通过判断高方差和高偏差的大小可以判断模型的性能问题
一般有以下两个性能问题
高偏差意味着模型欠拟合
高方差意味着模型过拟合
高偏差的情况下,
Jtrain 值会比较大,且Jtrain和Jcv 值相近
也就是说Jtrain 较高对应的训练数据的拟合度本身就不够
高方差的情况下,
Jcv 会远大于Jtrain, Jtrain 值可能比较小
就是说模型对训练数据很拟合,但是对交叉验证数据不够拟合
也有高方差和高偏差两个问题同时存在的情况
Jtrain 值会比较大,且Jcv 远大于Jtrain,
这种情况意味着模型可能对一些数据过拟合,对一些数据又存在欠拟合

正则化参数𝜆 对模型的影响
如果𝜆偏大会导致Jtrain 偏大,出现欠拟合
(想象𝜆现在是一个非常大的数值,为使Jtrain 最小,就会让w值逐渐趋近0, 最终模型无限接近b)
如果𝜆偏小会导致Jtrain 偏小,但是Jcv 偏大,出现过拟合
(想象𝜆现在无限趋近于0,或者直接等于0, 那么要使Jtrain 最小,w取值就得变大,多项式就会被保留,最终模型出现过拟合)
如果𝜆取值适中就可以实现Jtrain和Jcv 值都偏低,模型适当拟合的效果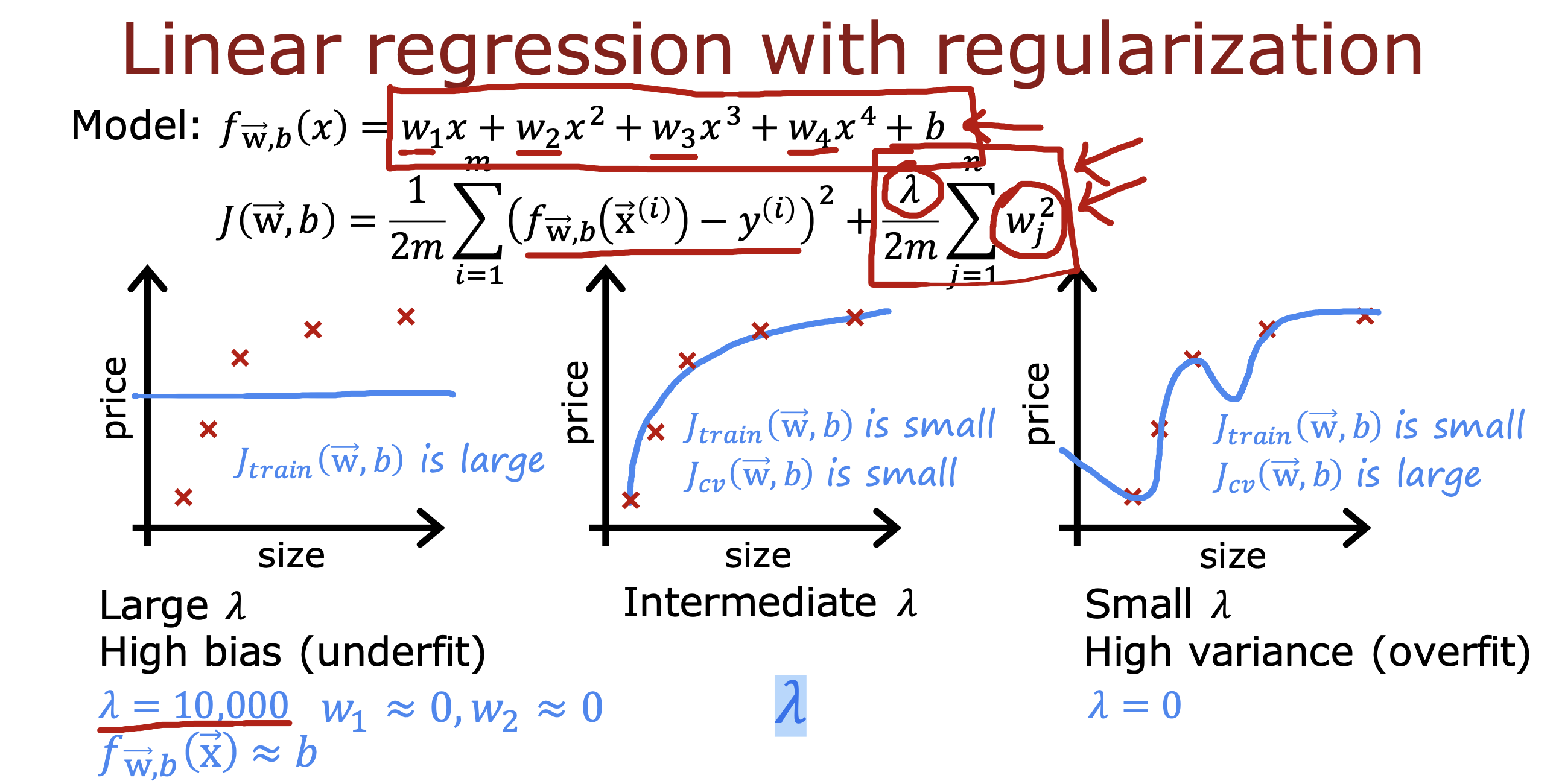
𝜆 如何取值
通过选取不同 𝜆 带入计算最小损失函数,用得到的(w,b)值计算Jcv, 选取多组Jcv 中 最小值的(w,b)进行Jtest 计算,
𝜆 趋势图
𝜆 对于误差的影响趋势和多项式对误差的影响趋势呈镜像关系
𝜆 值从小到大,Jtrain 从小到大,模型从过拟合到欠拟合
多项式平方数从小到大,Jtrain 从大到小, 模型从欠拟合到过拟合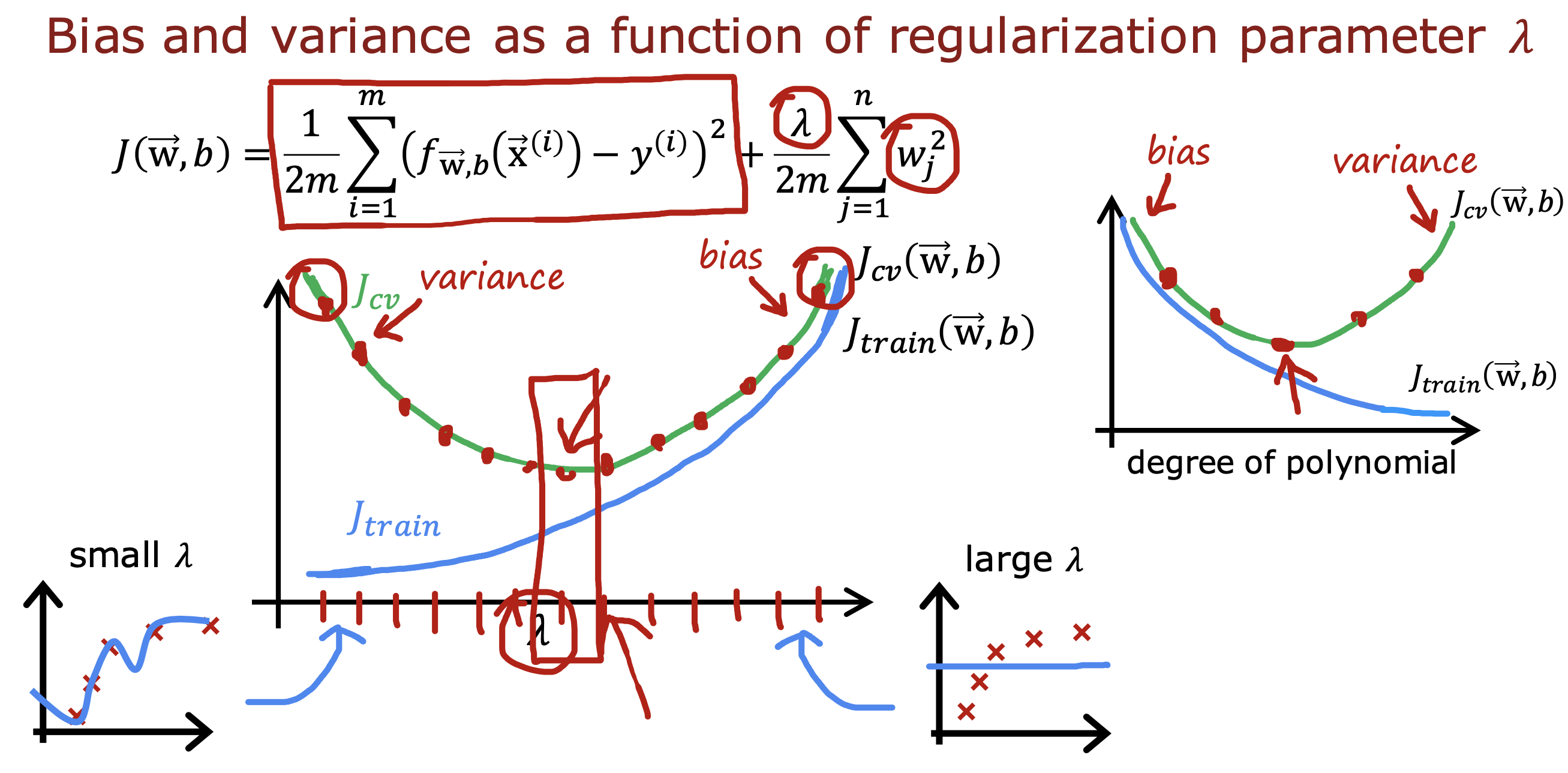
建立性能基准线来判断模型性能
计算基准线与Jtrain 的差A, A 如果偏大说明模型存在高偏差欠拟合问题
计算Jtrain 与 Jcv 的差B,B 如果偏大说明存在高方差过拟合问题
如果A 大于B 说明存在高偏差,欠拟合
如果A 小于B 说明存在高方差,过拟合
如果A 和 B 数值接近,说明 高偏差和高方差同时存在
基准线可以来自
人类的测试水平
竞争算法的性能水平
基于过程经验判断的水平
以 语音识别为例
学习曲线
Jtrain 和Jcv 随 训练集大小m变化的趋势曲线被称为学习曲线
一般情况下,
Jtrain 会随m 变大逐渐变大,因为为了拟合更多数据,数据比一定会散落在曲线上,误差累加起来数值会变大
Jcv 会随m 变大逐渐变小,因为更多的数据可以展示更多的情况,是模型拟合度更高,对于Jcv 计算就是越小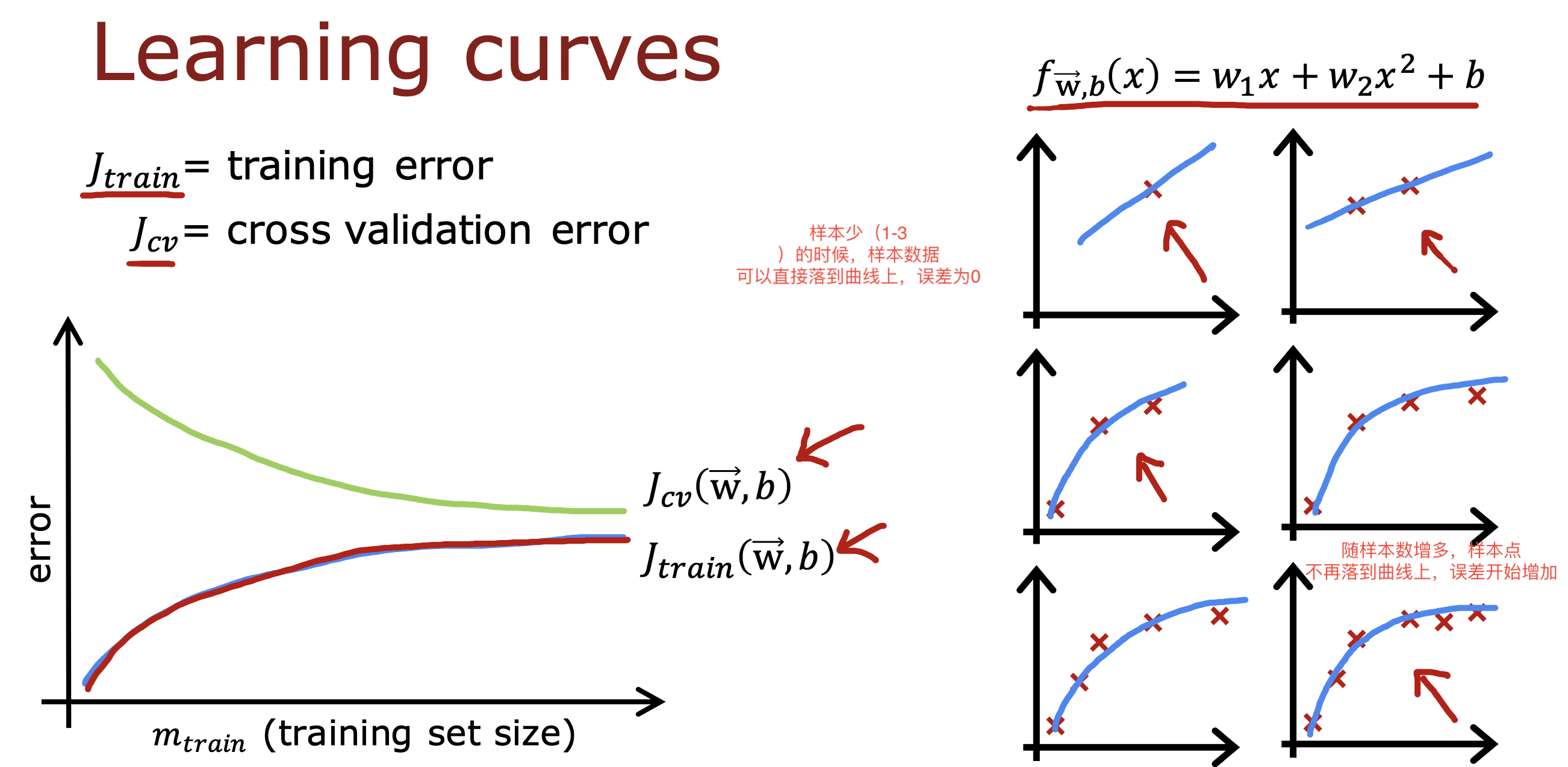
但是对于存在高偏差的模型,增加样本数量并不一定能对模型拟合产生多大帮助,
因为高偏差模型具备欠拟合特点,随样本数增加损失函数也会增加,且相对基本线误差依然存在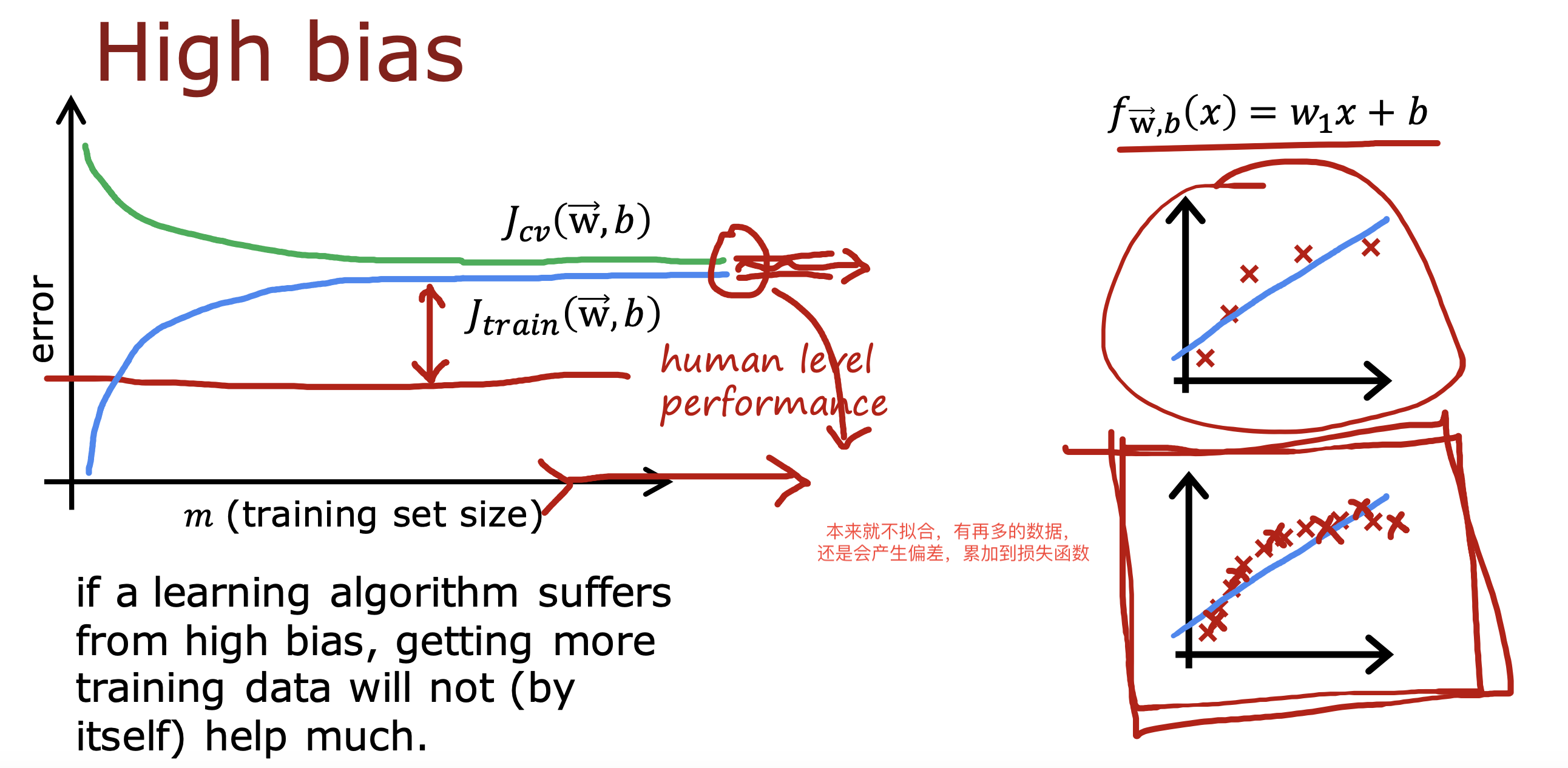
对于存在高方差的模型,增加样本数量可以起到一定帮助
因为高方差模型具体过拟合特点,会将增加的样本继续拟合到自己的训练模型中,相当容纳近了更多的数据情况
可以更好的拟合实际的情况
小结
高偏差和高方差的一些解决方案
神经网络中的应用
神经网络是低偏差的模型,
在训练过程中如果Jtrain 过大可以使用更大的神经网络,缺点就是运算速度会变低且会增加研发成本
在Jtrain 基本与基准线相差不大时计算Jvc,如果Jvc 过大可以增加数据样本重新回到模型计算
经过上面不断重复的过程,最终得到合适的模型参数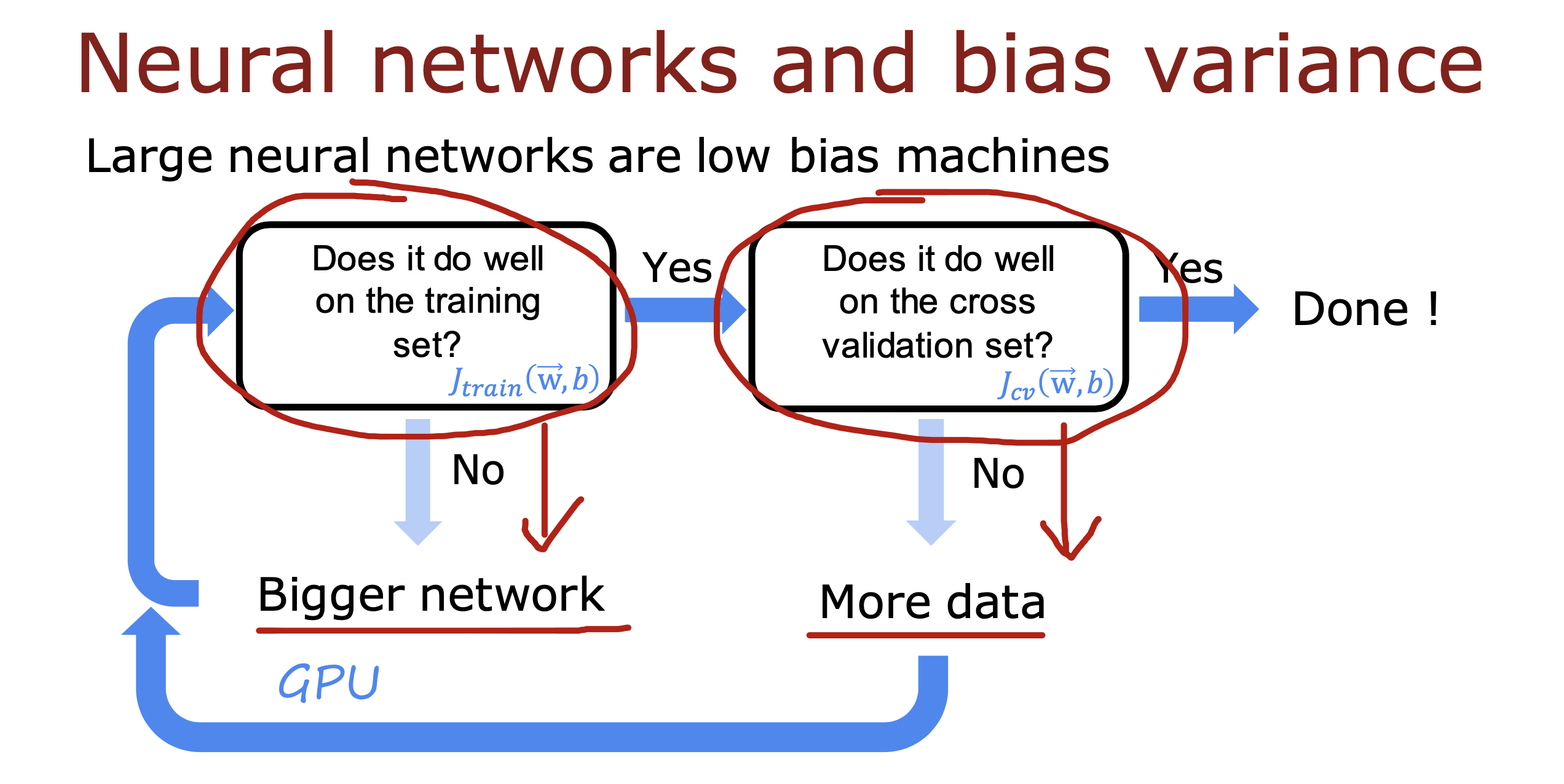
只要数据规则化做的合适,大型神经网络总是会比小型神经网络表现好一些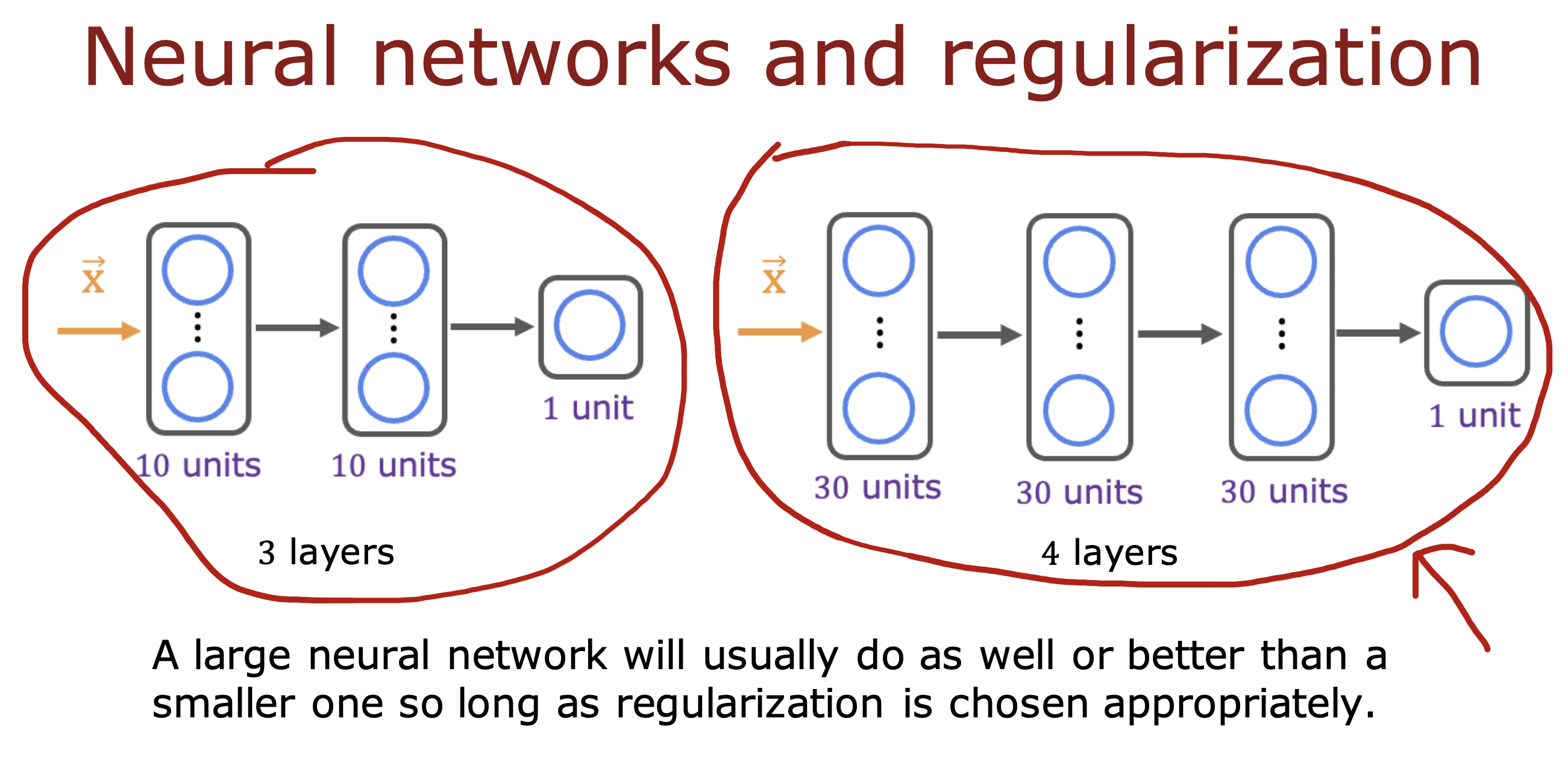
在tensorFlow 中,可以在构建layer 时传入规则化参数
练习
练习多项式,正则化参数𝜆,训练数据个数m, 神经网络层数
链接
The simple model is a bit better in the training set than the regularized model but it worse in the cross validation set.