数据集的使用
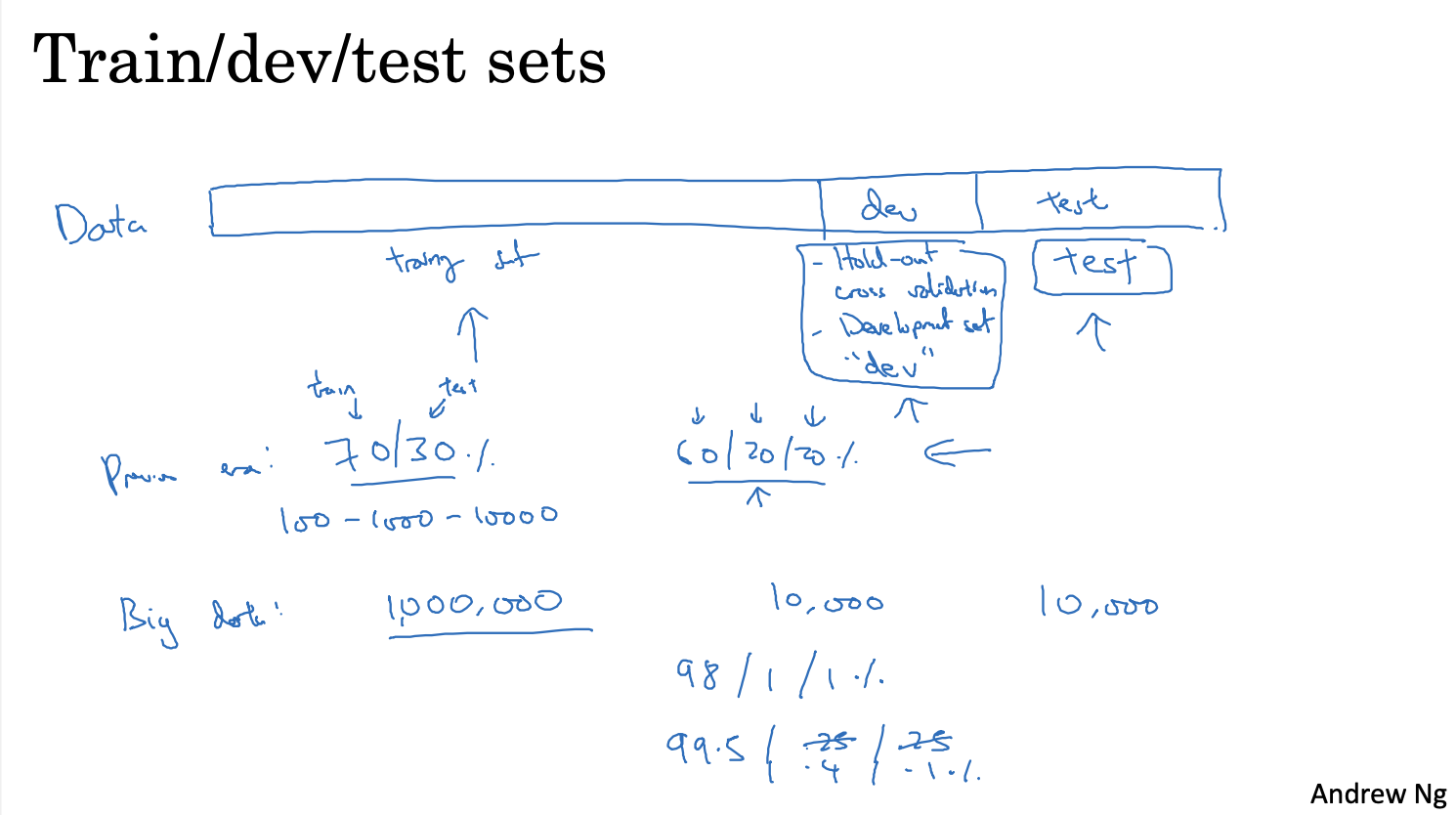
一般将数据集分成三部分,训练集(training set),交叉验证集(cross validation set / dev set),测试集(test set)
训练集用于训练模型
交叉验证集用于调整超参数,或者比较不同模型算法性能的优劣
测试集用于对最终模型的进行无偏评估(是否存在欠拟合或过拟合)
如果不需要进行最终的无偏评估,那么可以将交叉验证集和测试集合并为一个数据集,进行模型训练和评估
将测试集数据合并到交叉验证集中,数据集最终只会剩下训练集和测试验证集
另外需要注意进行训练的数据集和验证测试的数据集要来自同一个分布,否则会影响训练速度
比如训练集图片来自网络,分辨率高,清晰度高,但是测试集图片来自手机,分辨率低,清晰度低
那么训练出来的模型在测试集上的表现可能会很差

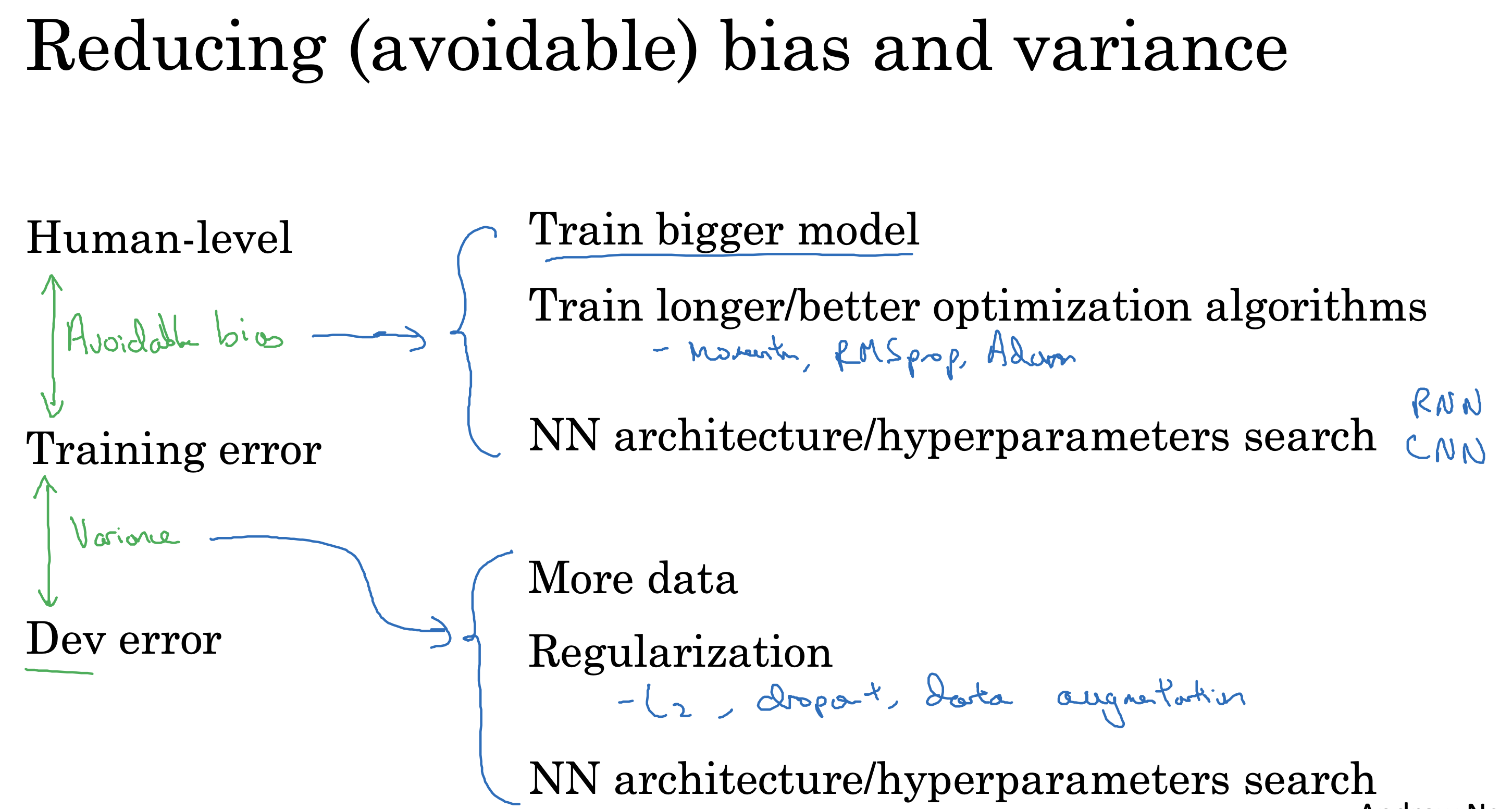
使用偏差(bias)和方差(variance)对模型进行评估
高偏差一般欠拟合
高方差一般过拟合
先来复习一下偏差和方差的定义
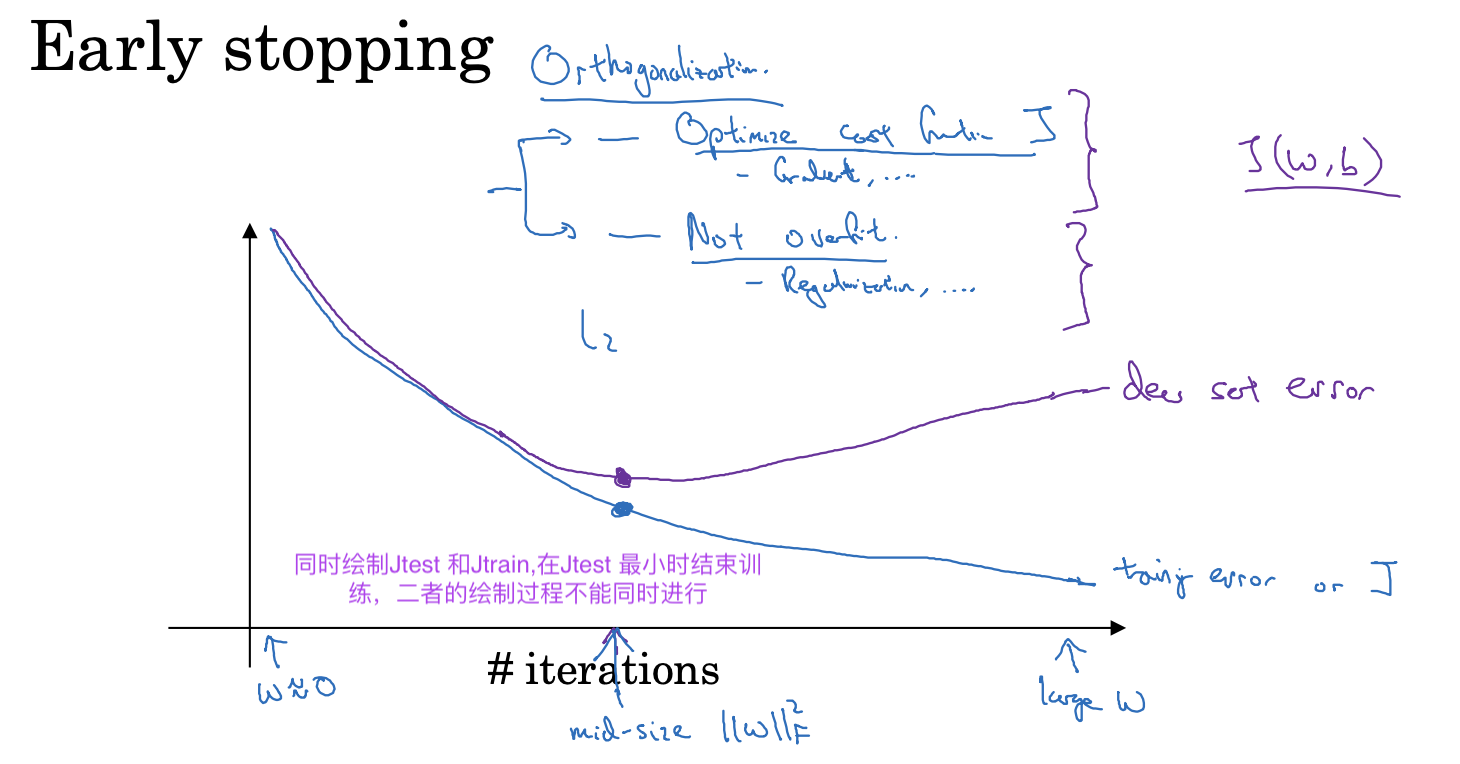
解决过拟合问题
高偏差和高方差

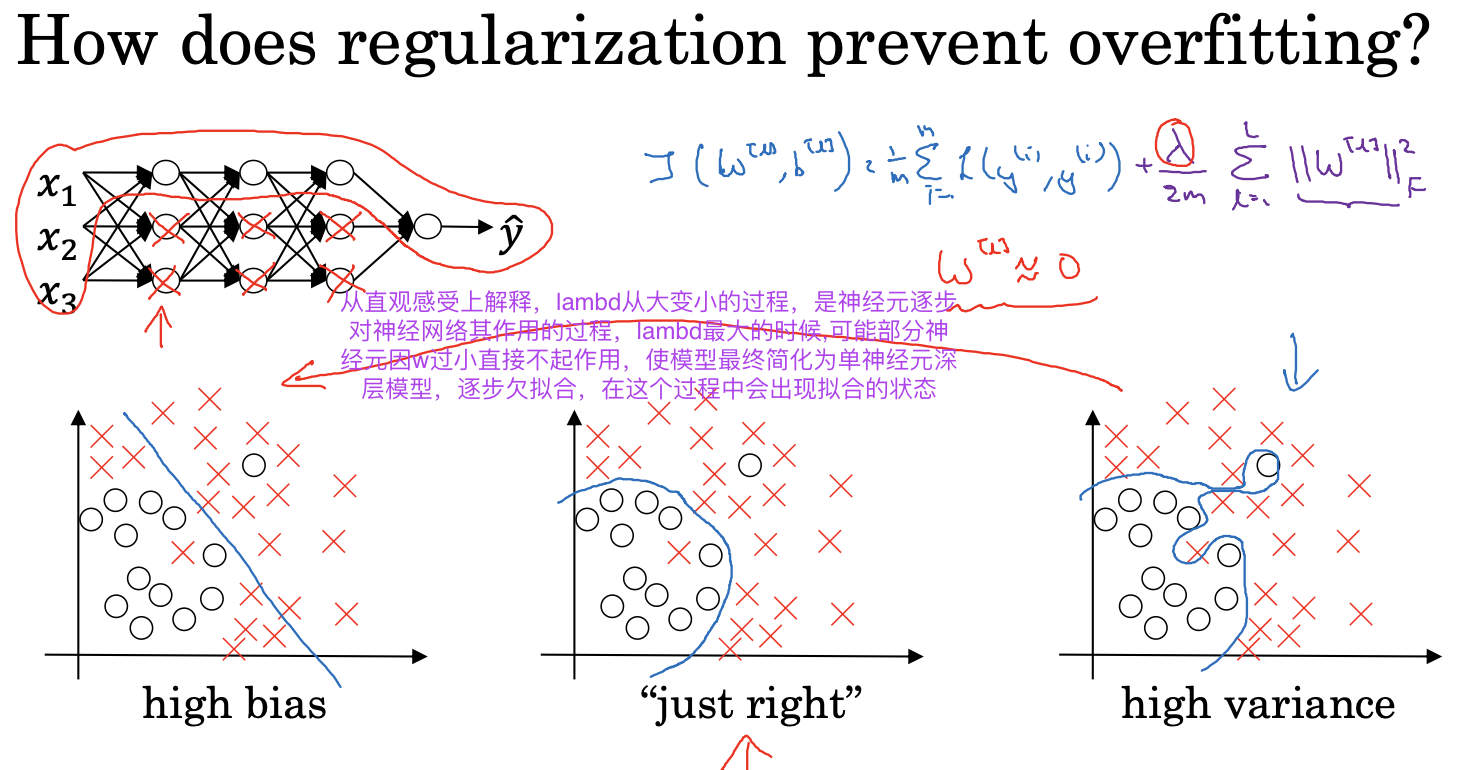
正则化处理(Regularization)过拟合问题
通过给成本函数增加正则化项,进行权重衰减,来降低模型的方差,从而避免过拟合的出现

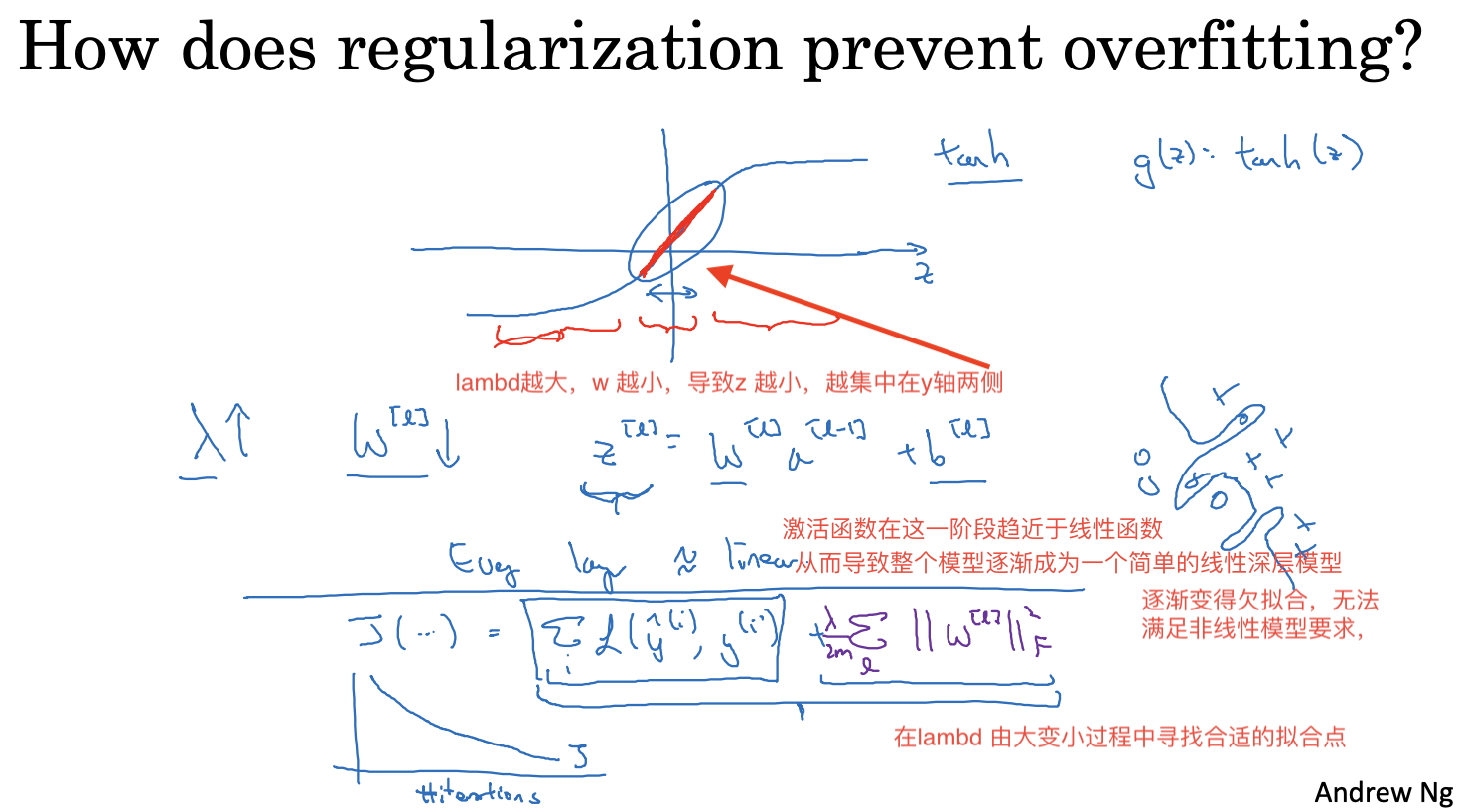
L2 具体实现


Dropout 正则化
dropout 方法 实现原理就是在每层计算前前,生成随机蒙层,按keep_prob比例随机干掉一些节点,再参与运算,计算后除以keep_prob,保证最终输出的结果不变
在反向传播时,使用向前传播的蒙层对梯度进行相应的处理,保证该轮的参数矩阵相同,所以要对向前传播的蒙层进行缓存处理方便使用

可以看到相比L2 类似于对w 进行缩小处理,dropout 方法类似于对w 进行放大处理, 因为干掉一些节点相当于随机取消某些w 的影响,最后除以keep_prob 相当于对w 进行放大处理
其它正则化方法
除了上面提到给cost函数添加L1,L2正则化项,还可以通过dropout 方法,数据增强,提早结束训练等正则化方法来避免过拟合的出现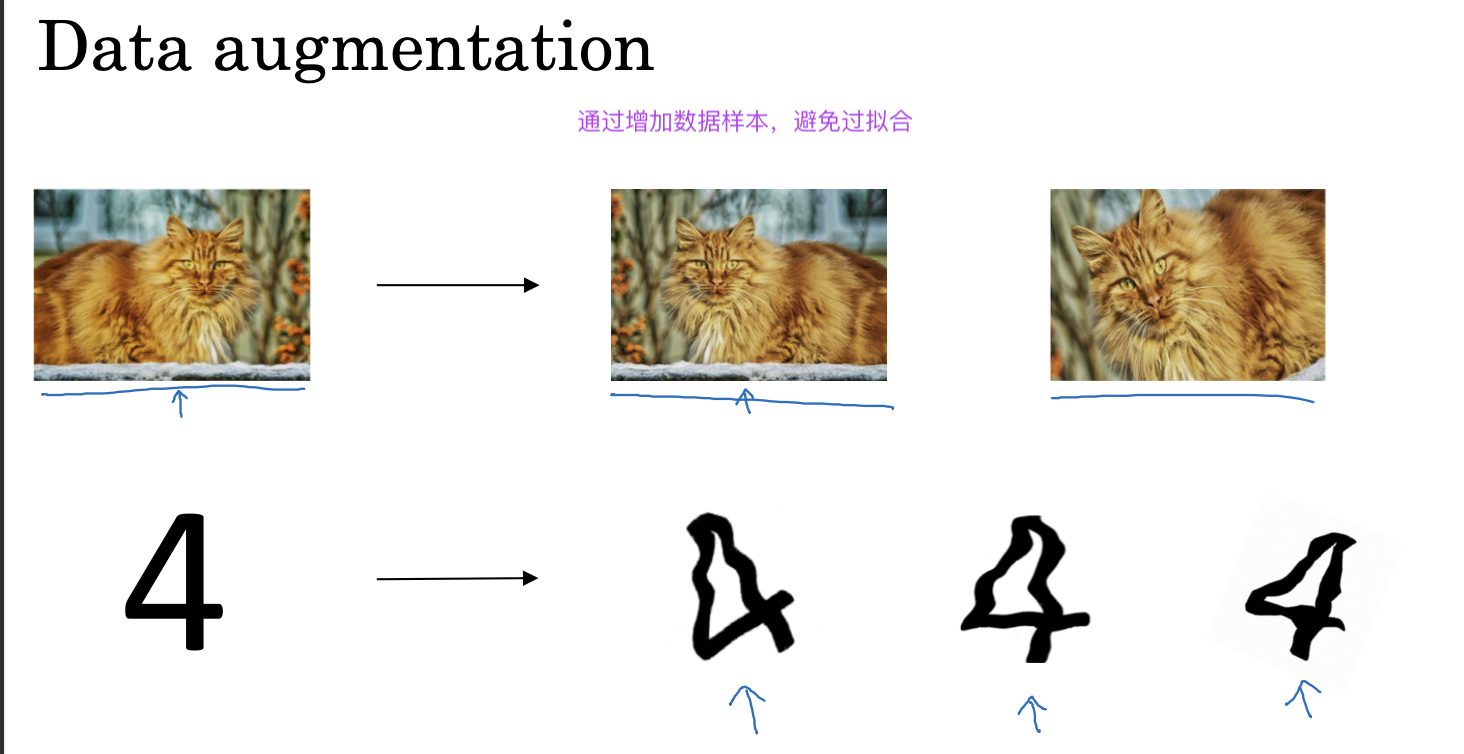
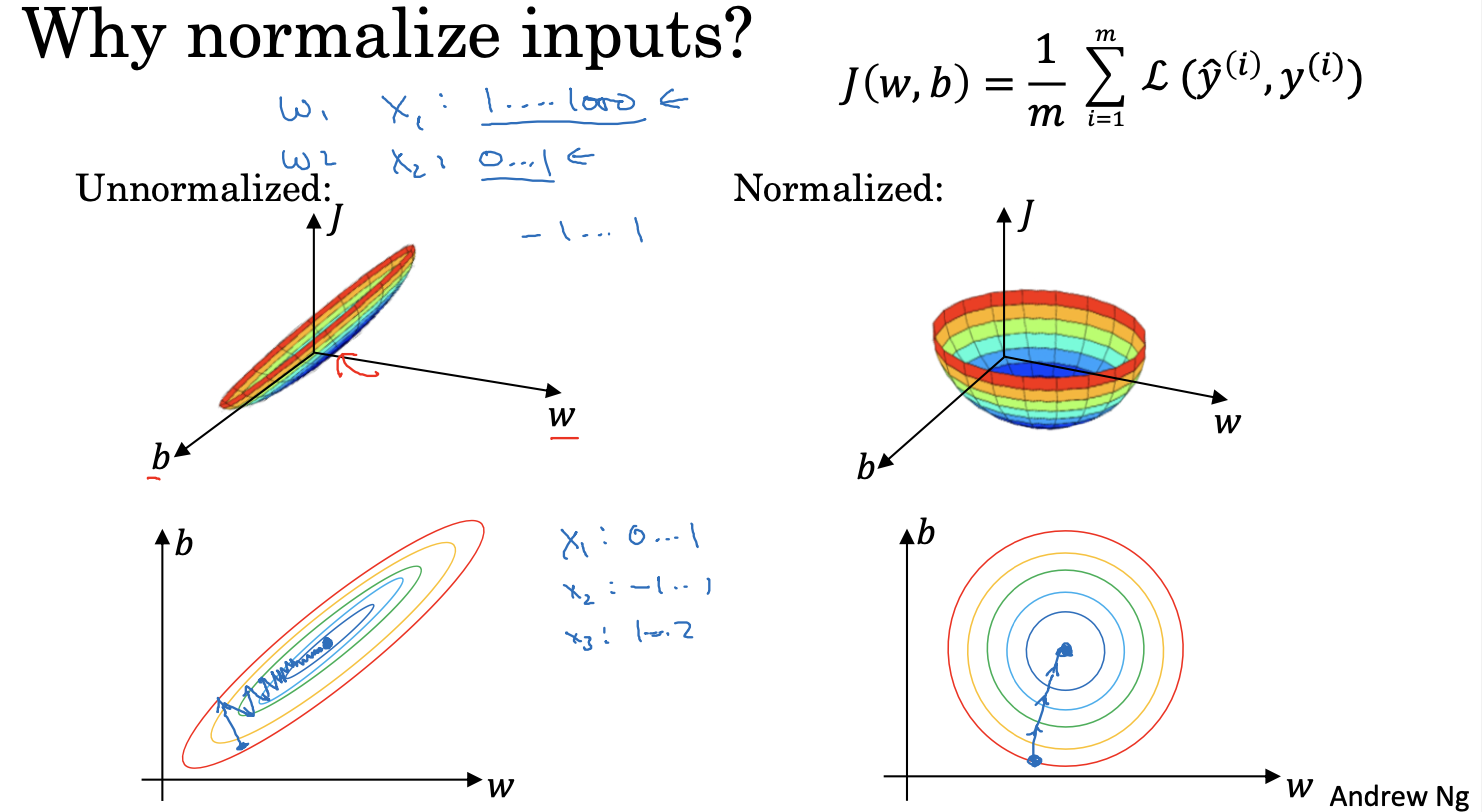
归一化训练集
通过对训练数据集进行归一化处理,加快梯度下降,提高训练速度
复习一下特征放缩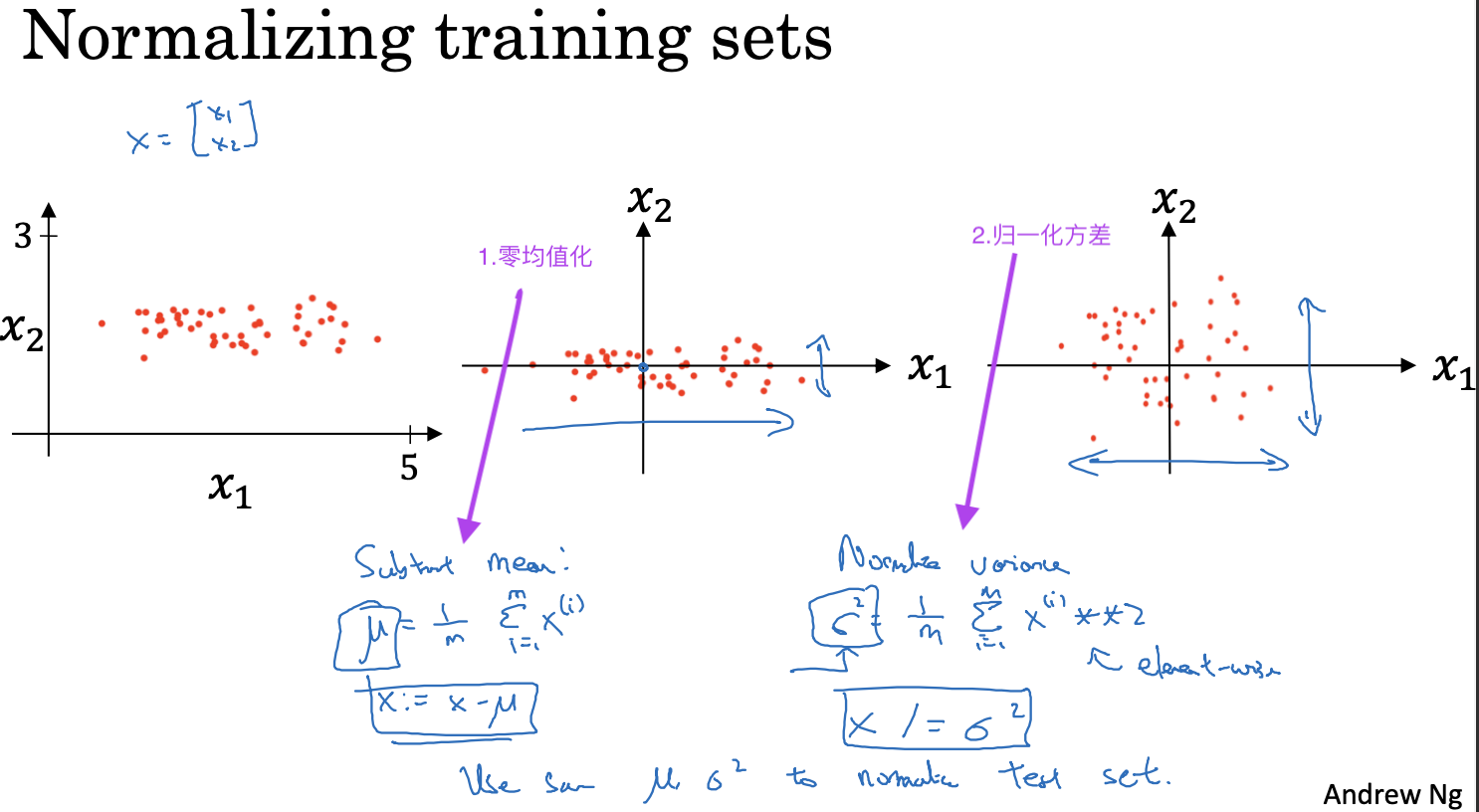
初始化参数
由于神经网络的多层的计算过程中,权重是乘积关系,如果各层初始化参数一开始大于1 或者小于1,整个乘积下来,就导致y^ 无限大或者无限小,从而导致梯度爆炸或者梯度消失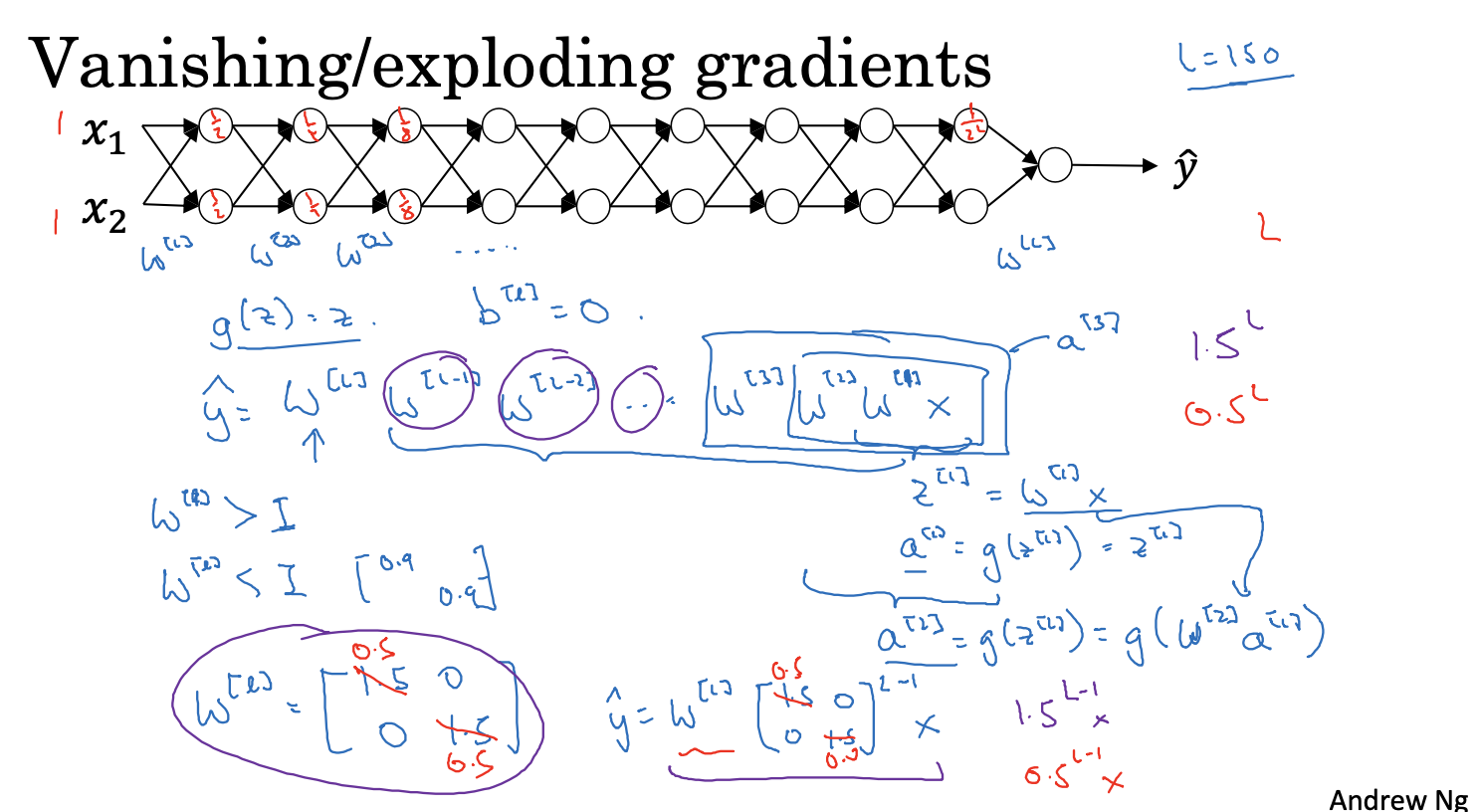
解决
不同初始化参数方式
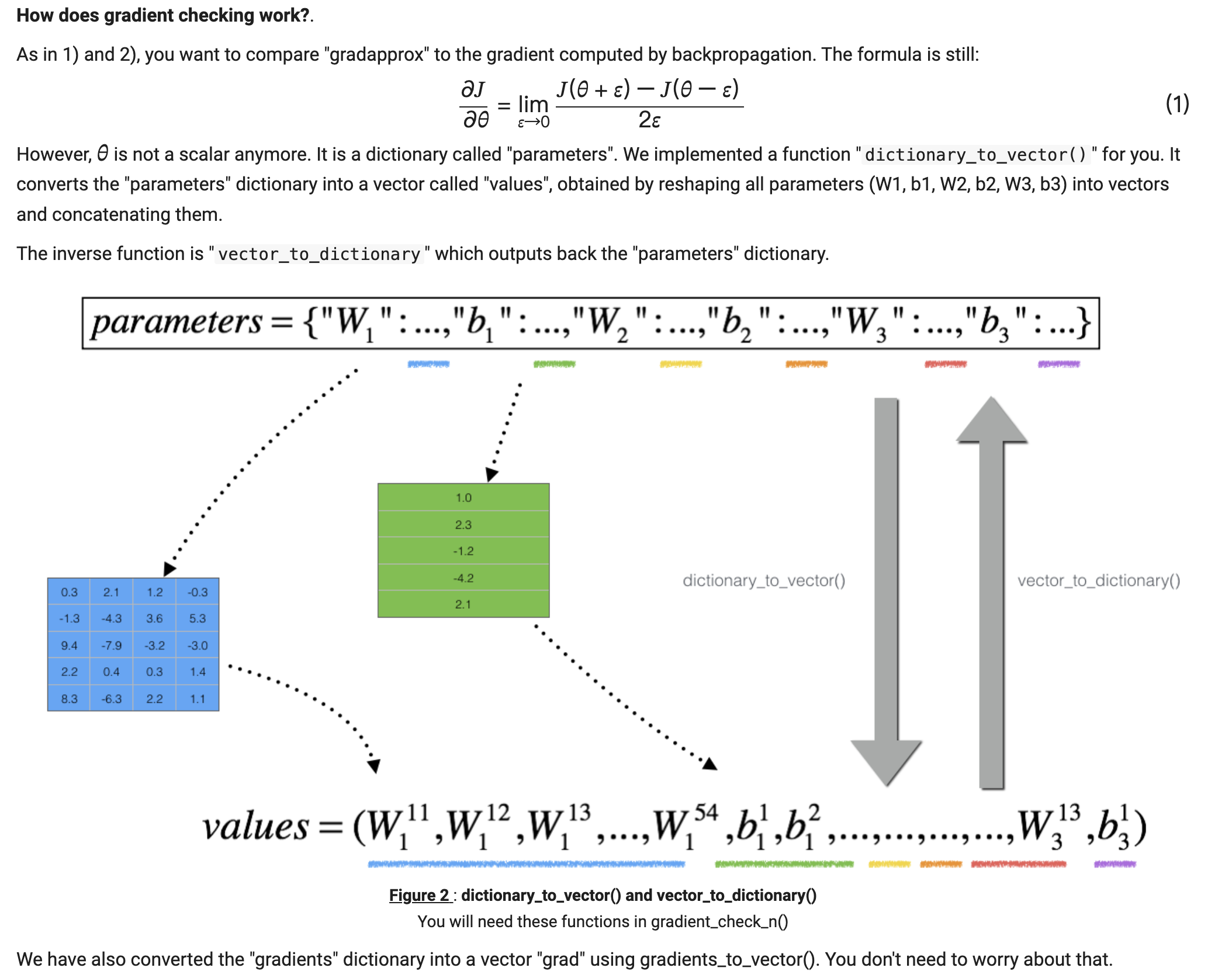
梯度校验
双边误差会比单边误差更准确
梯度校验的过程就是拿到一轮训练的参数和梯度,进行摊平处理,字典变 n * 1 二维数组,每一层的每一个w 是一个数组
对每一层每一个参数修改一个很小的值,一次加,一次减,重新计算cost 值,拿到两个cost 值后进行双边误差计算,
整个参数都计算完后,与梯度进行比较,详见公式
如果比较值相差不大,说明梯度计算没有问题

实验


分析解决问题
之前提到的一些优化模型的方法
正交化
是一种解决问题的思想,简单来说就是通过将问题分解为相互独立的子问题,从而使得每个子问题可以独立解决,减少相互干扰
比如下面的训练过程,每一个阶段有每一个阶段要完成的目标,每一个阶段的实现目标过程会遇到不同问题,针对不同阶段不同问题采取相应解决办法
每个子目标相互独立,互不干扰一个阶段的目标完成后,再进行下一个阶段的目标
就相当于把一个大问题分解为多个小问题,每个小问题相互独立,互不干扰,
针对不同问题,采取相应的解决办法,最终完整整个模型的训练
建立单一数字评估指标
如果需要对多个指标进行优化,参考上面正交化思想,独立解决每个指标的优化问题,即建立单一数字评估指标
模型评估阶段会用到多个指标,比如准确率,召回率,F1 值,
但是这些指标之间存在相互影响,比如准确率高,召回率低,F1 值低
所以需要建立单一数字评估指标,比如F1 值,通过F1
此时F1 值就是【优化指标】(需要继续提高的指标),其他指标就是【满足指标】(达到一定阈值即可)
之后模型训练相当于就朝着优化项指标进行训练,有的放矢
或者通过其他指标综合计算出唯一的指标值来评估模型优劣
相关复习一
相关复习二
混洗数据保证数据分布均匀
避免dev和test集数据分布差异过大,在训练过程中,会导致模型训练效果不佳
在训练前,把数据进行混洗,打乱数据分布,保证dev和test数据分布差异不大
Choose a dev set and test set to reflect data you expect to get in the future and consider important to do well on.
数据集大小建议
Set your dev set to be big enough to detect differences in algorithm/models you’re trying out.
Set your test set to be big enough to give high confidence in the overall performance of your system.
如果对实际数据效果要求较高,那么最好要有test set 进行性能测试,否则会影响实际使用效果
更改指标
如果训练过程中,之前设置的指标已经不能满足模型训练要求,
或者已经错误的对模型进行了筛选,
要么需要更改指标,要么需要更改模型结构,要么更改dev/test set

以人的能力为参考
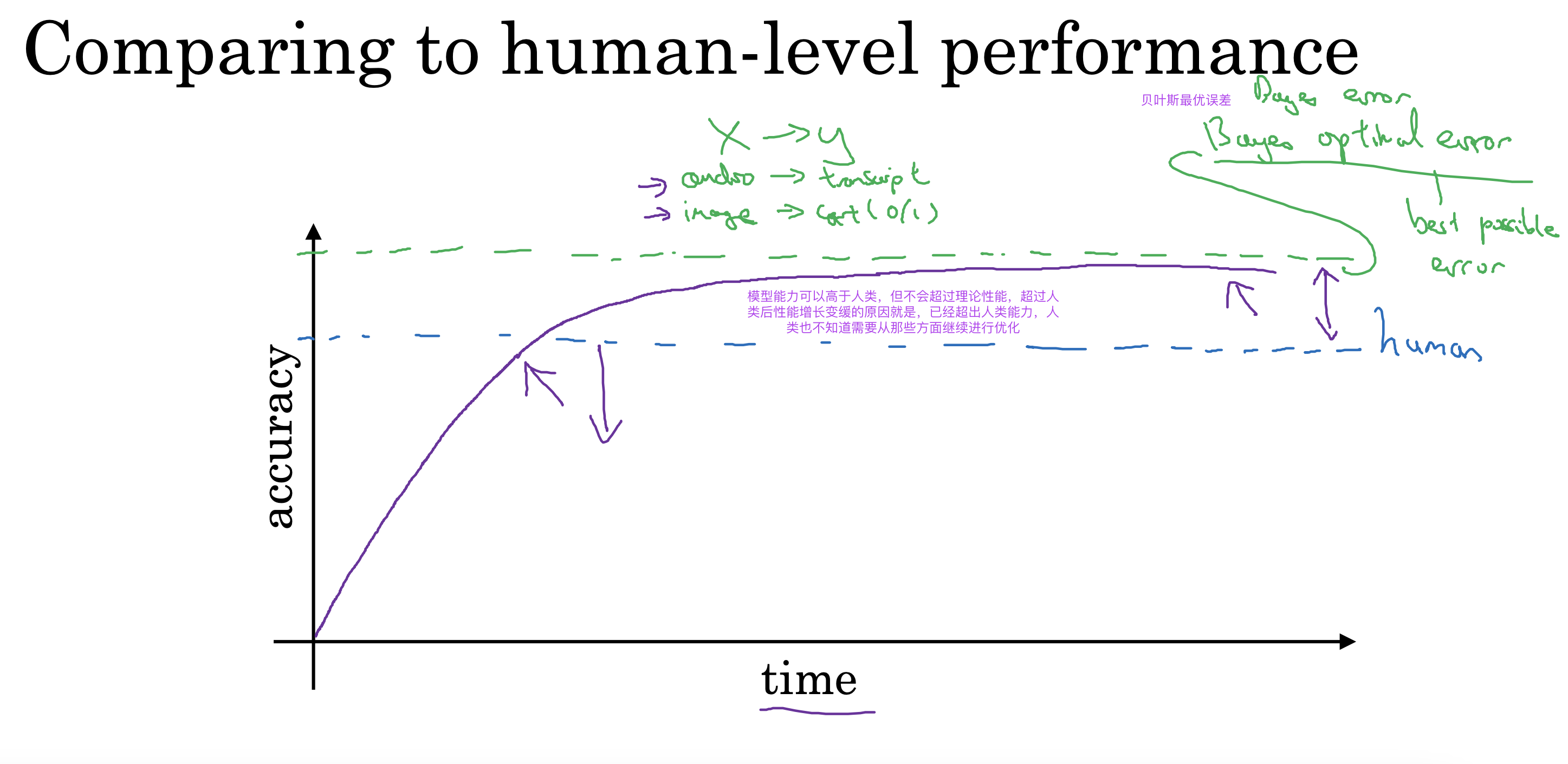
Why compare to human-level performance
Humans are quite good at a lot of tasks. So long as ML is worse than humans, you can:
- Get labeled data from humans.
- Gain insight from manual error analysis: Why did a person get this right?
- Better analysis of bias/variance.

小结

错误分析
对判断错误的数据进行错误类型统计分析,决定下一步优化方向,给出优先级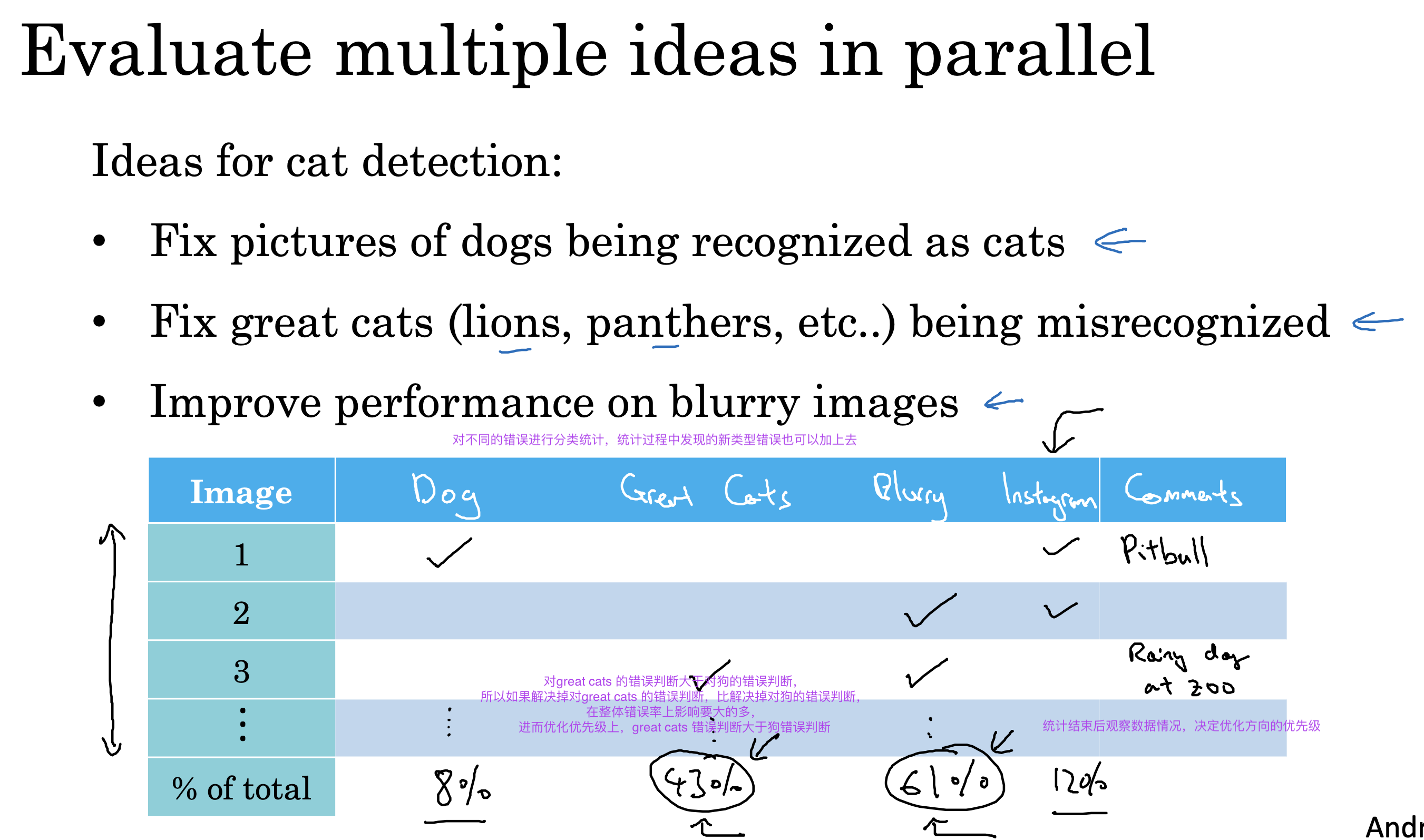
清除标签错误
如果dev/test set 数据中,存在标签错误的数据,
如果该类数据在错误数据中占比较大,已经影响到dev set 阶段对模型的选择
则需要采取措施进行标签错误的数据清除
Correcting incorrect dev/test set examples
• Apply same process to your dev and test sets to make sure they continue to come from the same distribution 分布相同
• Consider examining examples your algorithm got right as well as ones it got wrong.正确错误数据都检查下标签
• Train and dev/test data may now come from slightly different distributions. 训练数据和验证测试数据现在可以来自稍微不同的分布
不同分布数据集处理
对于训练集和验证测试集分布不同的问题
不建议将数据混洗后再进行训练,这样会导致验证测试阶段不是实际数据,而是部分测试数据的问题
更好的处理办法是把验证测试集数据集的50%也进行训练,剩下50%再均分进行验证测试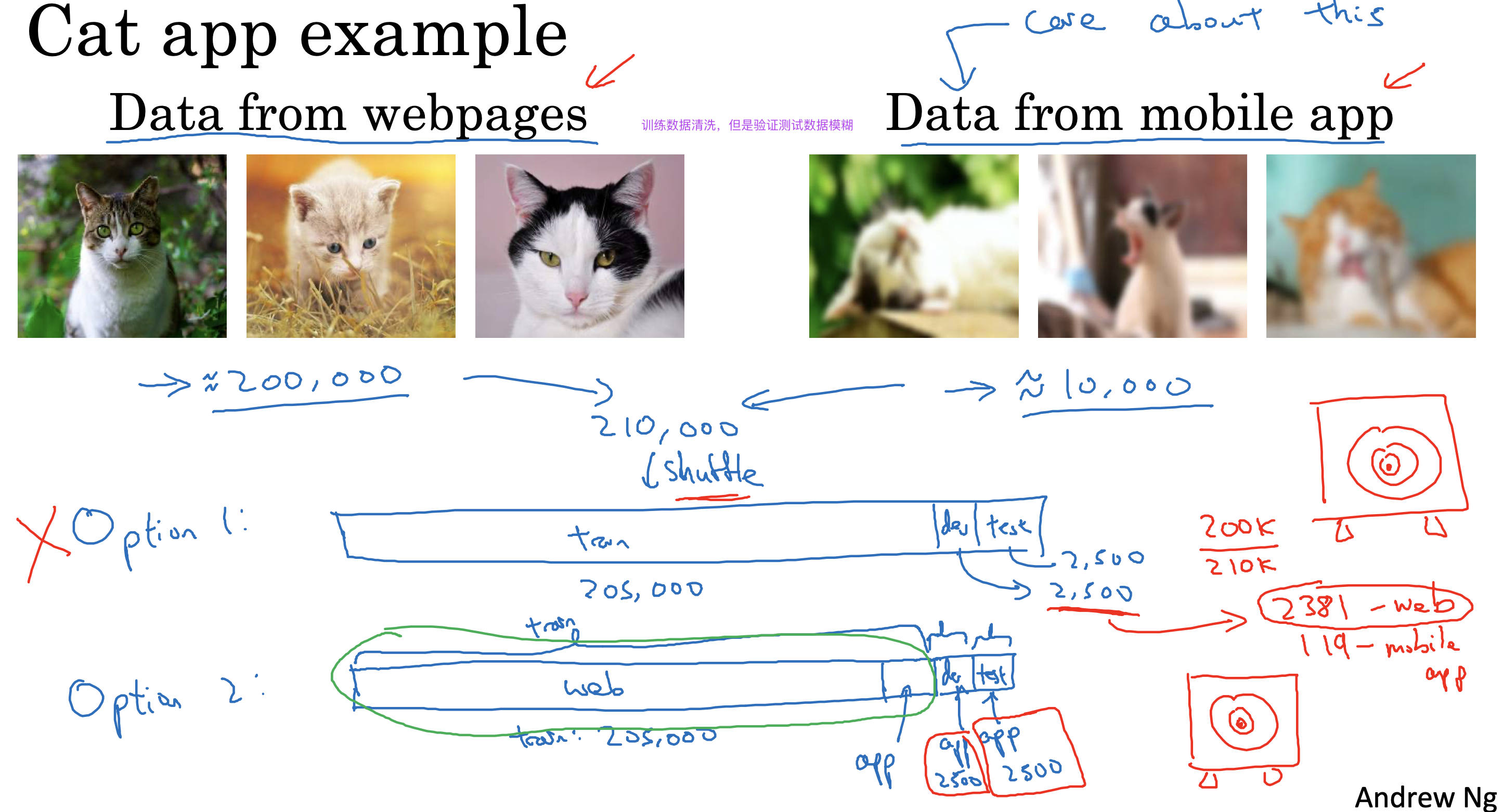
快速搭建然后迭代
如果需要对一个全新的问题进行模型训练,建议快速搭建模型,然后迭代,在迭代中发现问题,优化算法
• Set up dev/test set and metric
• Build initial system quickly
• Use Bias/Variance analysis & Error analysis to prioritize next steps.
但是要尽可能避免系统过于简单或者过于复杂,
对于有众多论文支持的问题,比如人脸识别,可以根据论文快速搭建复杂模型,然后开始训练
对于陌生领域的问题,则可以由简单到复杂进行训练
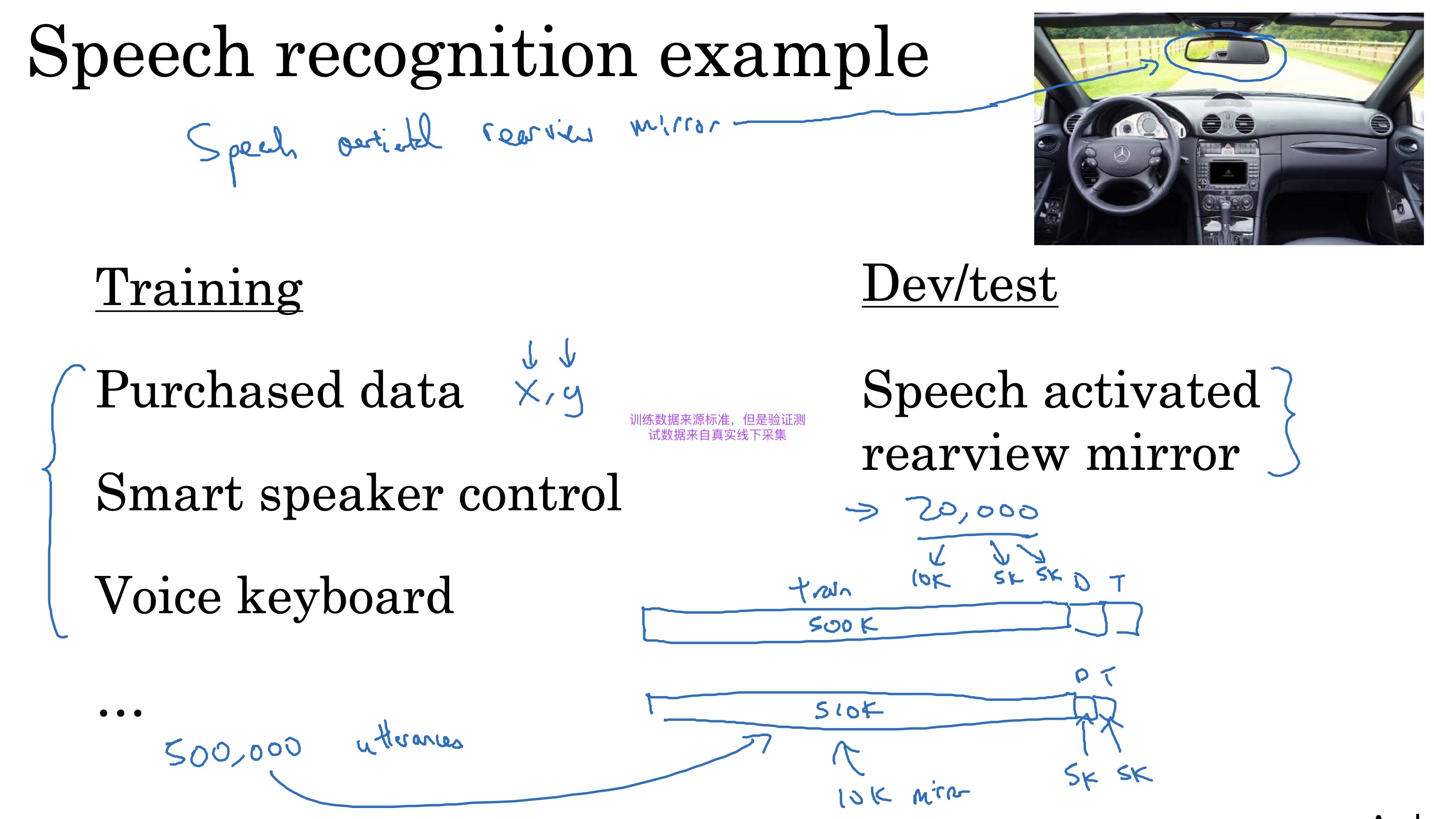
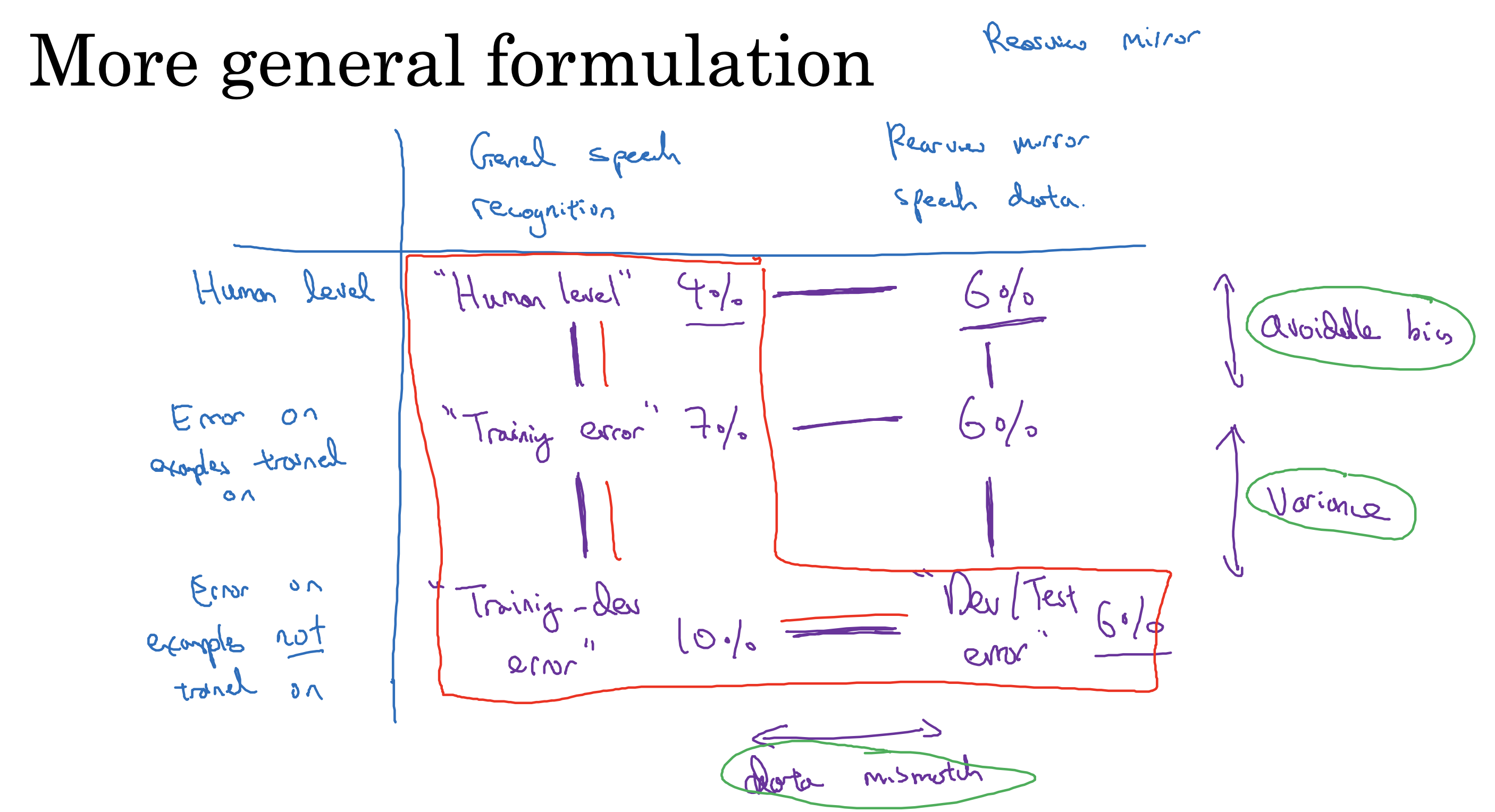
不匹配数据
更细致的对错误率进行分析,通过计算不同错误率的差值,分析不同原因比重,决定优化方向
· 可避免偏差
· 方差,如果比较大,说明模型不能泛化到同一分布数据
· 数据不匹配,训练数据和验证数据可能分布不同
· 过拟合程度

如何结局数据不匹配问题
对train set 和dev set进行错误分析,找出二者不同,然后尽可能多的用dev set 数据进行训练
除了去收集真实的dev set,还可以通过人工合成的数据进行训练,
但是要注意,人工合成的数据只是实际数据的一个子集,避免出现对子集数据过拟合的情况
Addressing data mismatch
• Carry out manual error analysis to try to understand difference between training and dev/test sets
• Make training data more similar; or collect more data similar to dev/test sets

迁移学习
复习
适用情形
• Task A and B have the same input x.
• You have a lot more data for Task A than Task B.
• Low level features from A could be helpful for learning B.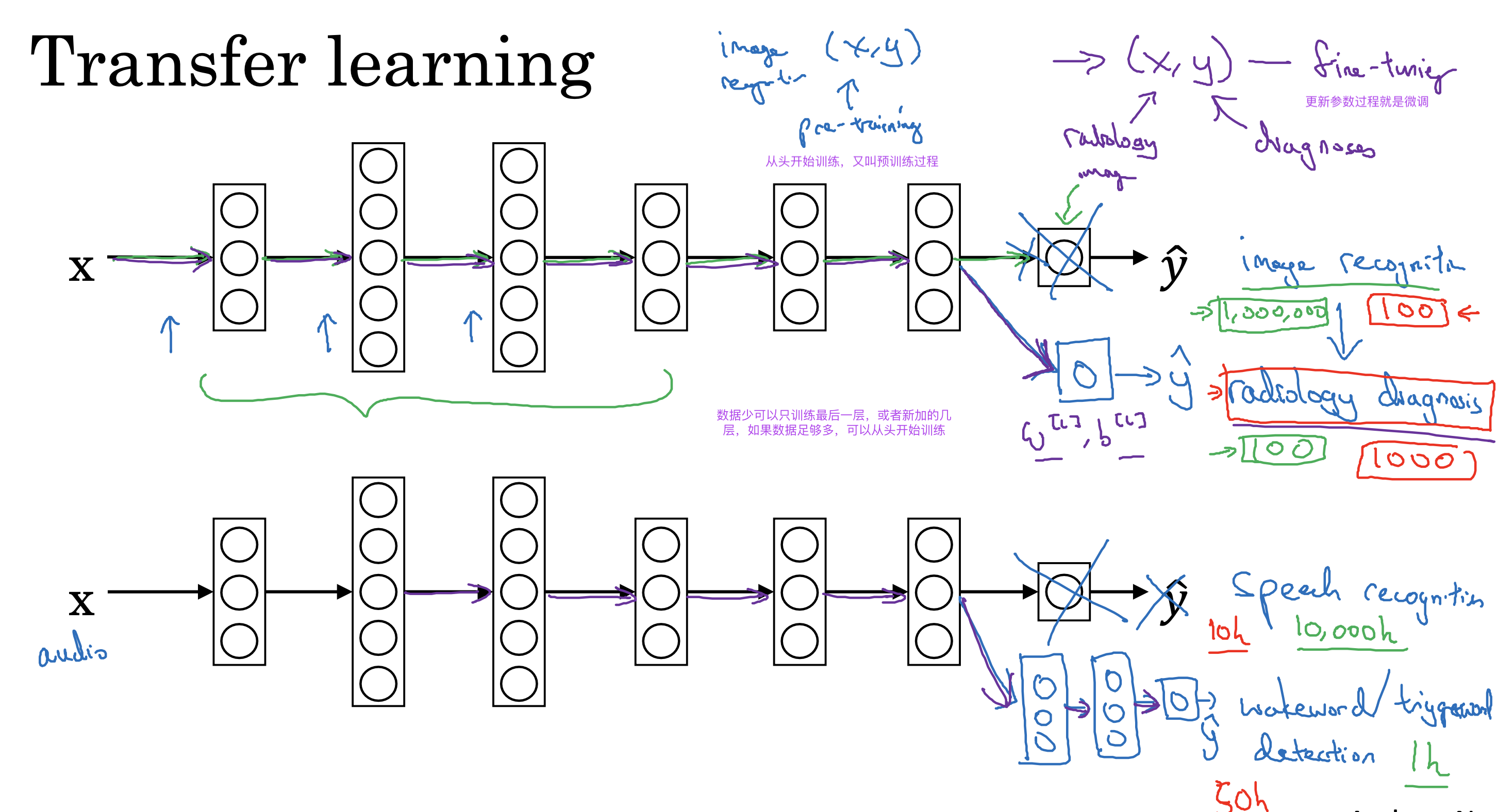
多任务学习
建立单一神经网络同时输出多个任务的结果
适用情形
• Training on a set of tasks that could benefit from having shared lower-level features.
• Usually: Amount of data you have for each task is quite similar.
• Can train a big enough neural network to do well on all the tasks.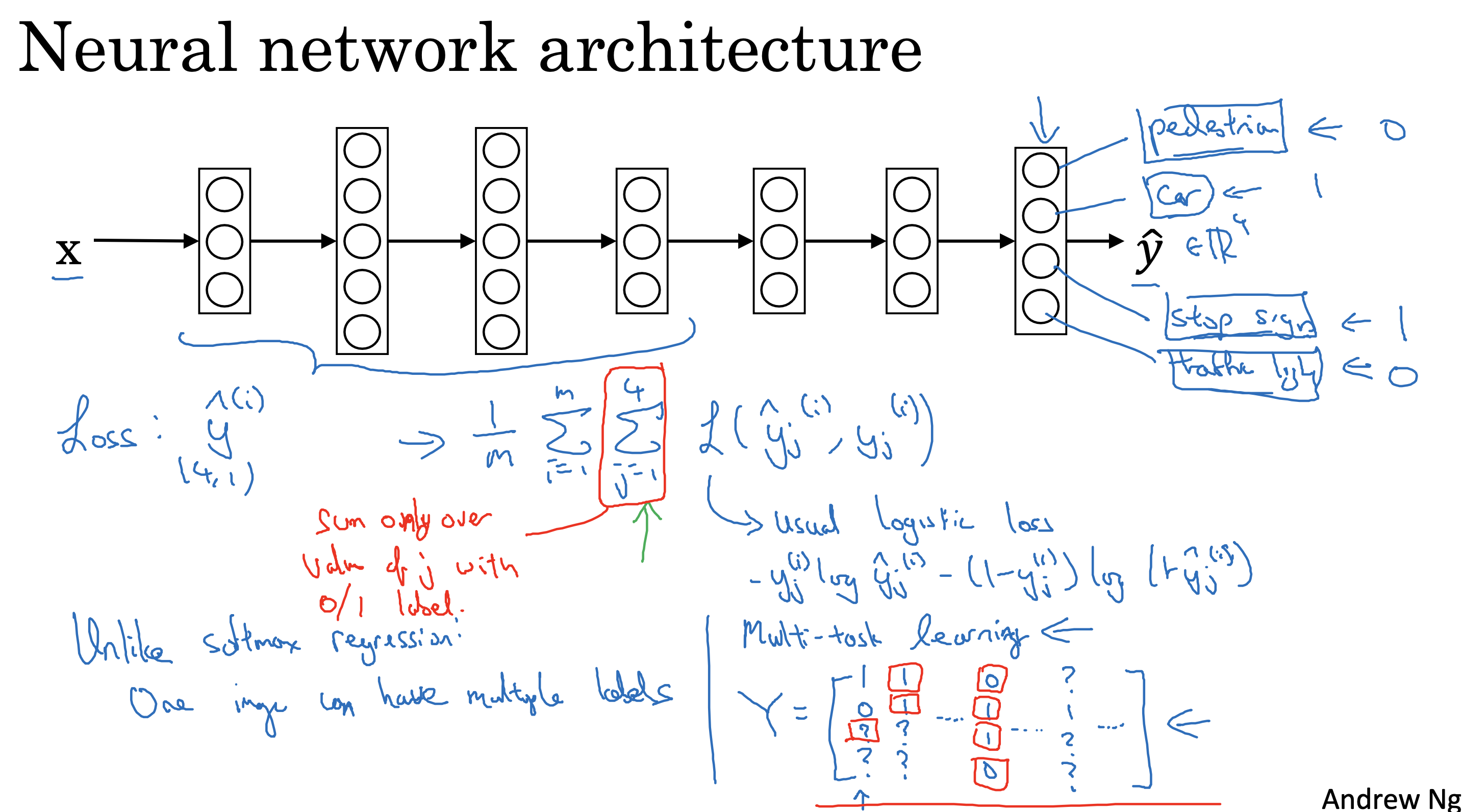
端到端深度学习
端到端深度学习(End-to-End Deep Learning)是指在构建和训练深度学习模型时,直接从原始输入数据到最终输出结果的整个过程都由一个单一的模型来完成。
这种方法避免了传统机器学习中常见的多个独立步骤和手工特征工程,旨在通过一个统一的模型自动学习和优化整个任务。
优点:
• Let the data speak
• Less hand-designing of components needed
缺点:
• May need large amount of data
• Excludes potentially useful hand-designed components
适用情形
Do you have sufficient data to learn a function of the complexity needed to map x to y?
有没有足够有效的直接从x到y映射数据用来进行复杂函数的学习?
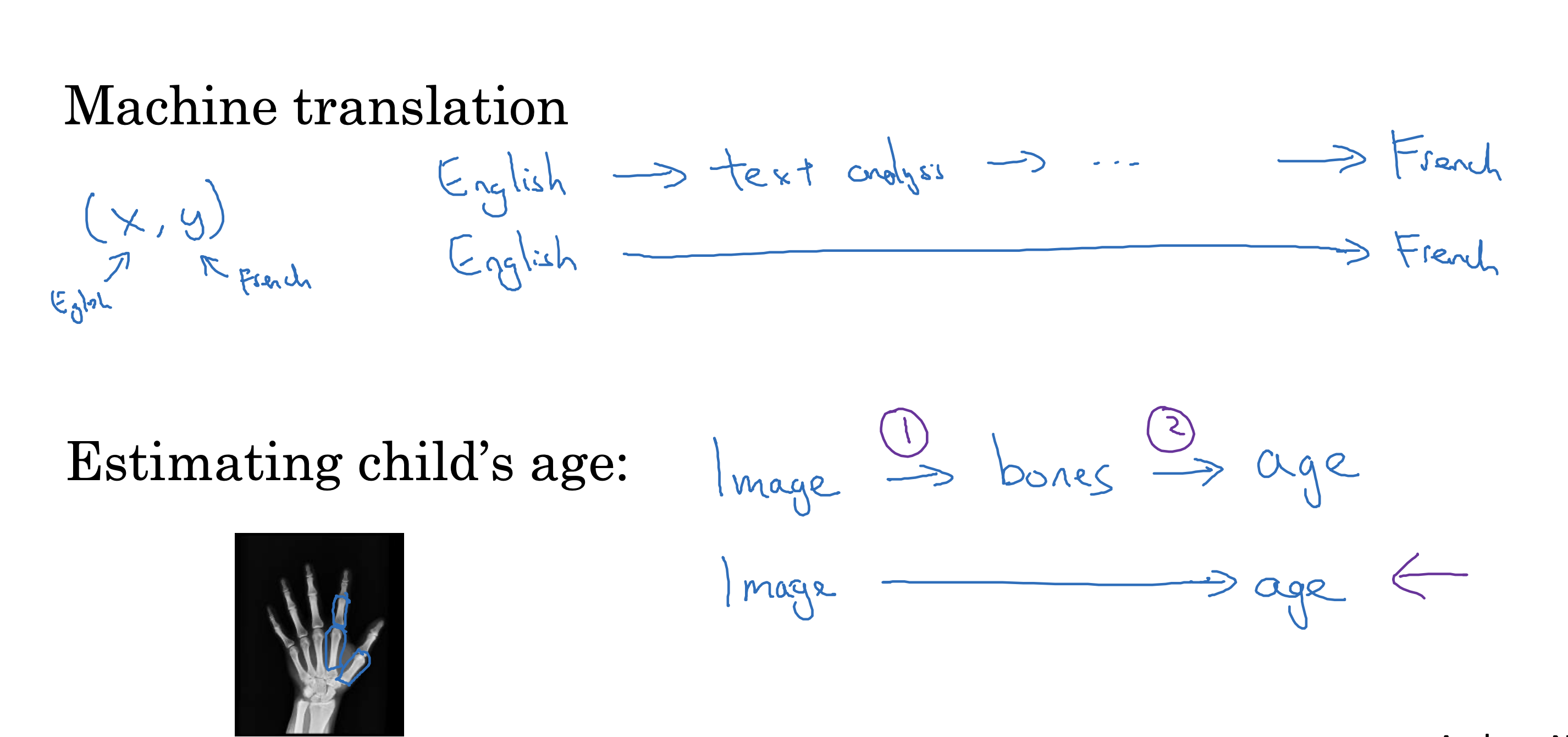
现实中,如果没足够多x-> Y 的映射数据,存在中间数据方便,x-> Z -> Y 这样的映射数据,
那么将端到端任务分解成两个小任务,会更简单
比如下面的人脸识别和根据手X光图片判断儿童年龄,自动驾驶,但如果是机器翻译就比较适合端到端