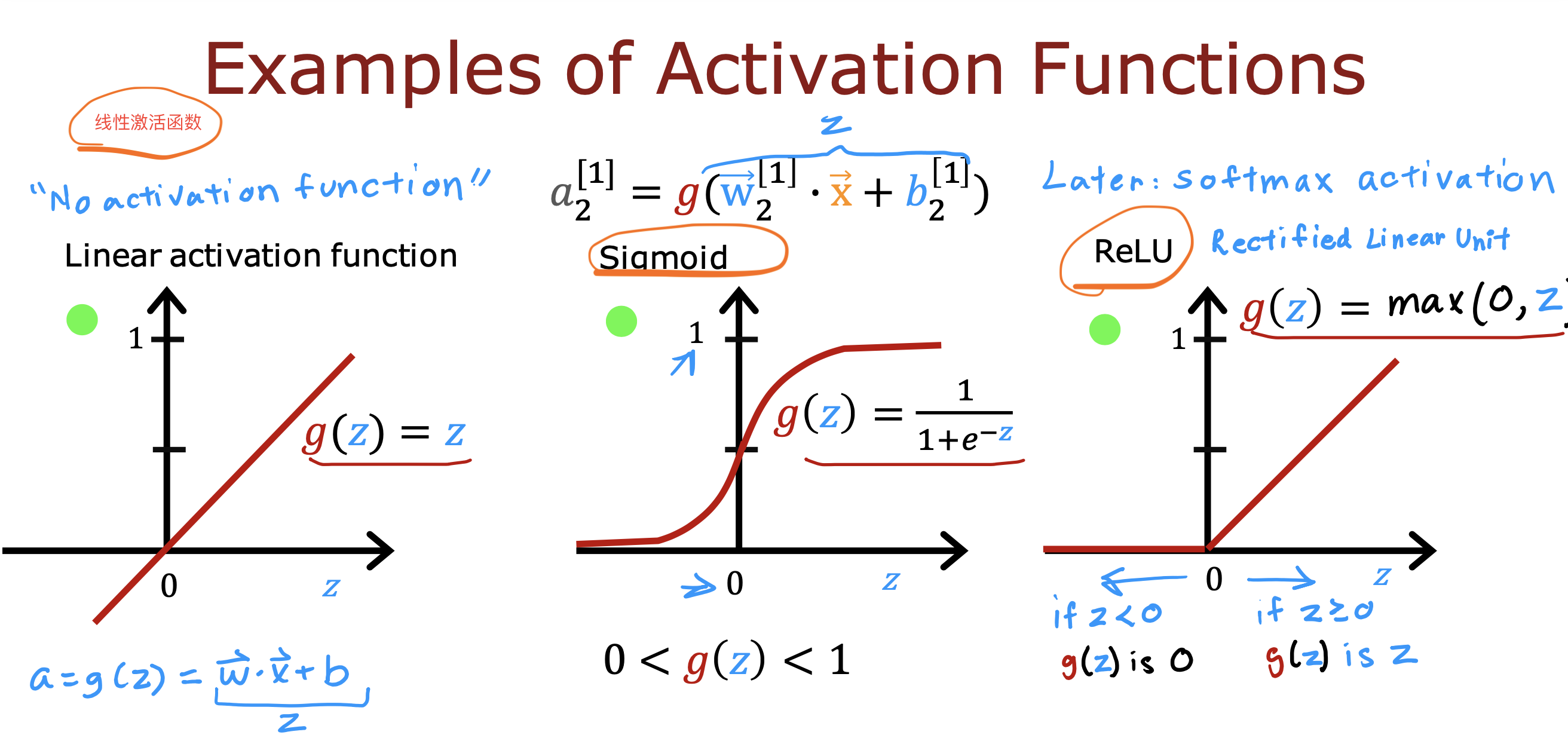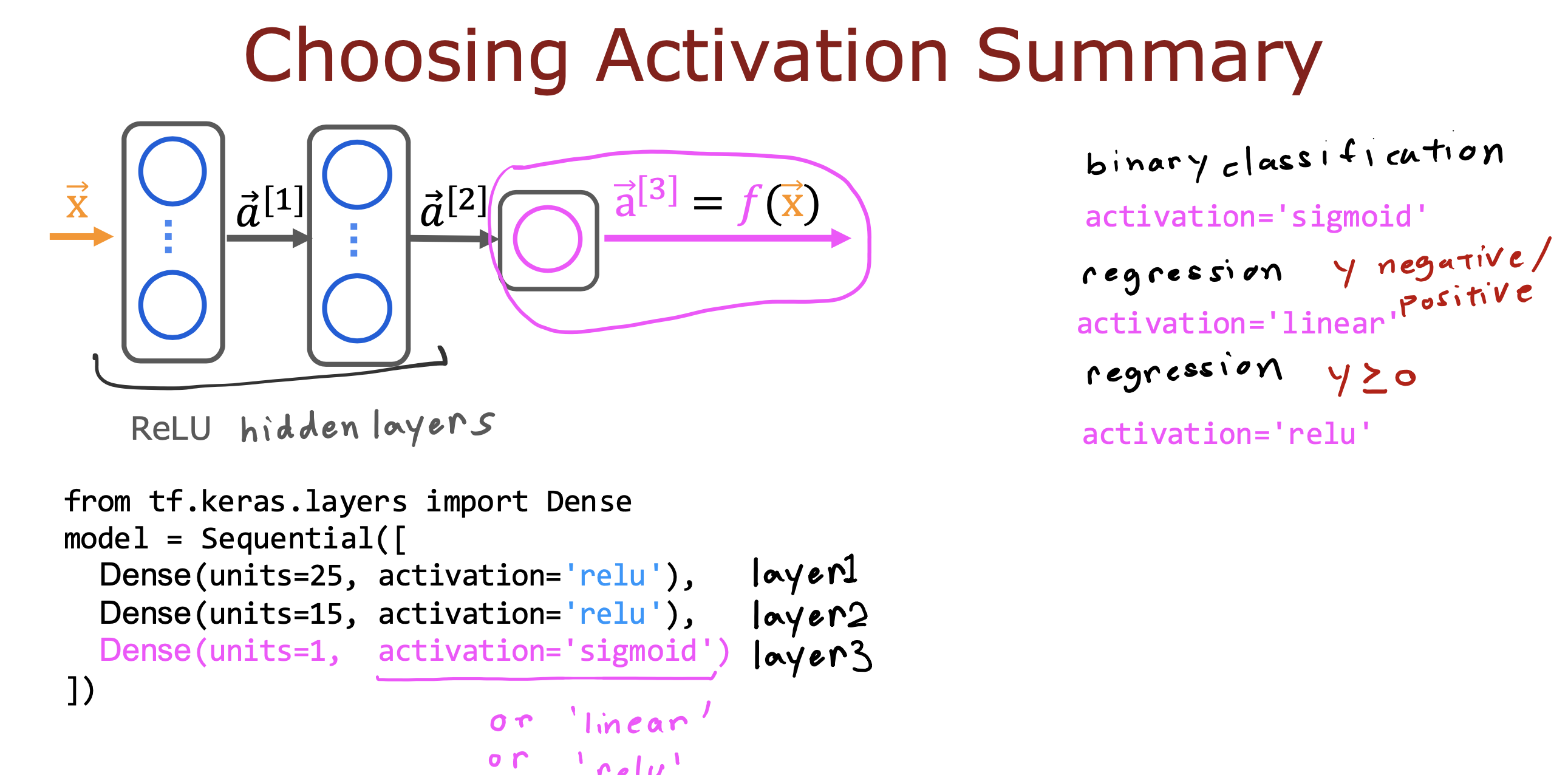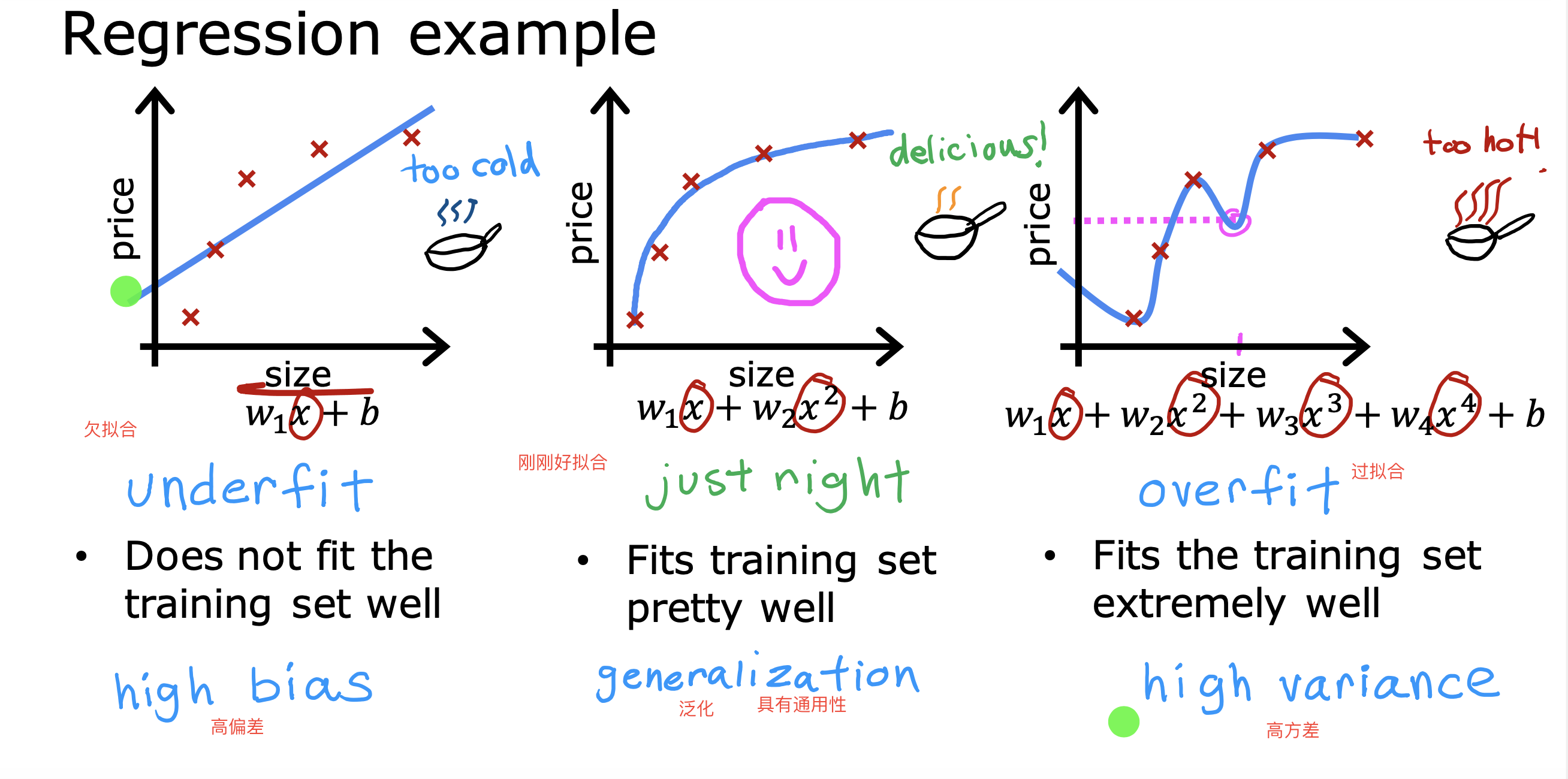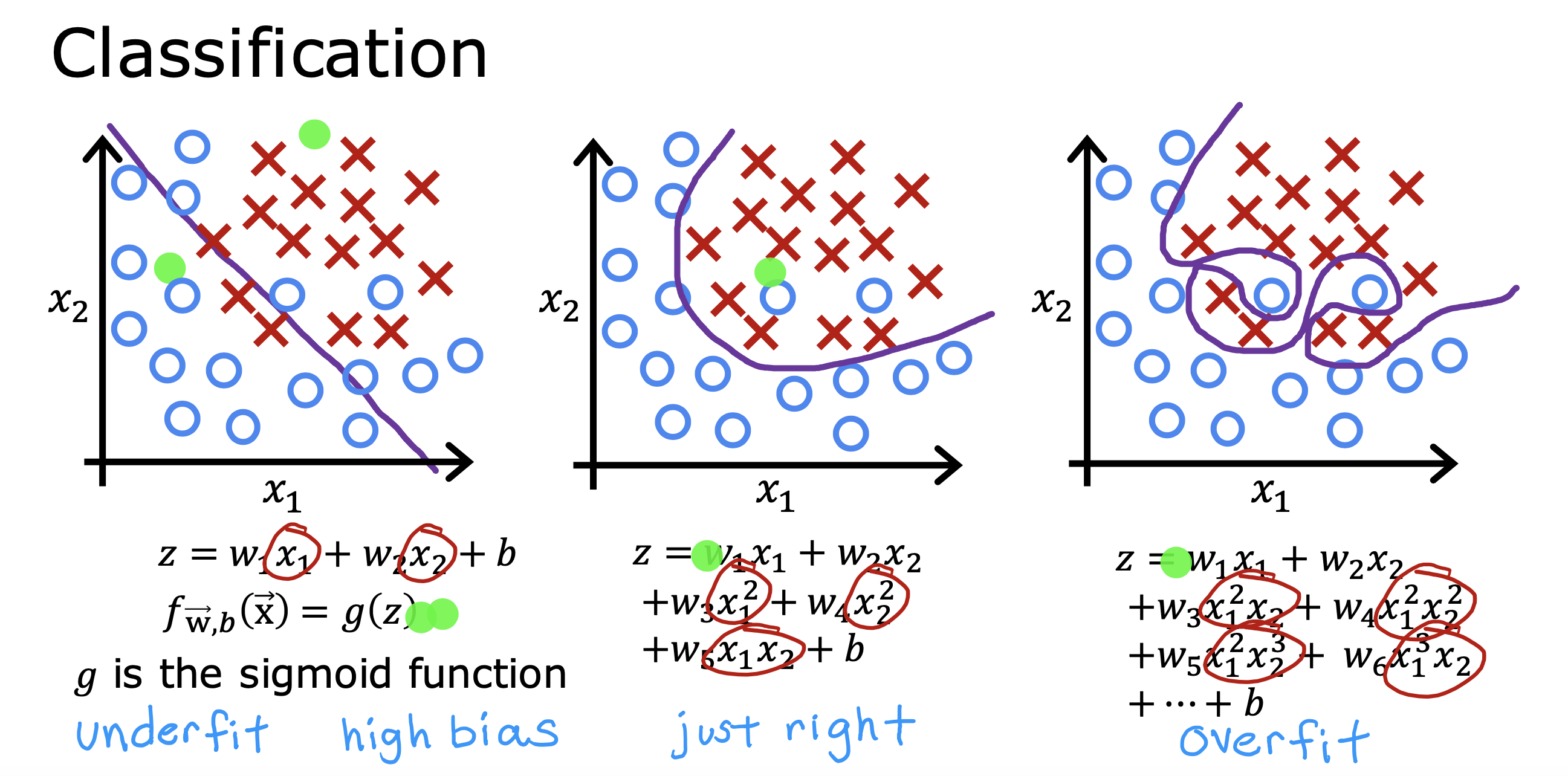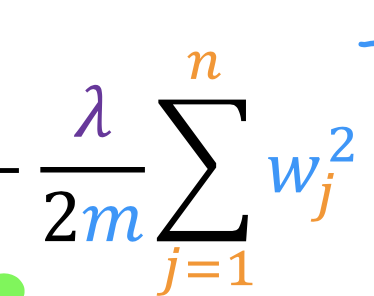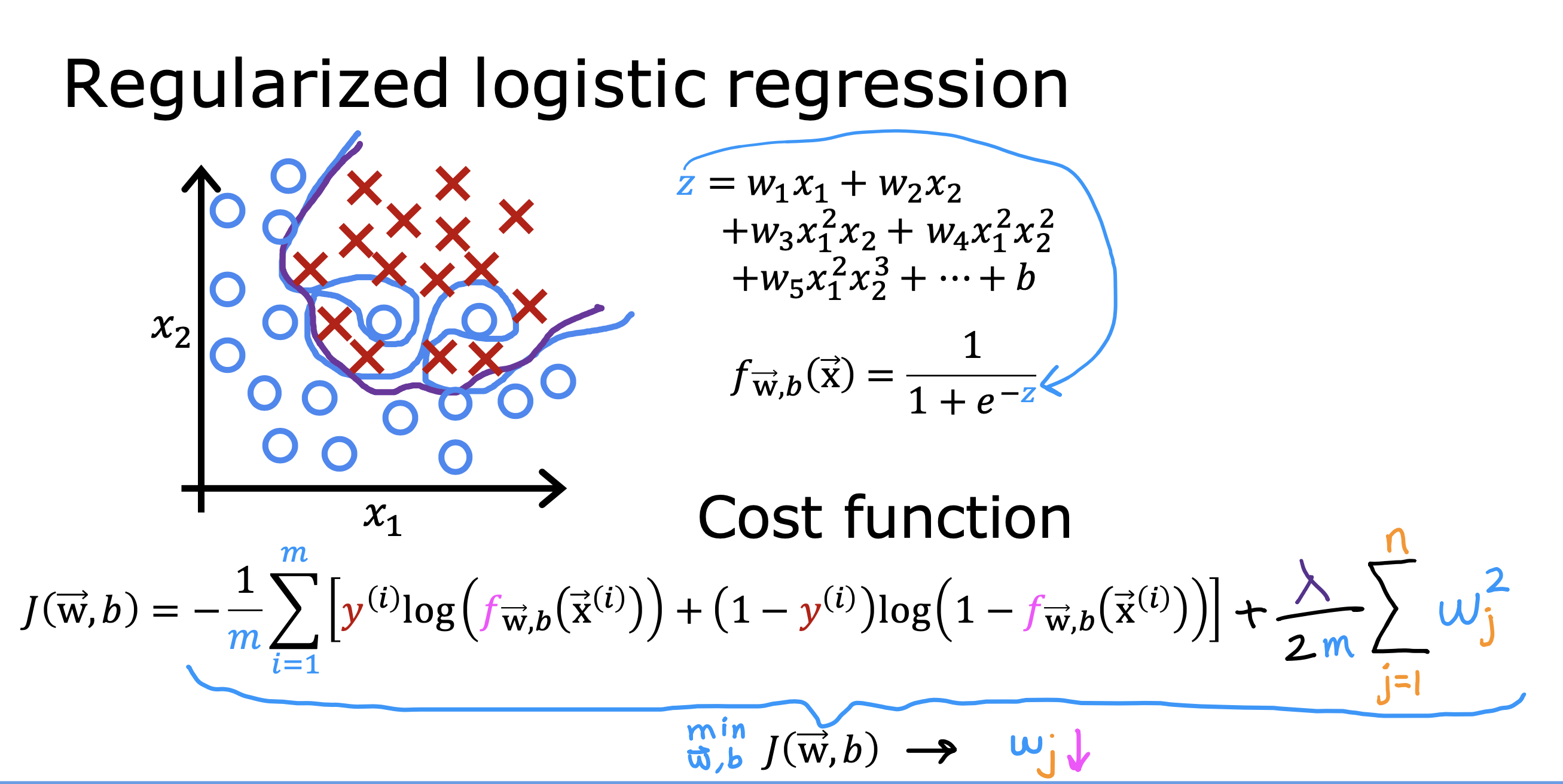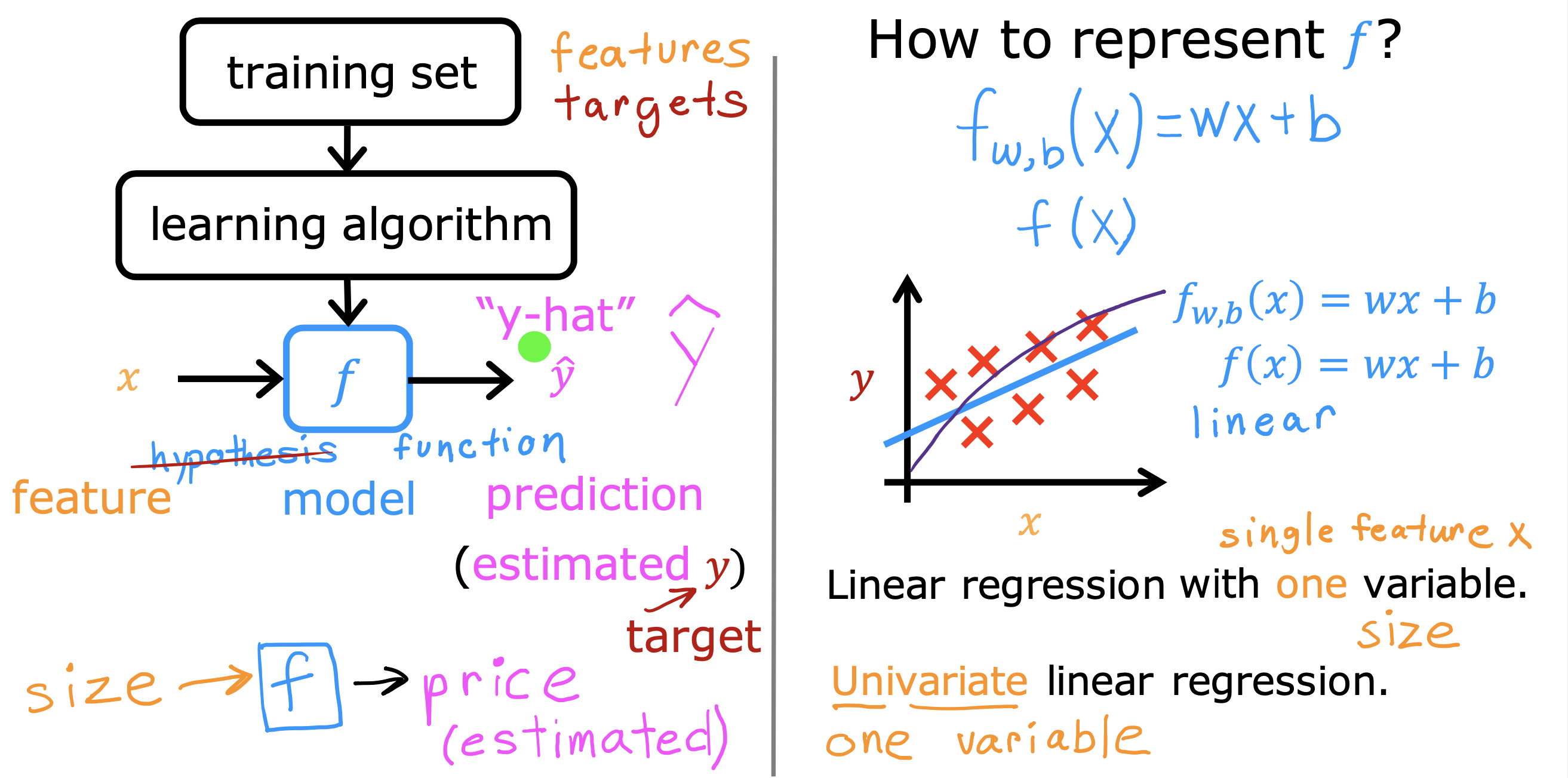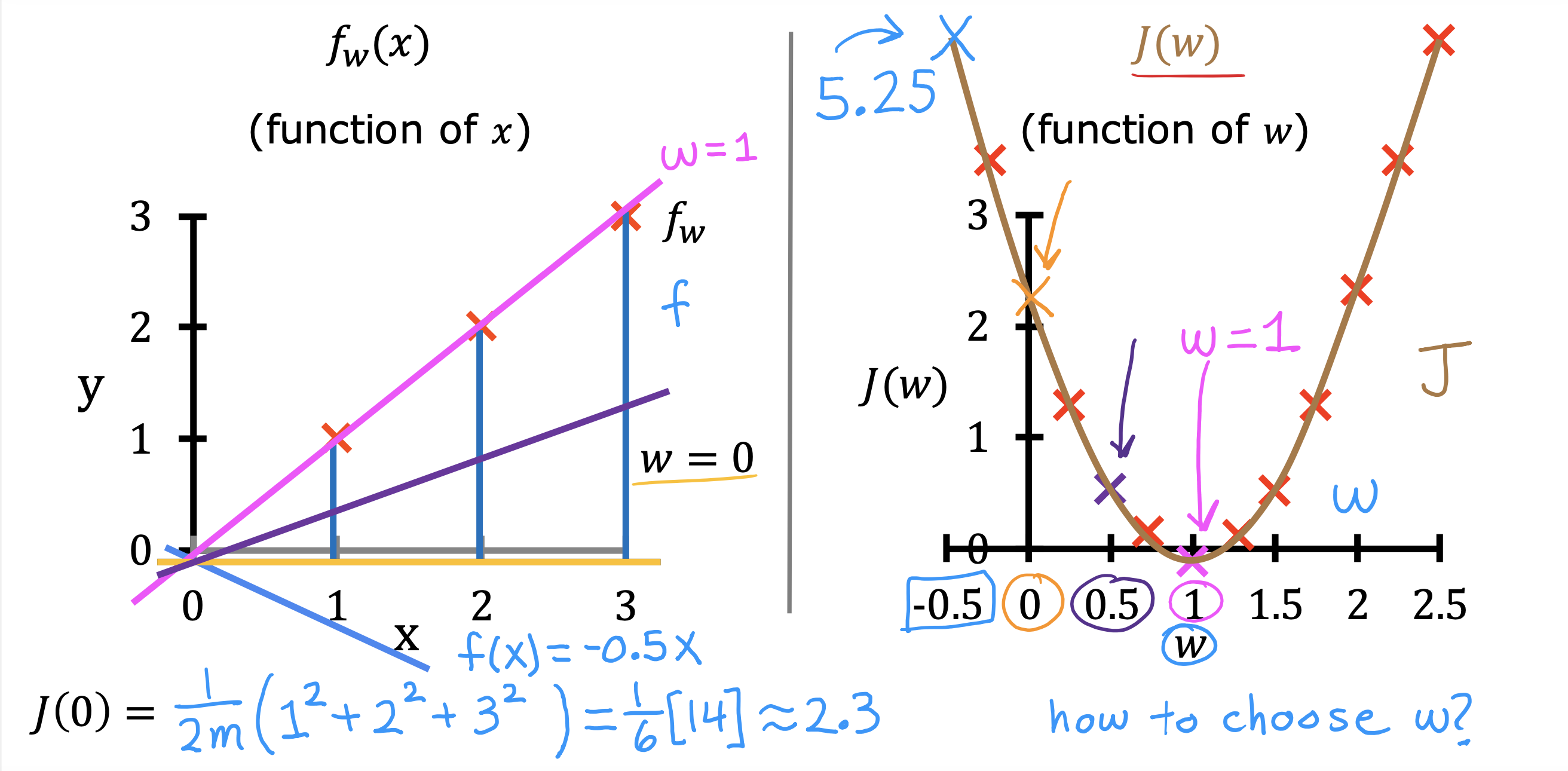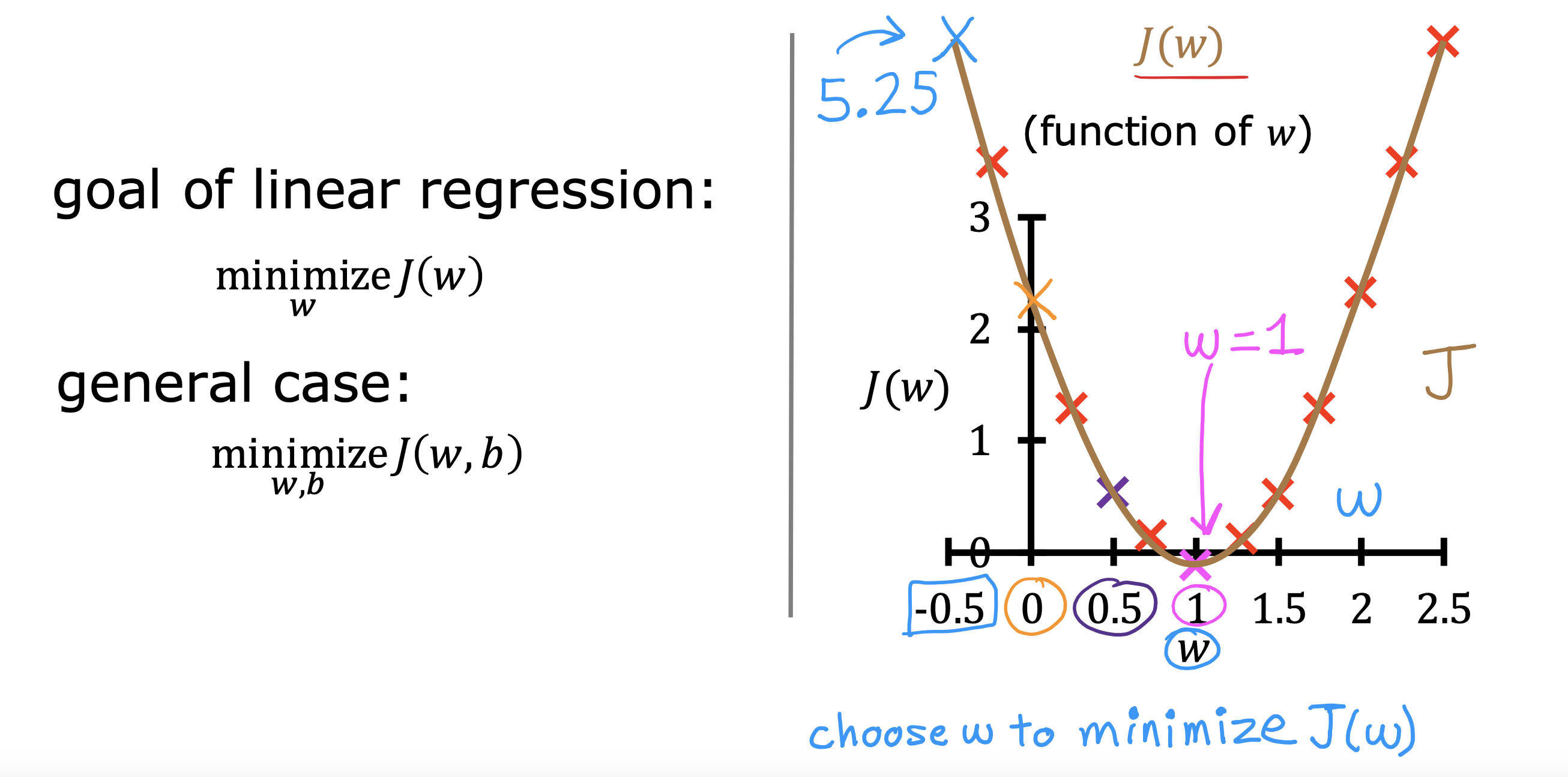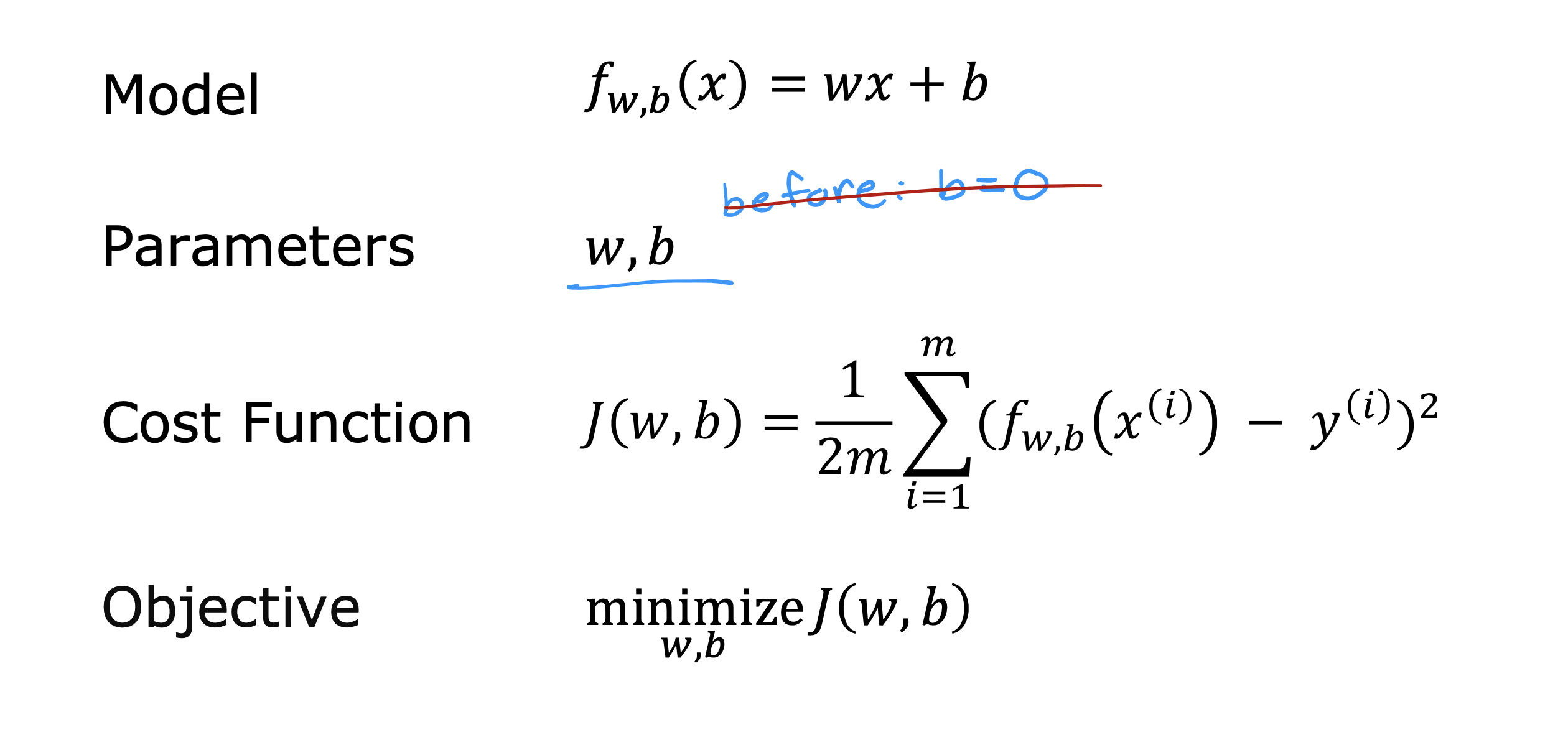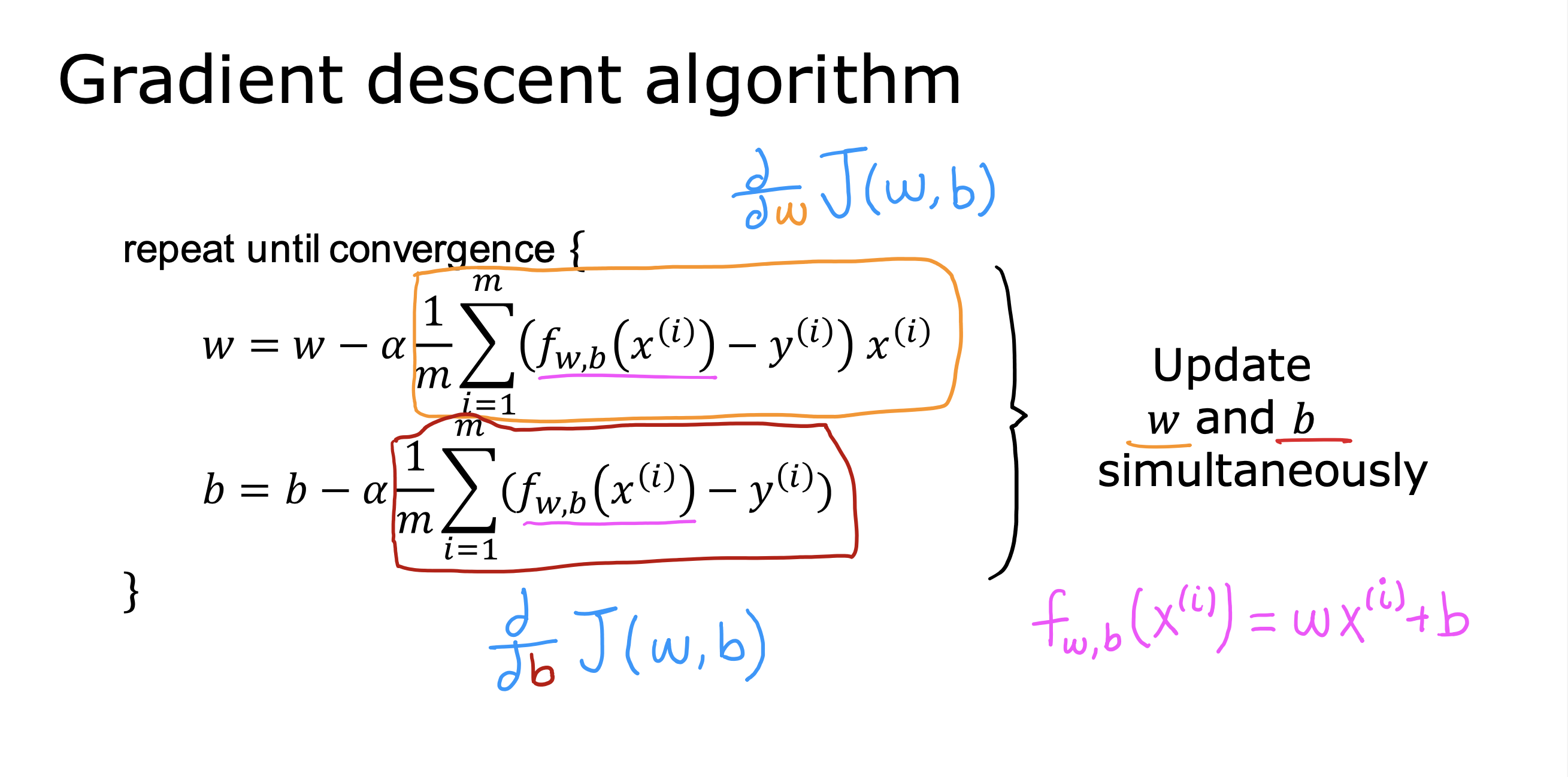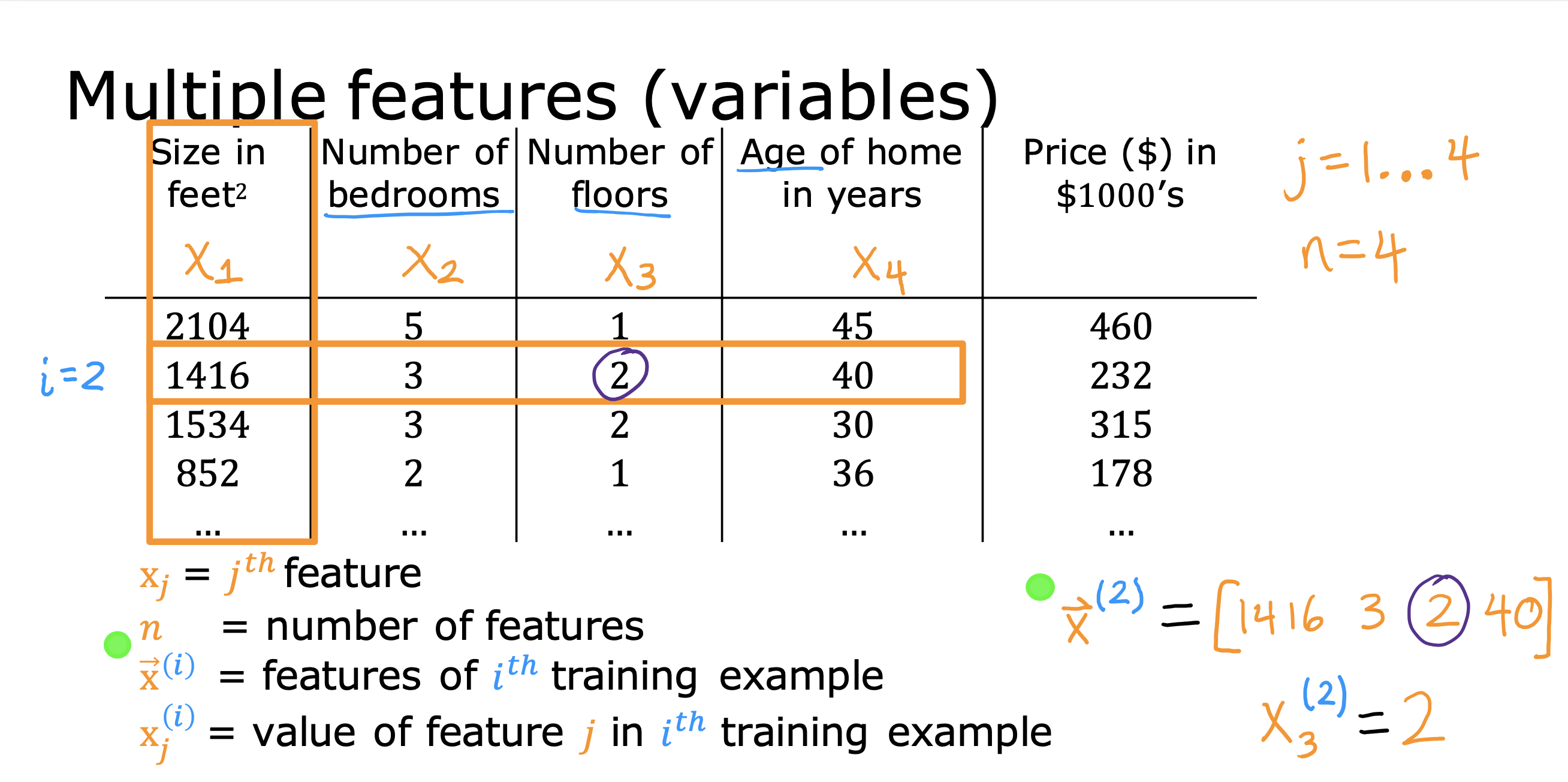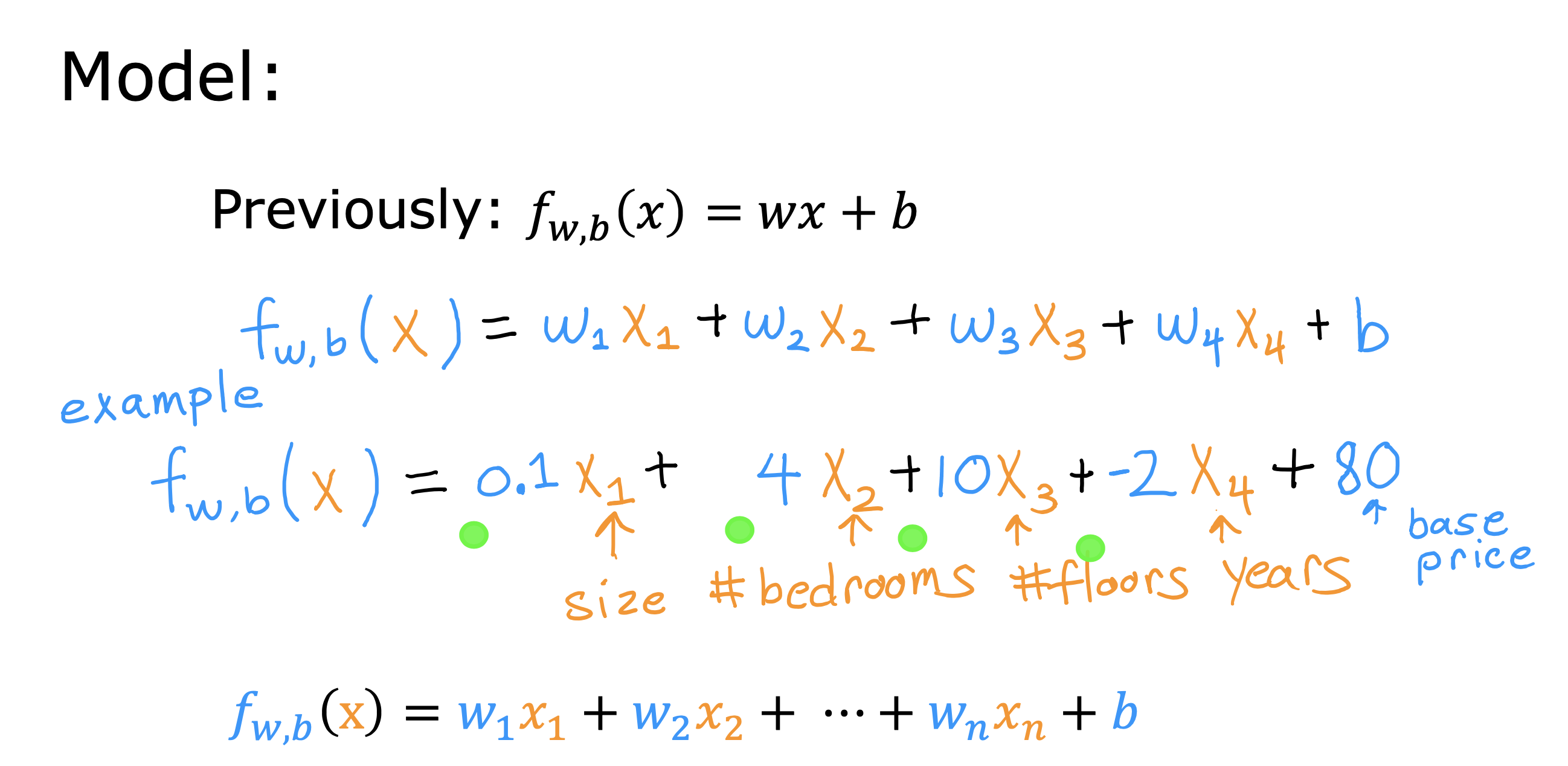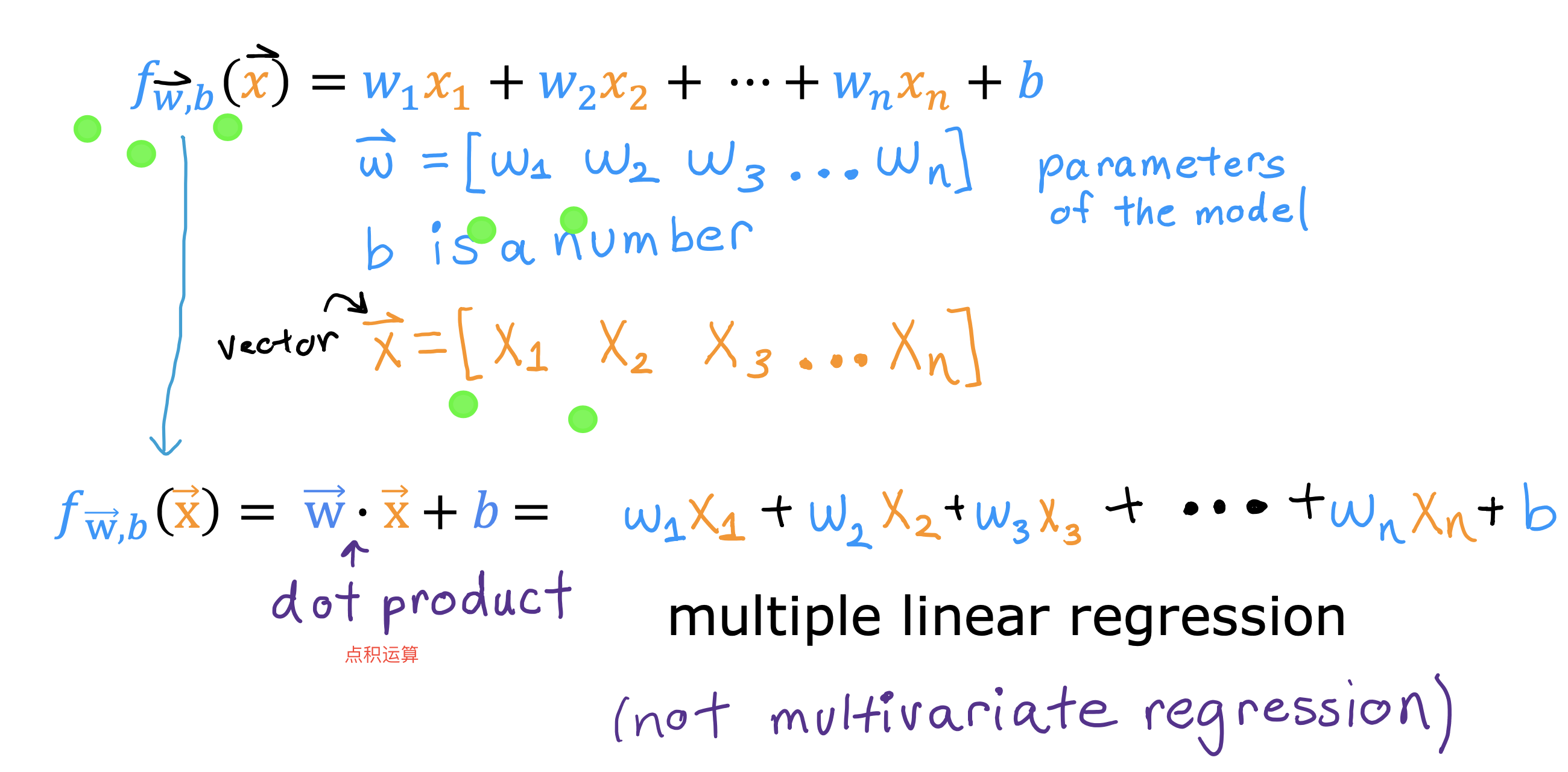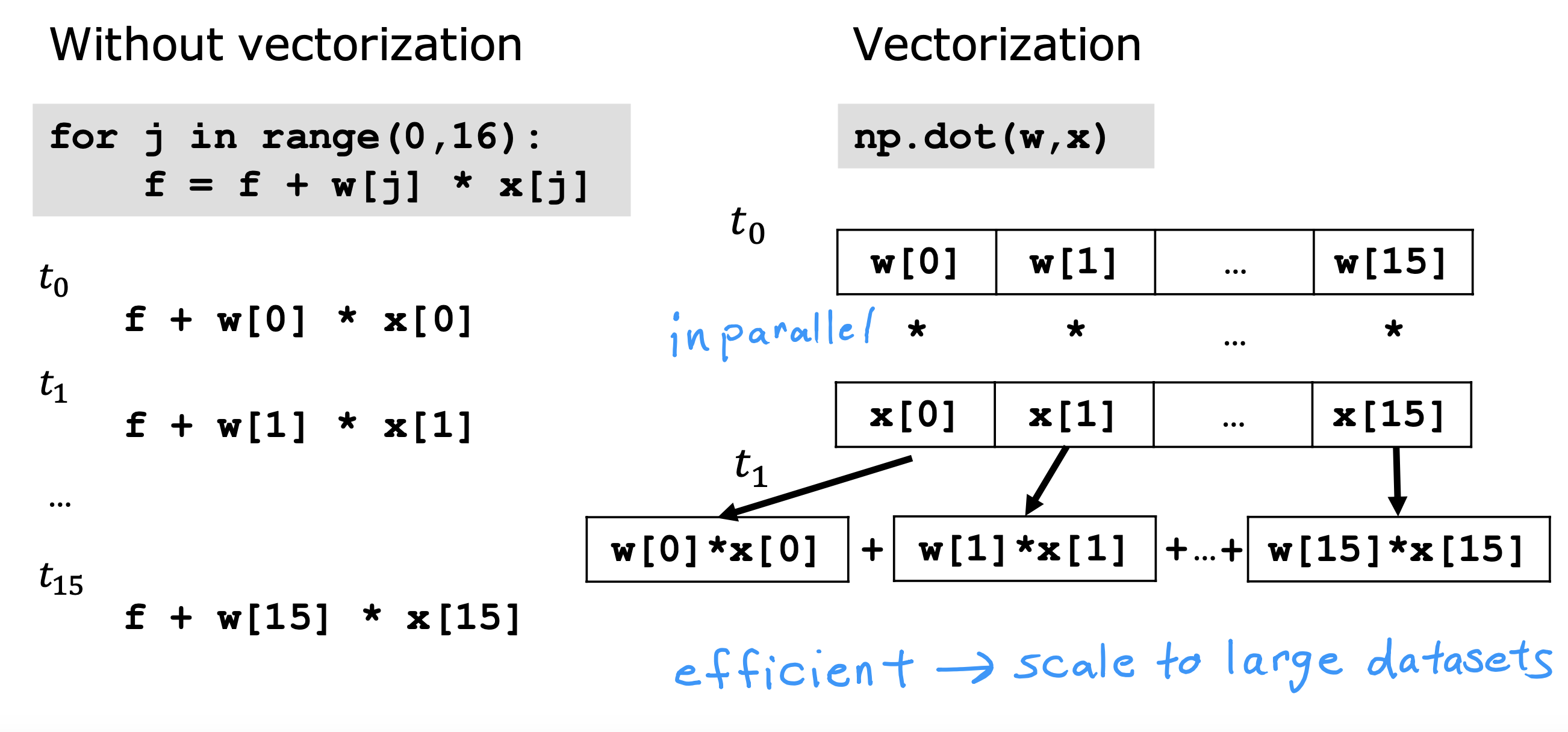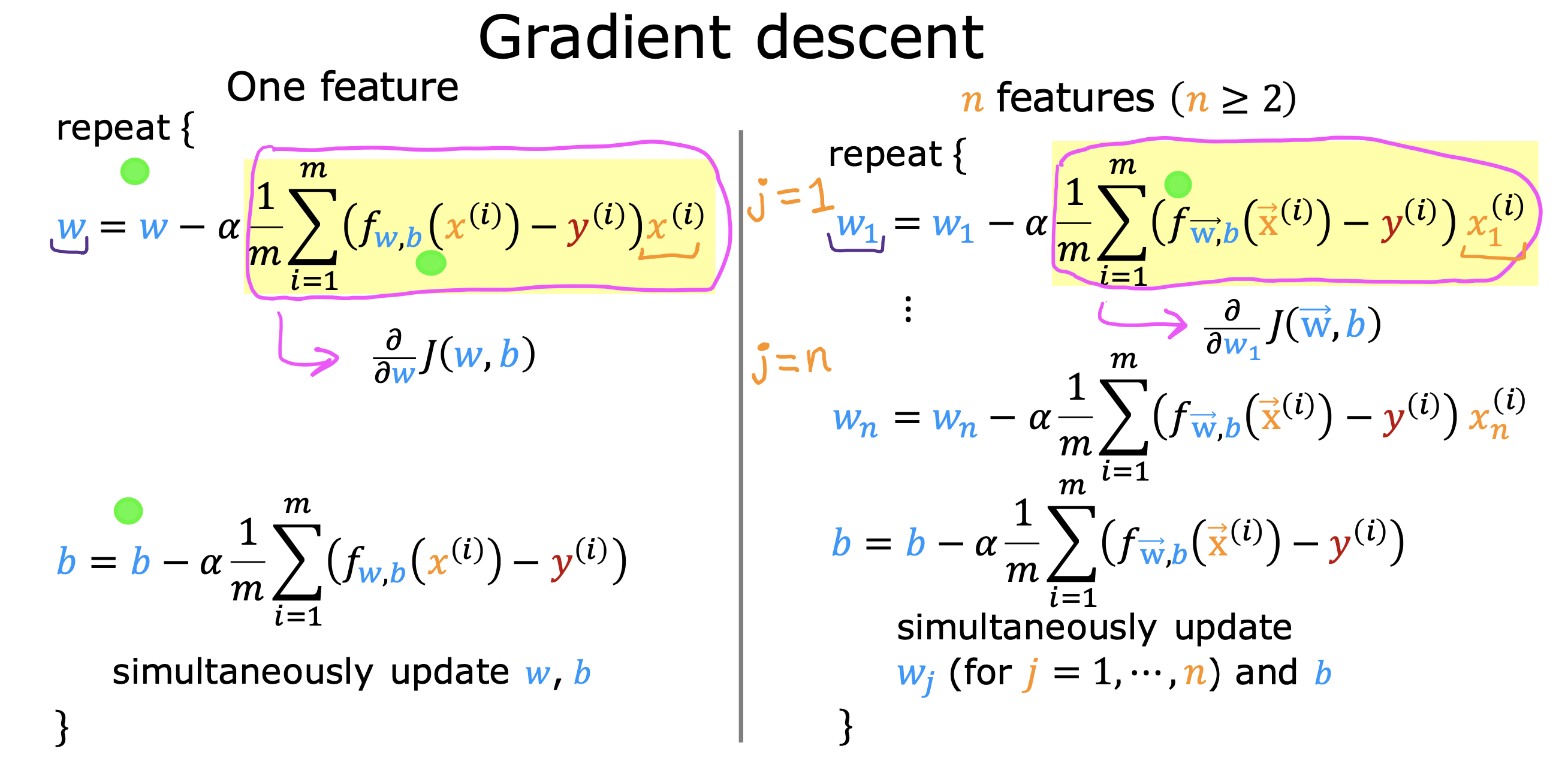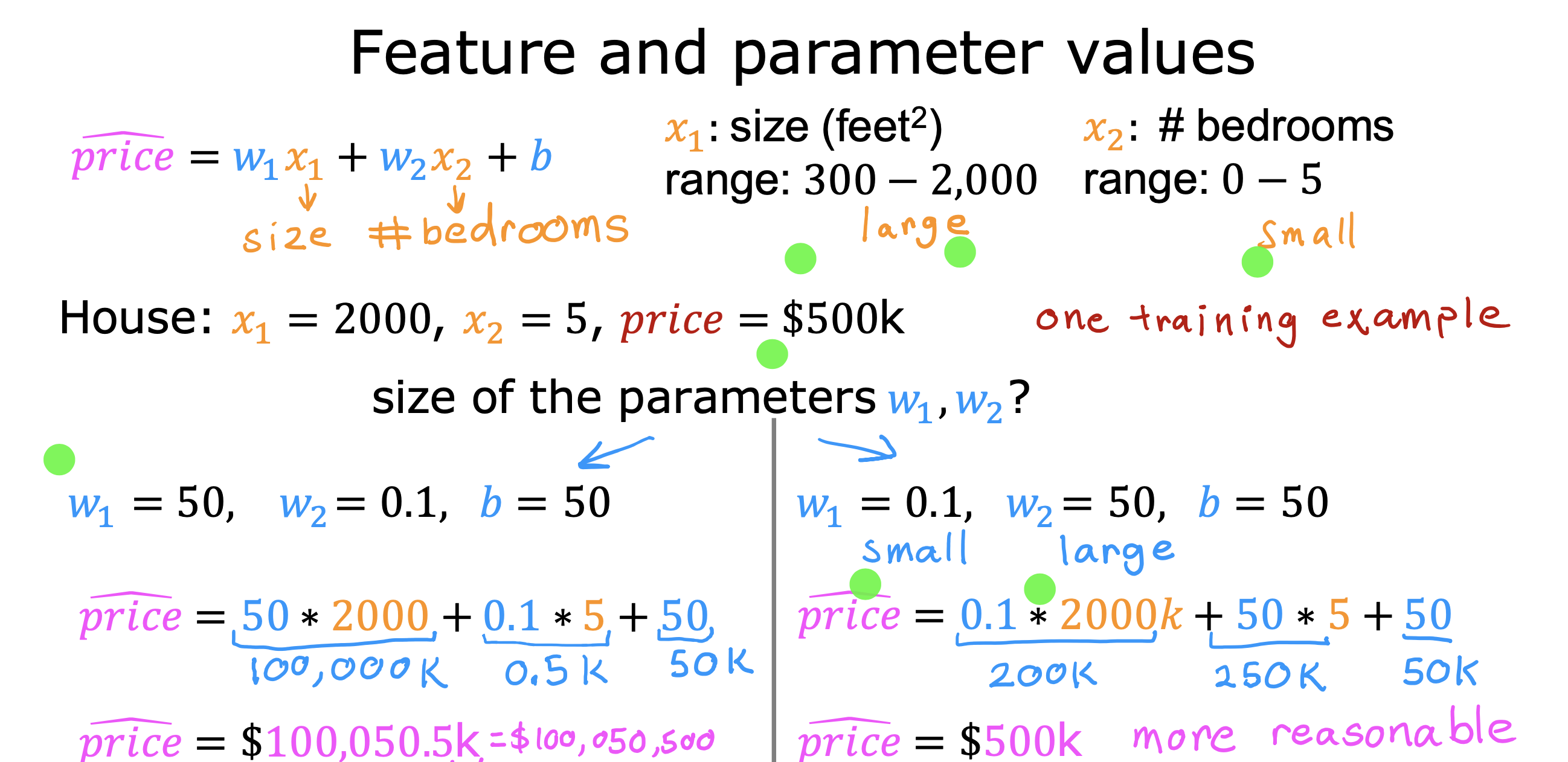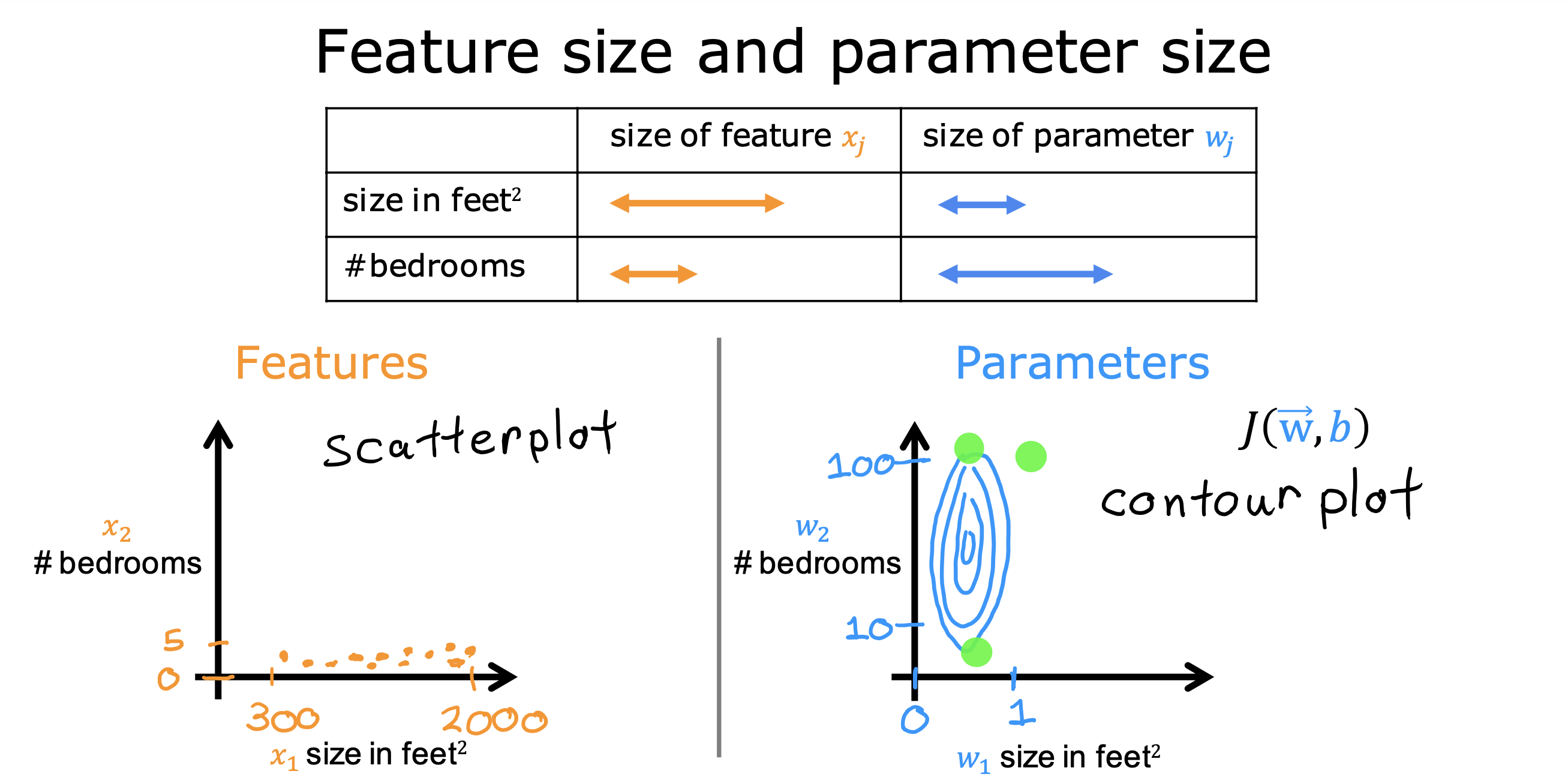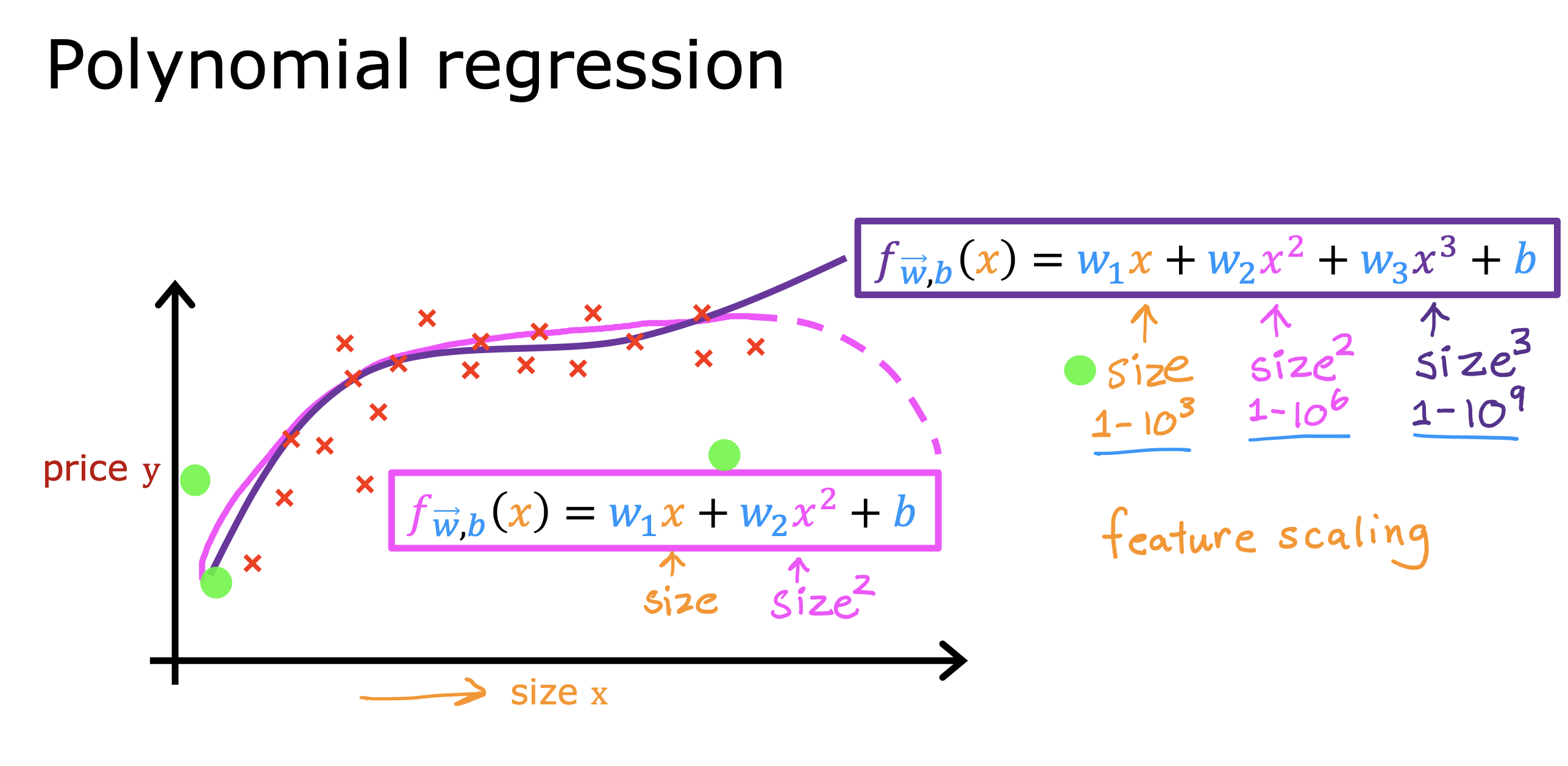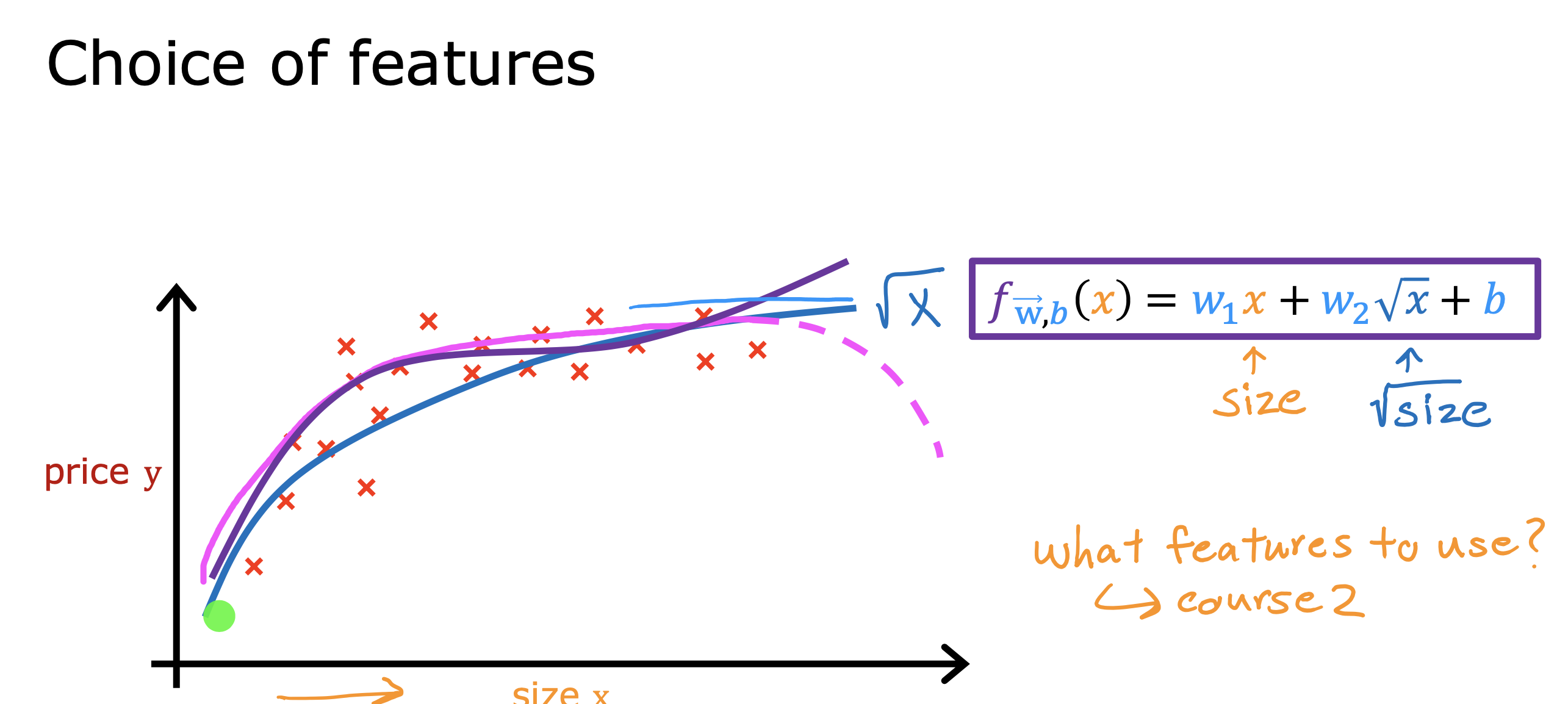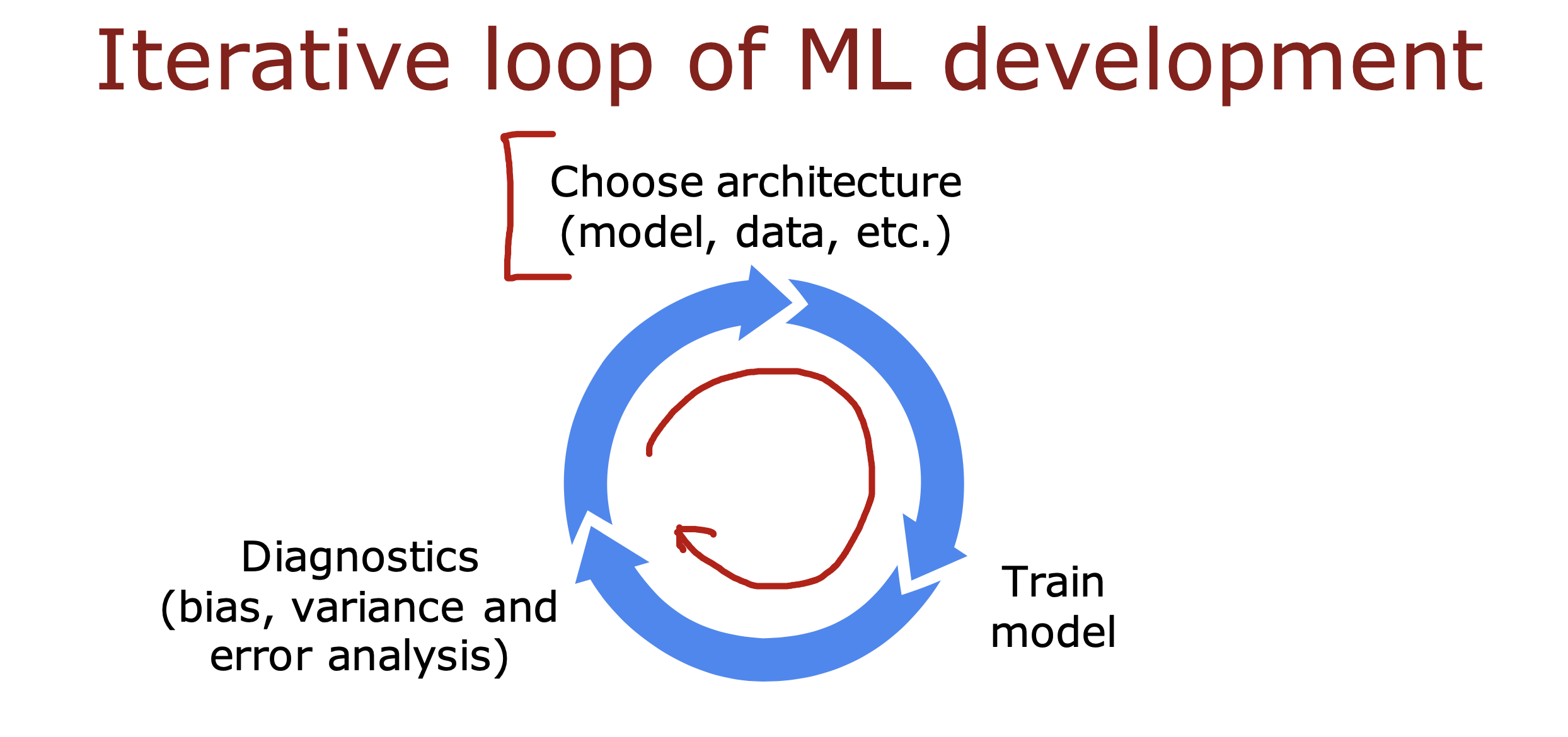
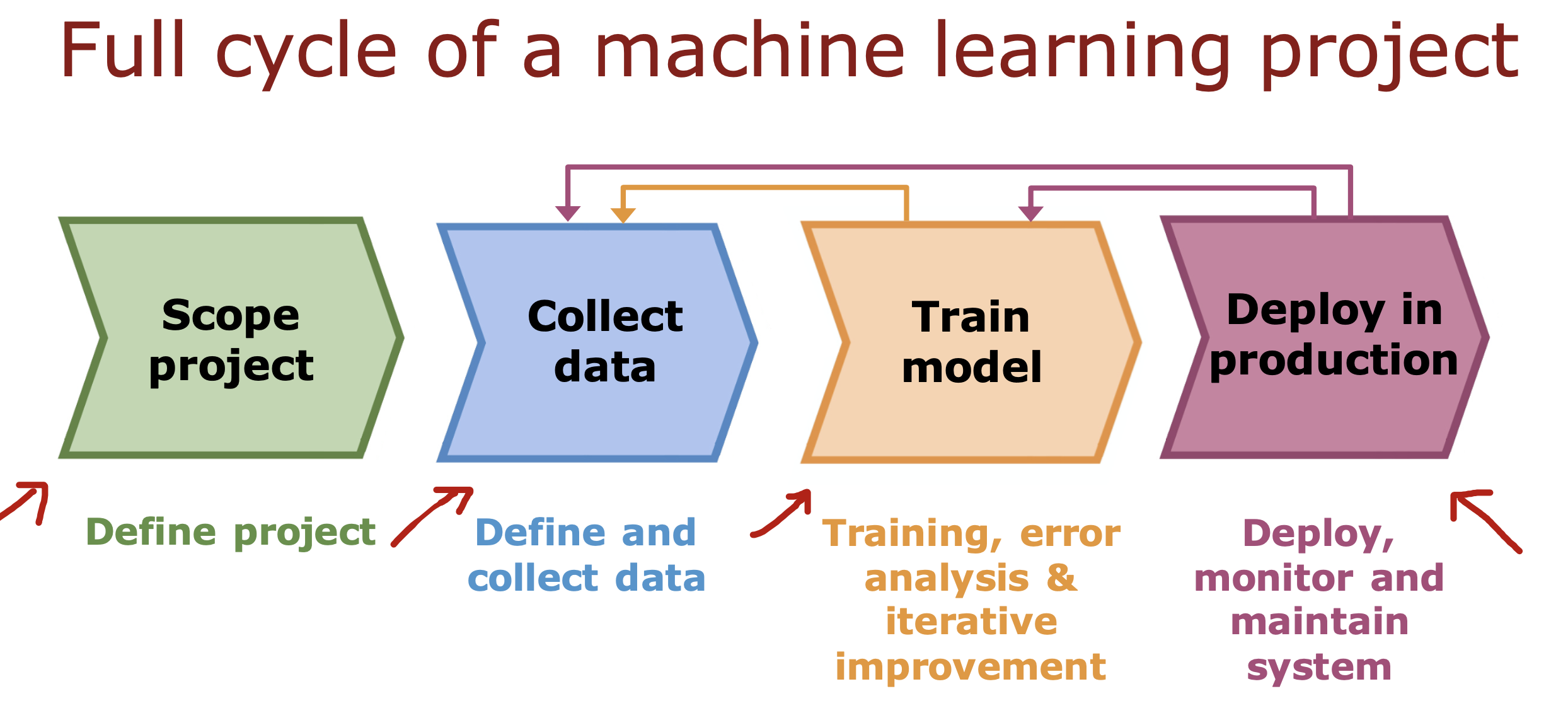
整个开发过程是一个选择框架,训练模型,诊断模型循环的过程
错误分析
除了从高偏差高误差角度对模型进行分析外,还可以对mcv 产生错误分类的角度对模型进行分析
可以从交叉验证集测试产生的错误中进行分析
通过将错误进行归类统计,找出对模型影响比例较大的错误和比例较小的错误
从而调整模型训练的方向,已解决上面遇到的问题
如果交叉验证集产生错误的数据比较庞大,可以选择进行随机抽取一定小批量的数据进行错误分类,以节省人力
添加数据
通过引入更多数据完善模型的判断,更关注通过注入的数据引发的对模型的训练结果的影响
数据增强
Augmentation: modifying an existing training example to create a new training example.
在原有数据基础上,通过添加特定种类的噪声,形成新的测试数据,从而完善特定种类的错误判断
对于图片和音频数据都适用
但是对添加随机或者无意义噪声产生的数据进行训练,对于模型训练不会有多大帮助
数据合成
Synthesis: using artificial data inputs to create a new training example.
直接由计算机合成训练过程中使用的数据,通常用于计算机视觉训练的场景
迁移学习
在已有大模型训练结果基础上,通过修改输出层结果使之符合自己使用场景的训练方法
好处是,在数据有限的情况下,可以直接使用输出层之前的参数开始训练,减少自己从头开始训练的工作
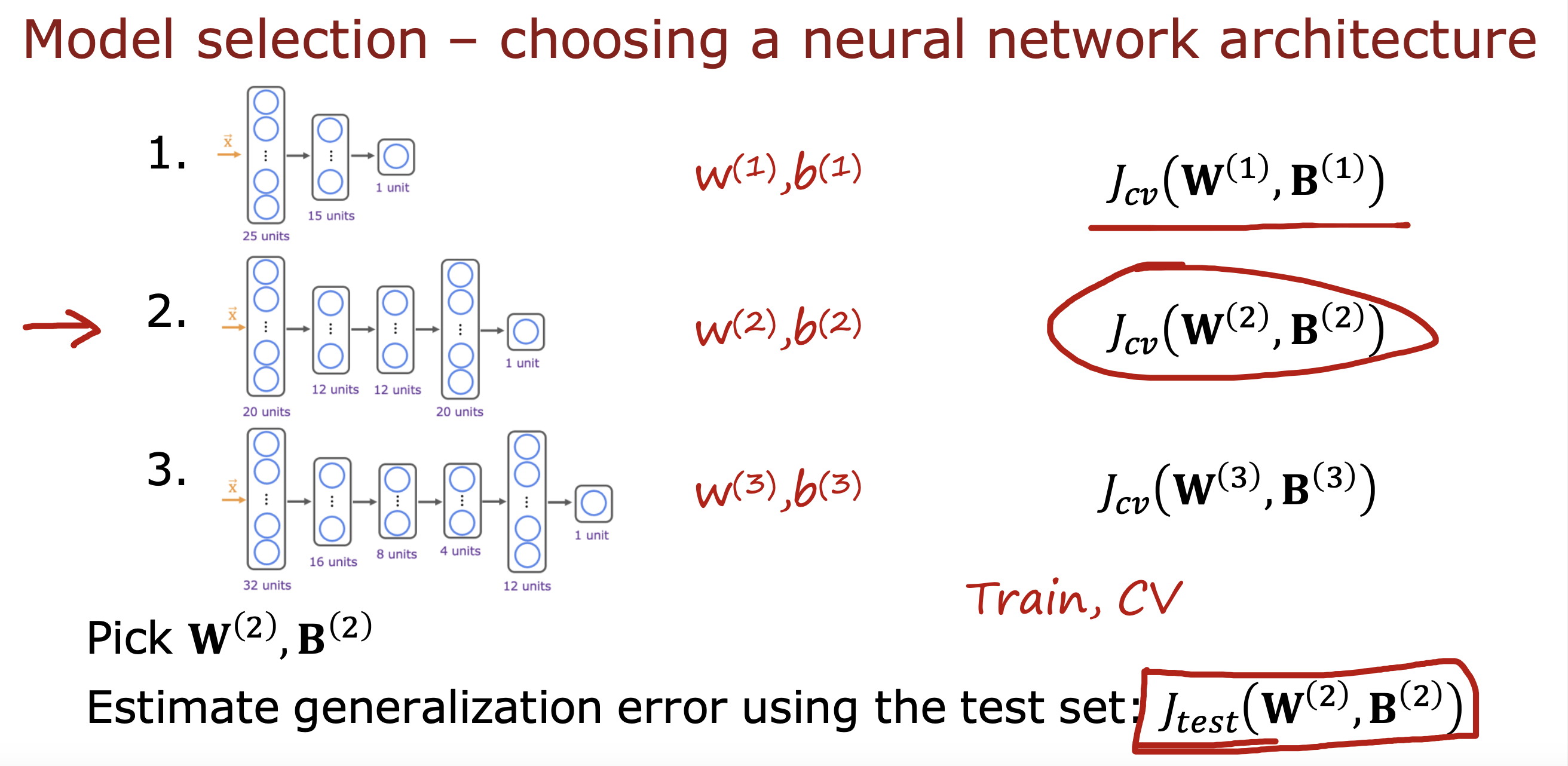
例如下面这个使用1000+分类的训练识别数字0-9的模型,只是在输出层将1000+ 输出改成10种输出,在此基础上开始训练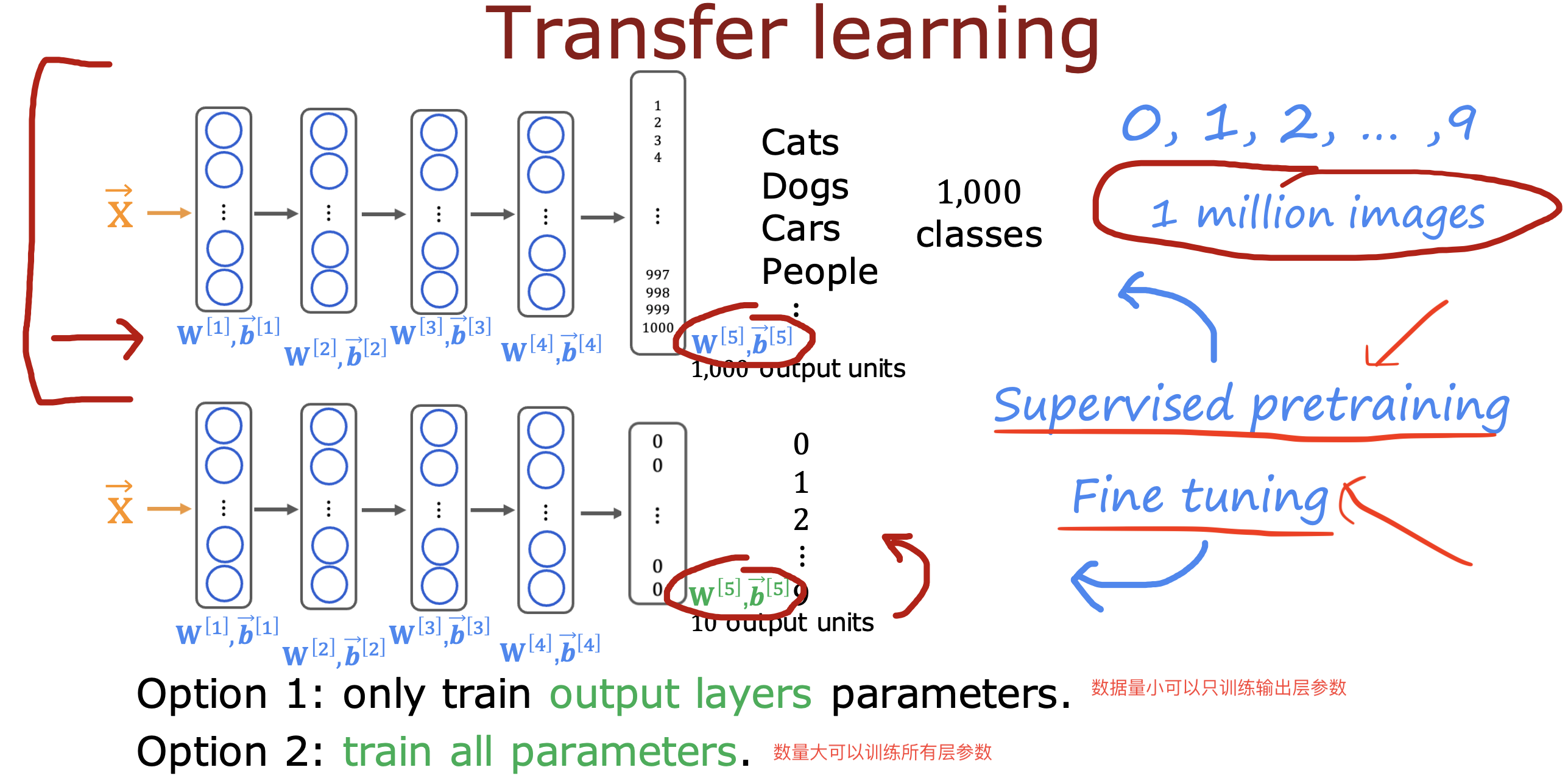
一般训练步骤为下载相同输入(文本的下载文本的,音视频的下载音视频的)的预训练模型,然后用自己的数据进行训练(fine tuning)
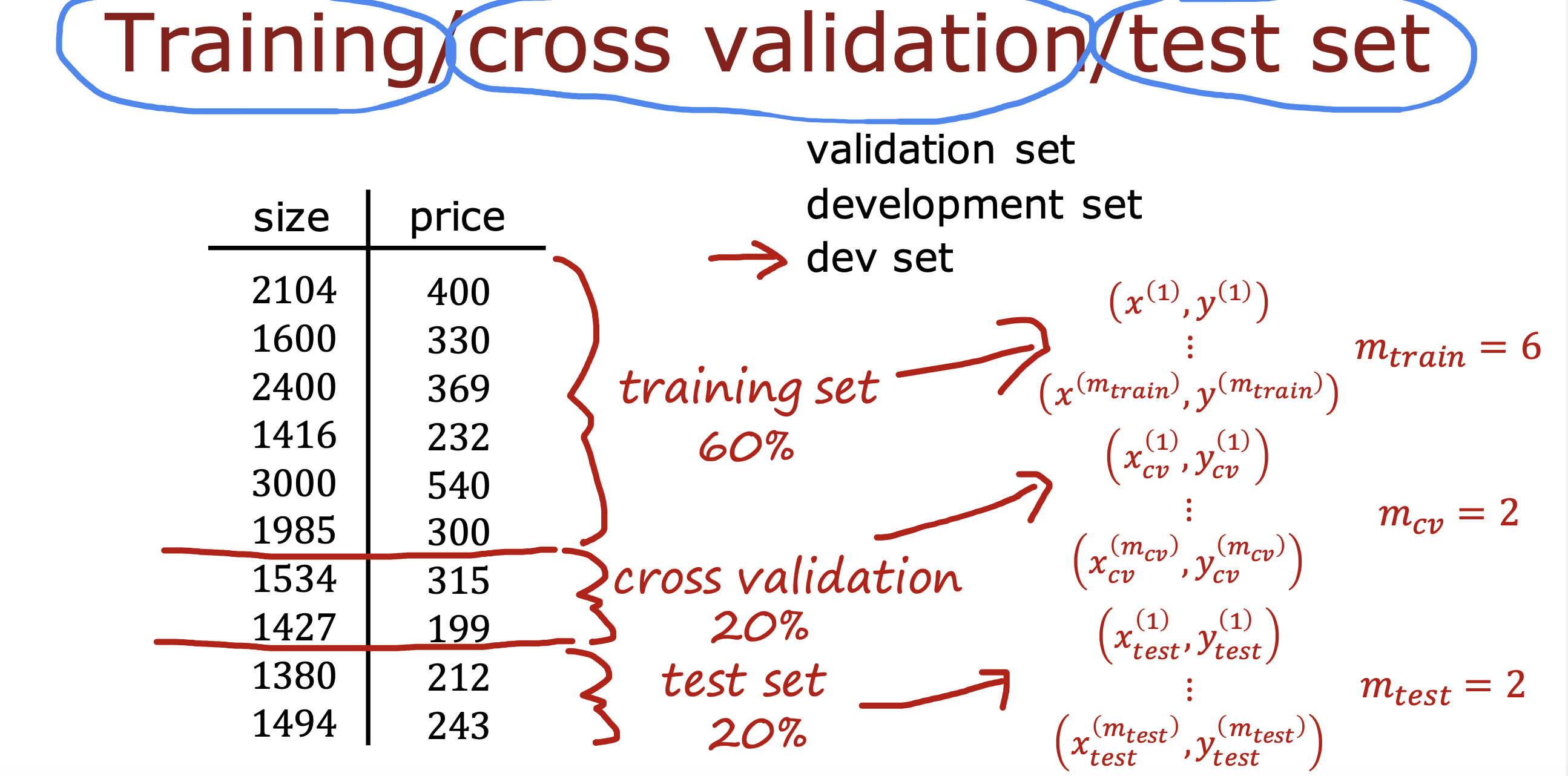
完整开发流程
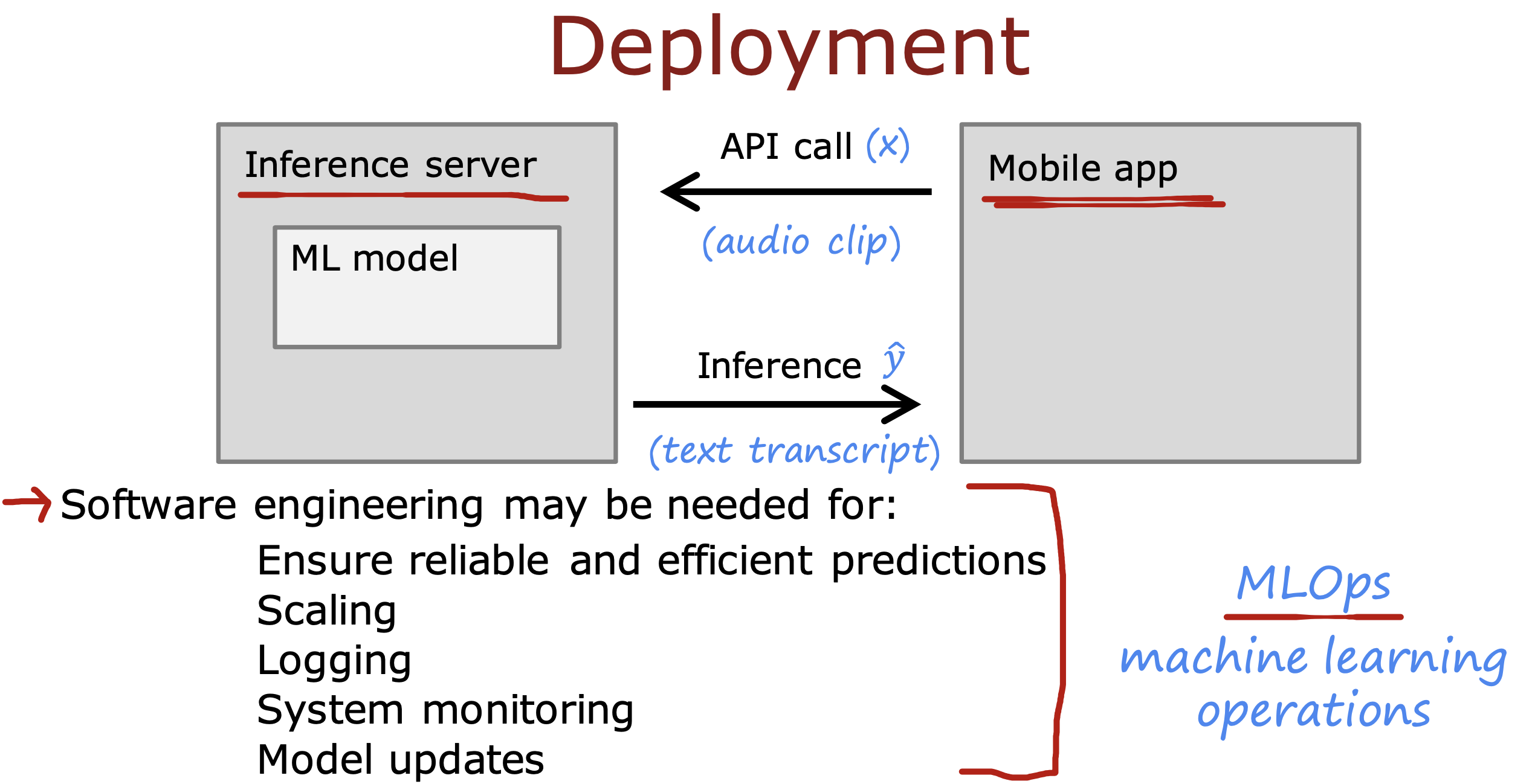
部署阶段
通常应用层跟模型通过Api 进行通信,用户输入x, 模型返回预测值y^
软件工程师需要注意
- 尽可能的保障低成本的计算出具有可靠性和有效性的预测结果
- 可以进行大规模用户扩展使用
- 在用户隐私允许同意的情况下进行日志记录输入和输出
- 对模型进行系统监控,比如根据上面日志的记录,计算出因为当前数据变化导致计算结果不准时,判断是否让模型进行进一步优化
- 保障模型更新,在上一步进行模型优化后要保证能够将老的模型替换成新模型
避免道德偏见伦理问题
- 建议多元化(多背景,多种族)团队,上线前进行头脑风暴,探索可能对弱势群体造成伤害的可能
- 参考行业标准
- 上线前通过技术诊断产生的伤害可能性,从而决策是否可以上线
- 制定延缓计划,上线后观测可能产生的伤害,及时进行回滚处理

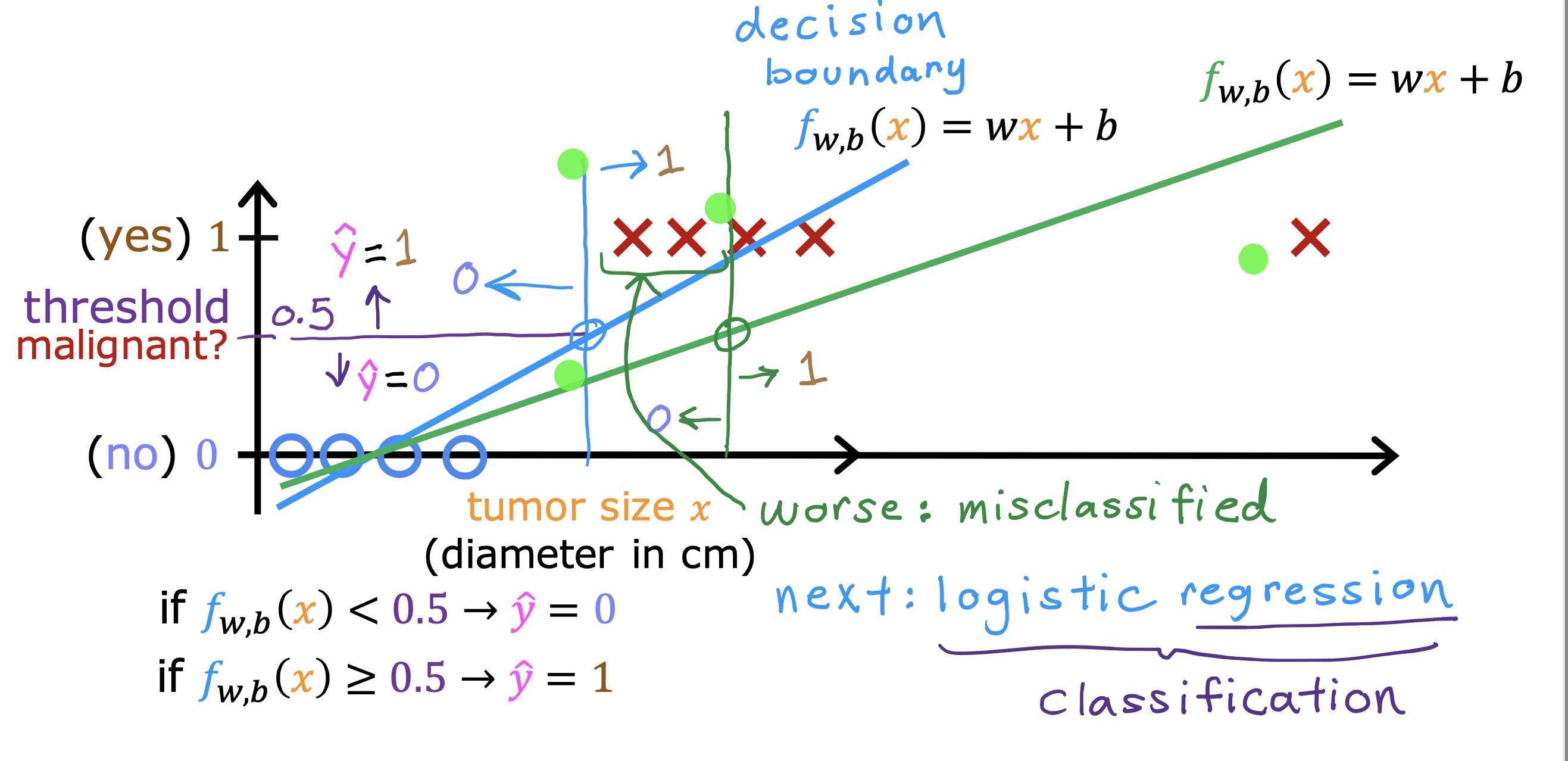
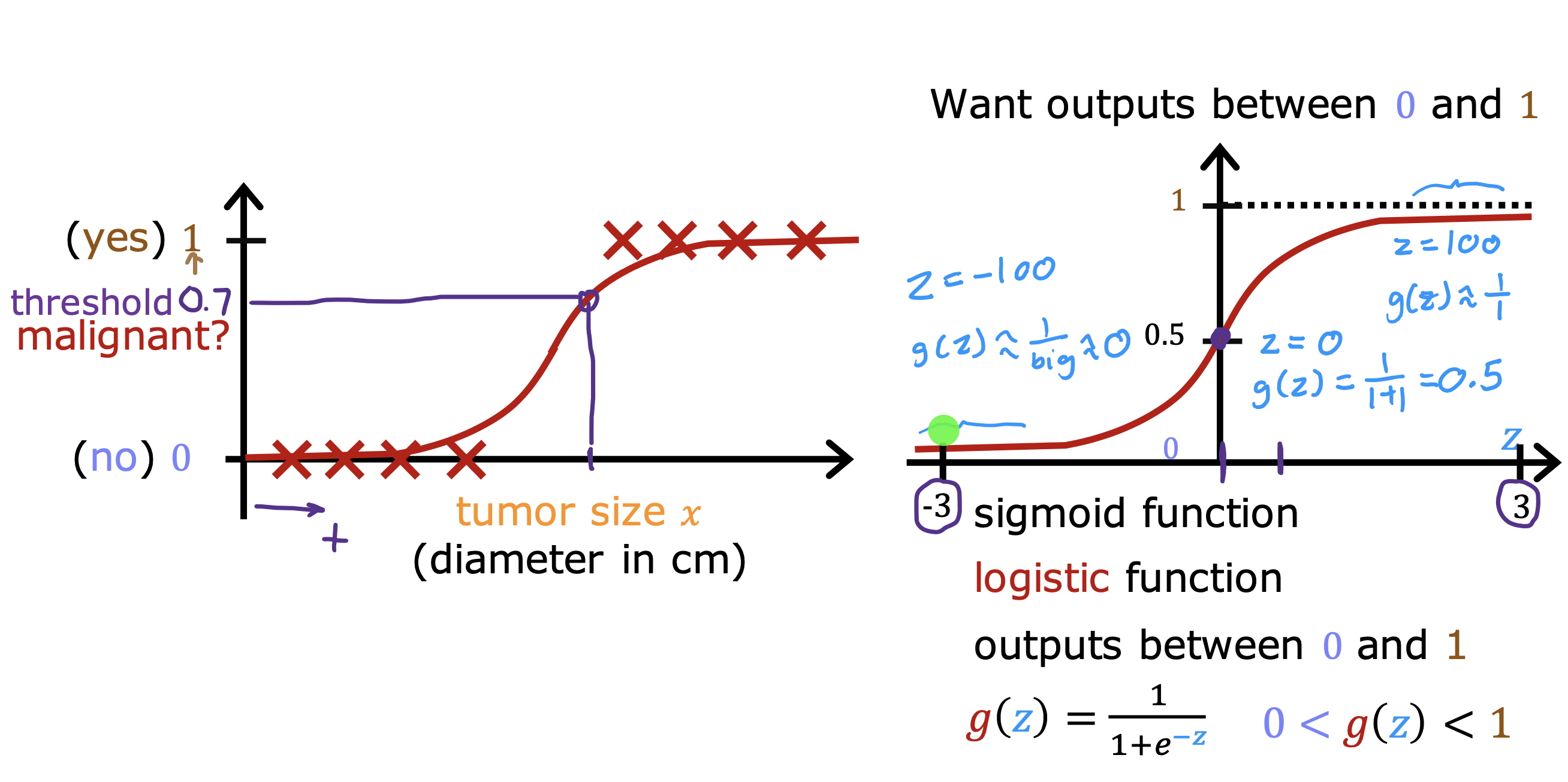
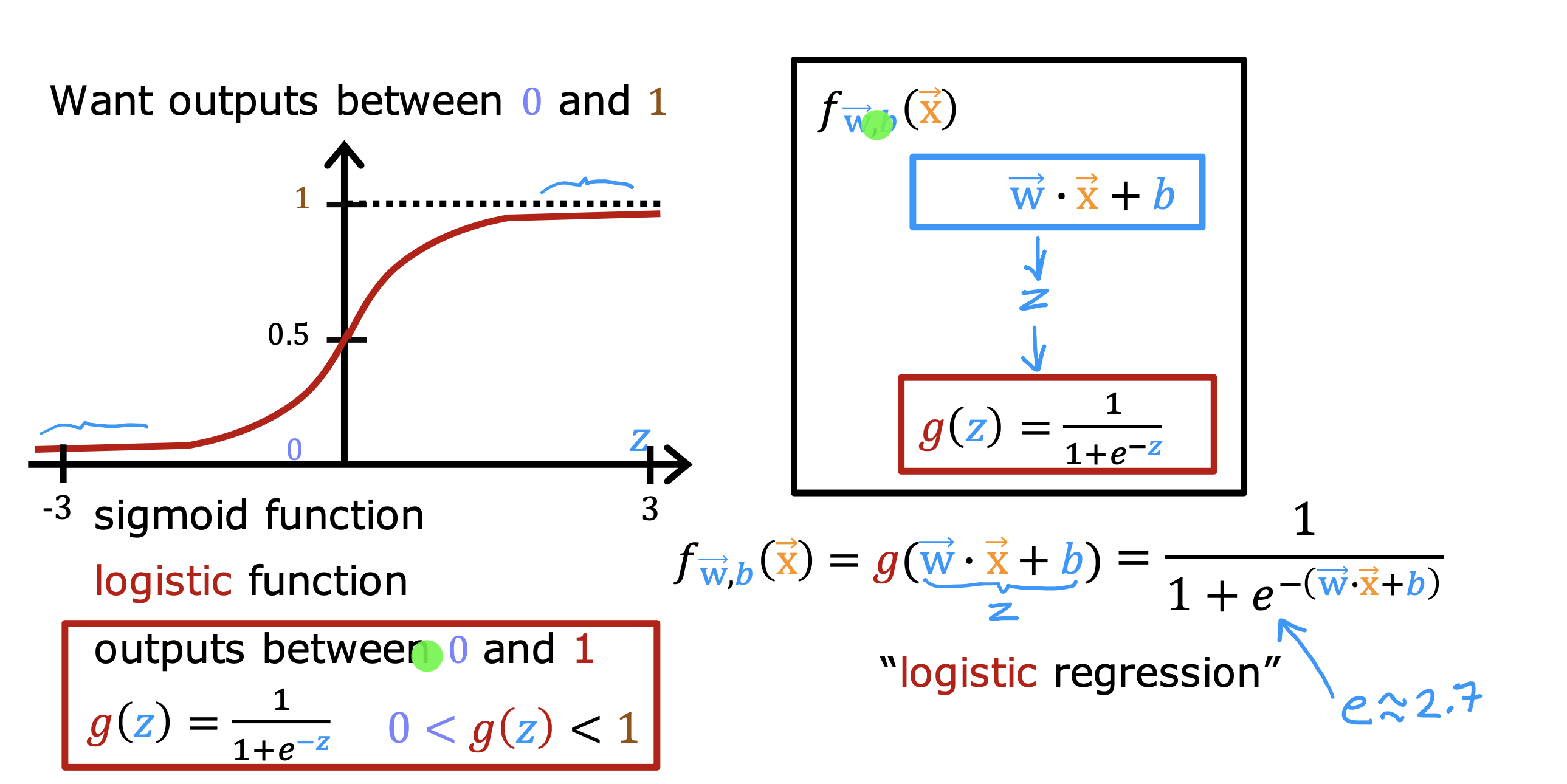
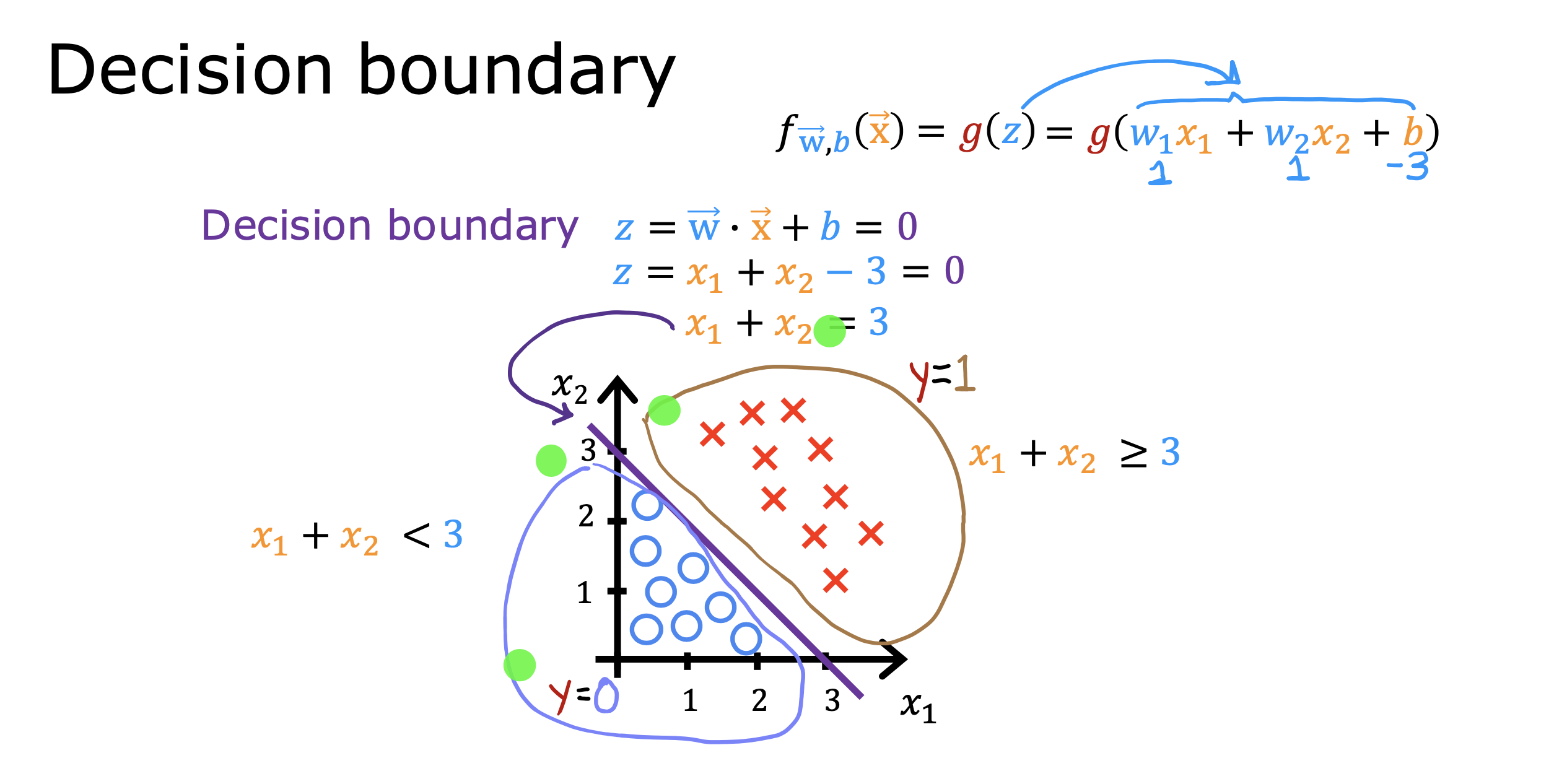
二分类错误度量
在对倾斜数据集(y=1 和y = 0 所占比例不是5:5)进行训练时,
判断模型预测结果好坏通常交叉验证集的数据计算精确率和召回率两个指标衡量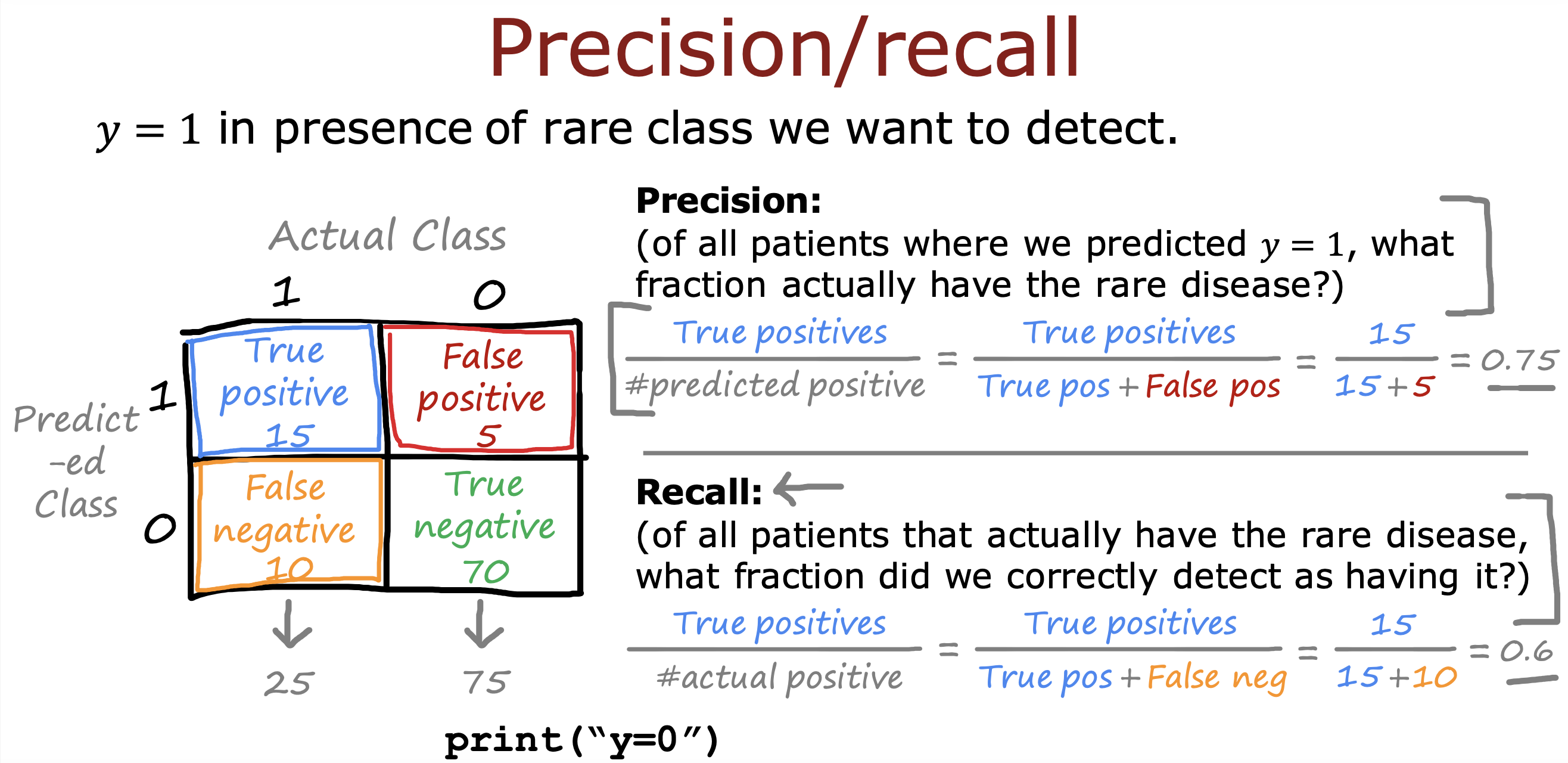
如果二者都趋近0或1时,说明当前的模型不是一个有用的模型,一直在打印0或1
只有二者值都很大时,才说明算法是有用的
精确率表示实际上y = 1的可能性
召回率表示模型计算出y = 1 的可能性
对于精确率和召回率的衡量
一种是通过设置阈值大小去权衡二者,从而进行取舍
提高阈值,会增加精度,降低召回率
降低阈值,会降低精度,提高召回率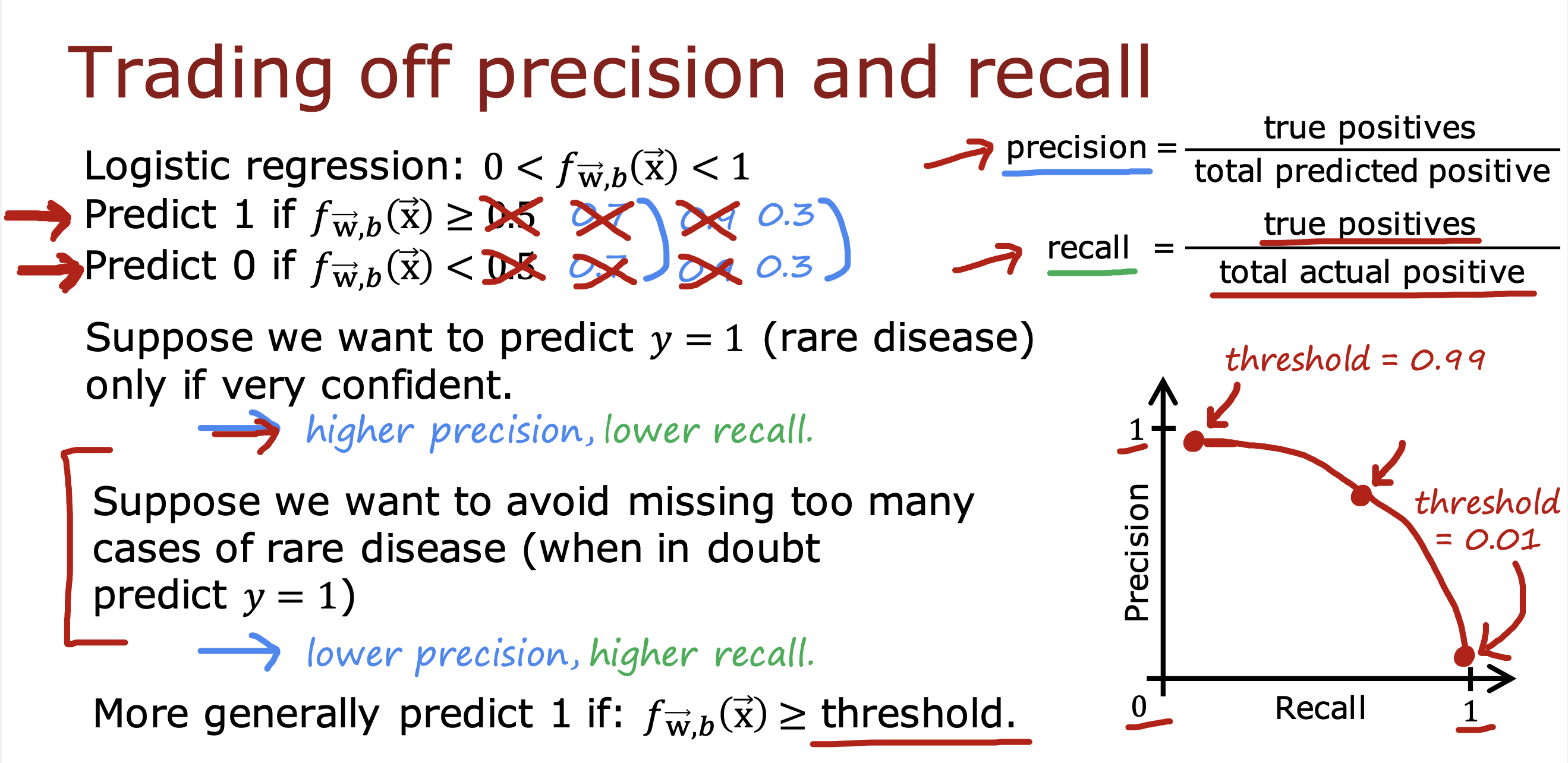
另外一种是使用F1 score分数(调和平均数),自动计算出最佳的精度和召回率,从而选择对应的算法