异常检测
异常检测是机器学习中一个重要的概念,它是指在数据中检测出不符合预期的数据点,以便及时发现和处理异常情况。
检测方法:密度估计
密度估计是异常检测中的一种方法,它通过计算数据的密度分布来识别异常数据点。
通过将特征值的可能性进行乘积计算,得到数据的密度,然后跟阈值进行比较,判断当前数据是否正常。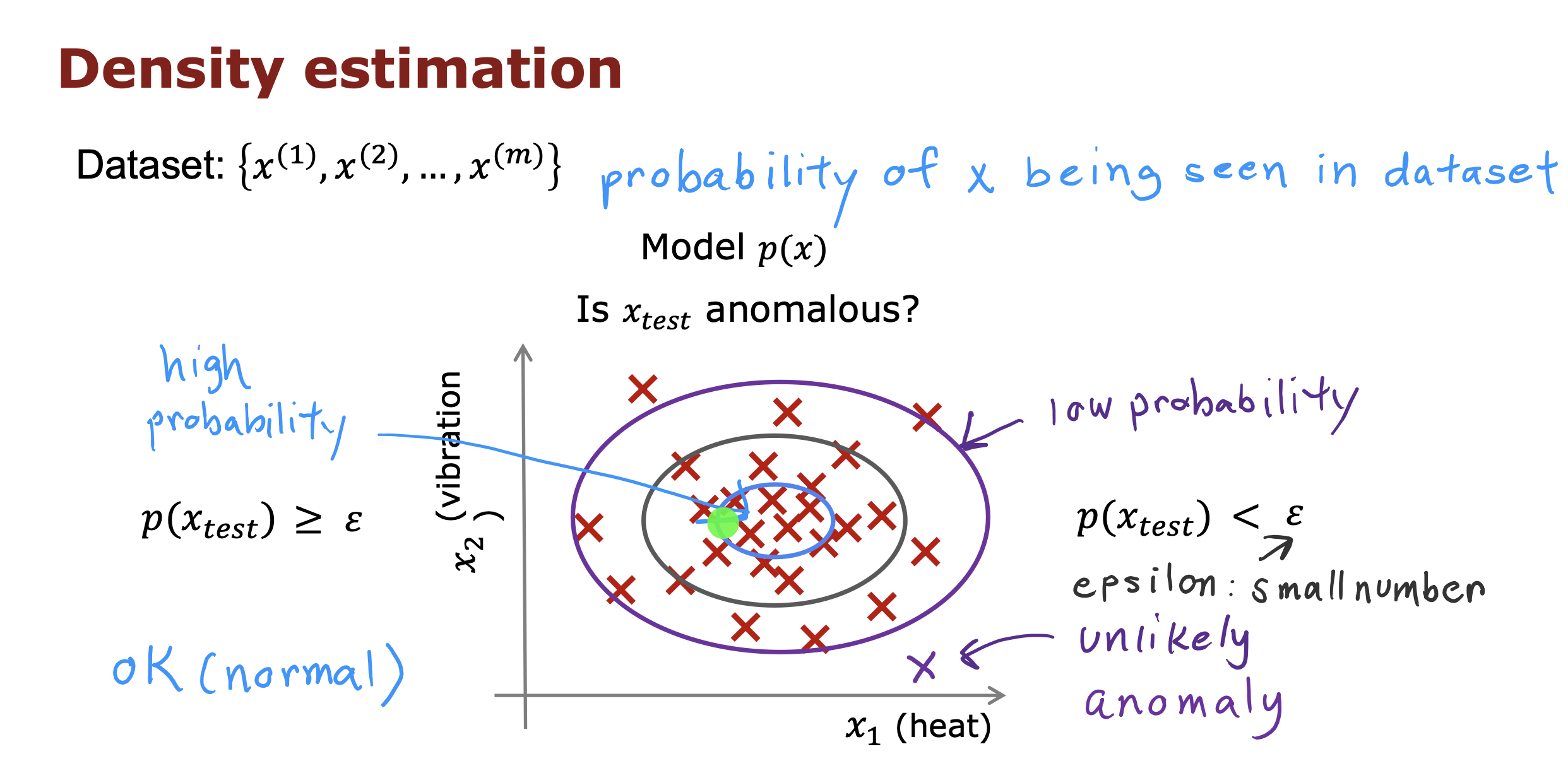


高斯分布
高斯分布的位置受数据集的平均值𝜇和方差𝜎^2 决定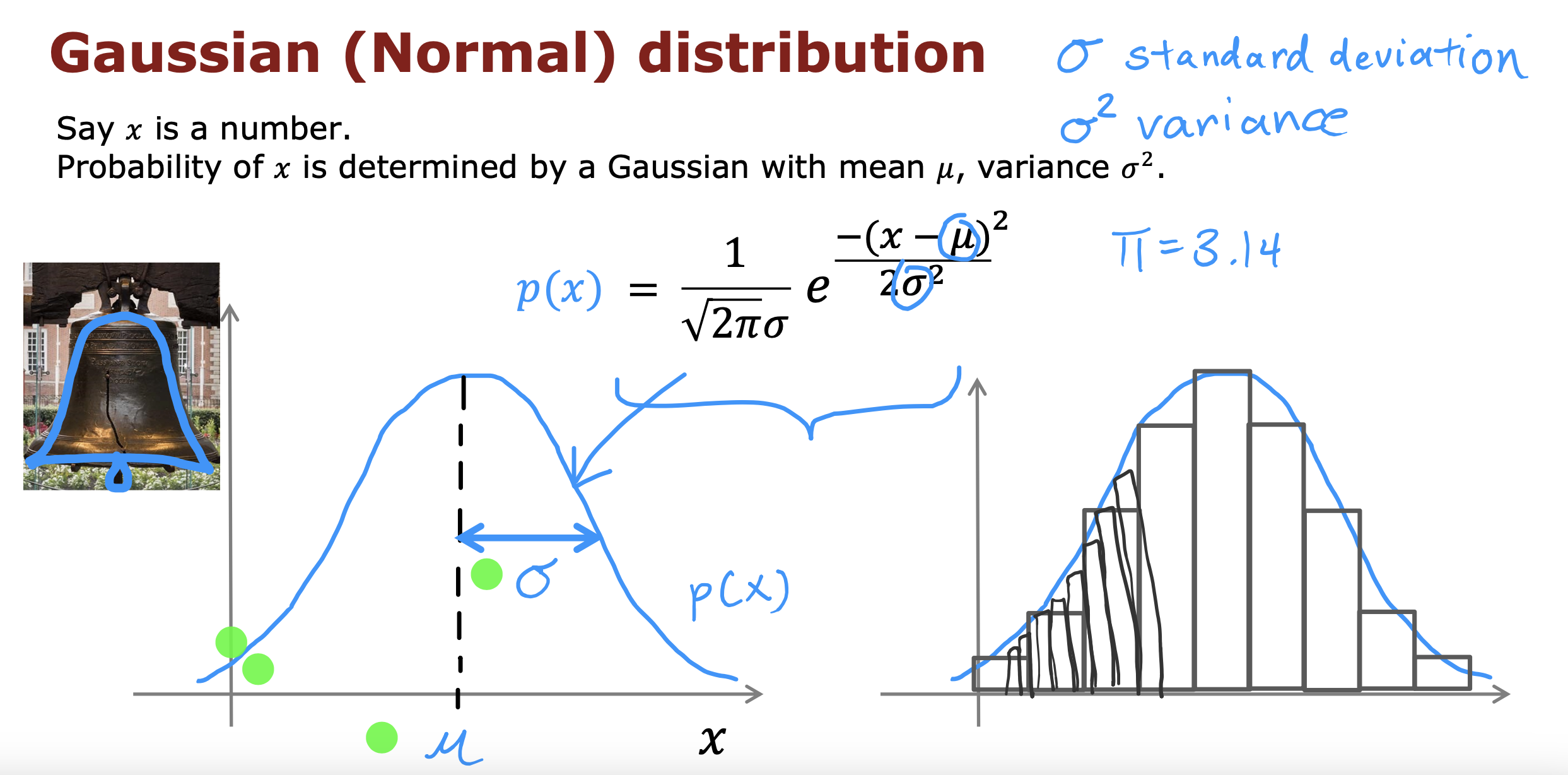
𝜇 决定钟形最高点在x轴上的位置
𝜎^2 决定钟形的宽度,因为整个钟形面积为1,所以,如果𝜎^2 变小,那个整个钟形会变得很高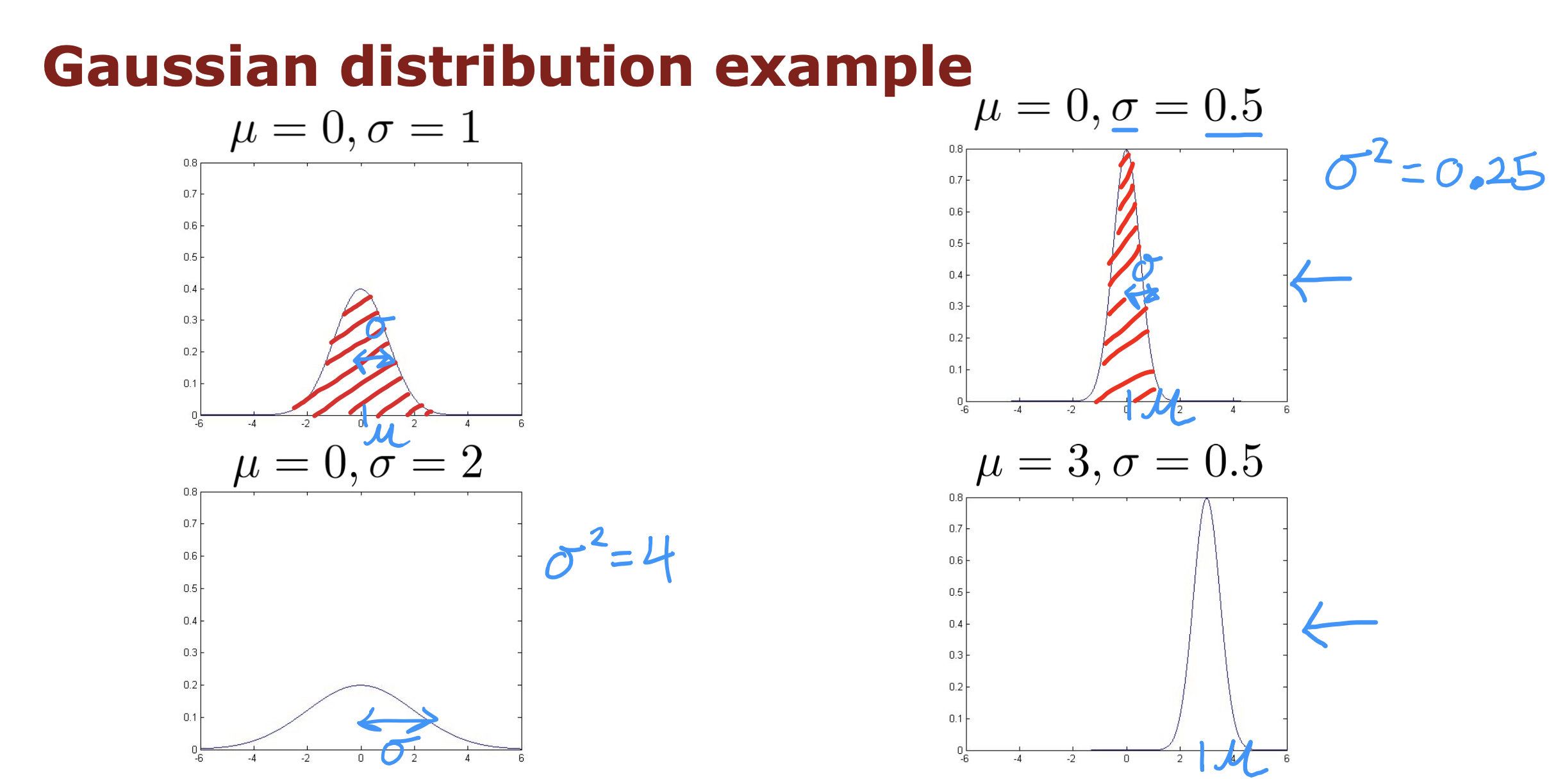
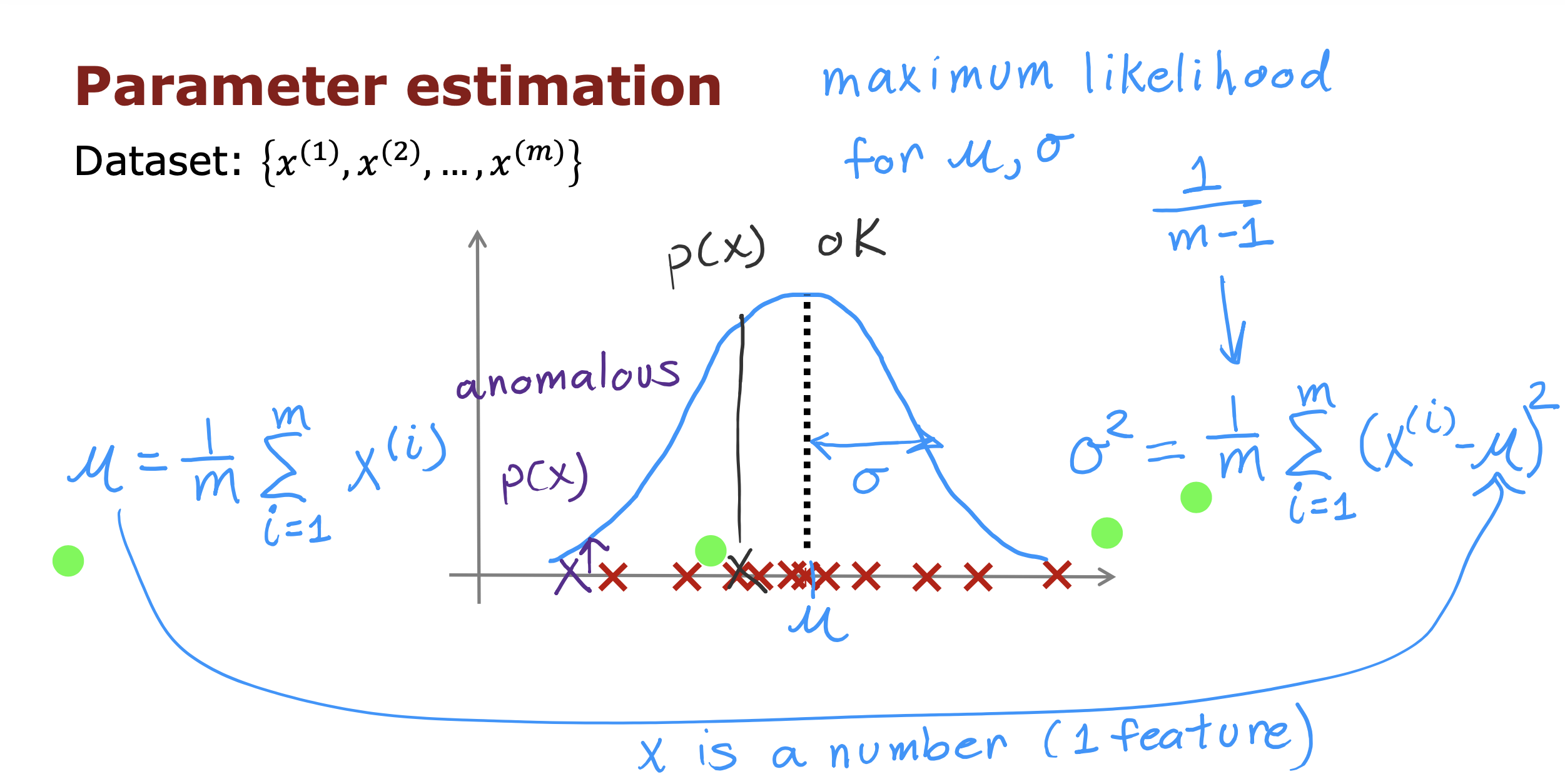
异常检测算法步骤
- 在训练数据中选择你认为可能会引起异常的数据的n个特征值
- 计算各个特征值的平均值𝜇和方差𝜎^2
- 计算每个特征值的密度,如果密度小于阈值,则认为是异常数据

开发过程中如何评估异常检测系统
通常采用实数评估方案,就是可以用一个具体的数值小小来衡量算法的好坏
假设训练数据中的数据都是正常的,存在标签0
在交叉验证和测试数据中,存在少量异常数据,标签为1
测试算法好坏的标准就是能否将异常数据识别出来
如果是特别少量的异常数据,可以仅通过交叉验证来评估测试好坏
从而决定合适的阈值大小

另外的评估方法可参考二分类错误度量
相关的衡量指标,真假值,精确率,召回率,F1 score等
如何选择异常检测算法和监督学习
异常检测算法适用于
- 正常数据少量但是有大量异常数据
- 异常的特征值是未知的,且是多样的
监督学习算法适用于
- 存在大量异常和正常数据
- 有足够数据告诉算法什么是正常的数据,什么是异常的数据
将来出现的异常数据很可能是之前训练集中出现过的异常数据


如何选择要使用的特征
选择符合高斯分布的特征,如果不能拟合高斯分布,可以通过取对数,开方等方式进行特殊处理后进行拟合
但要注意,训练数据如果有对特征值进行特殊处理,那么交叉验证集合测试集也要进行相同的处理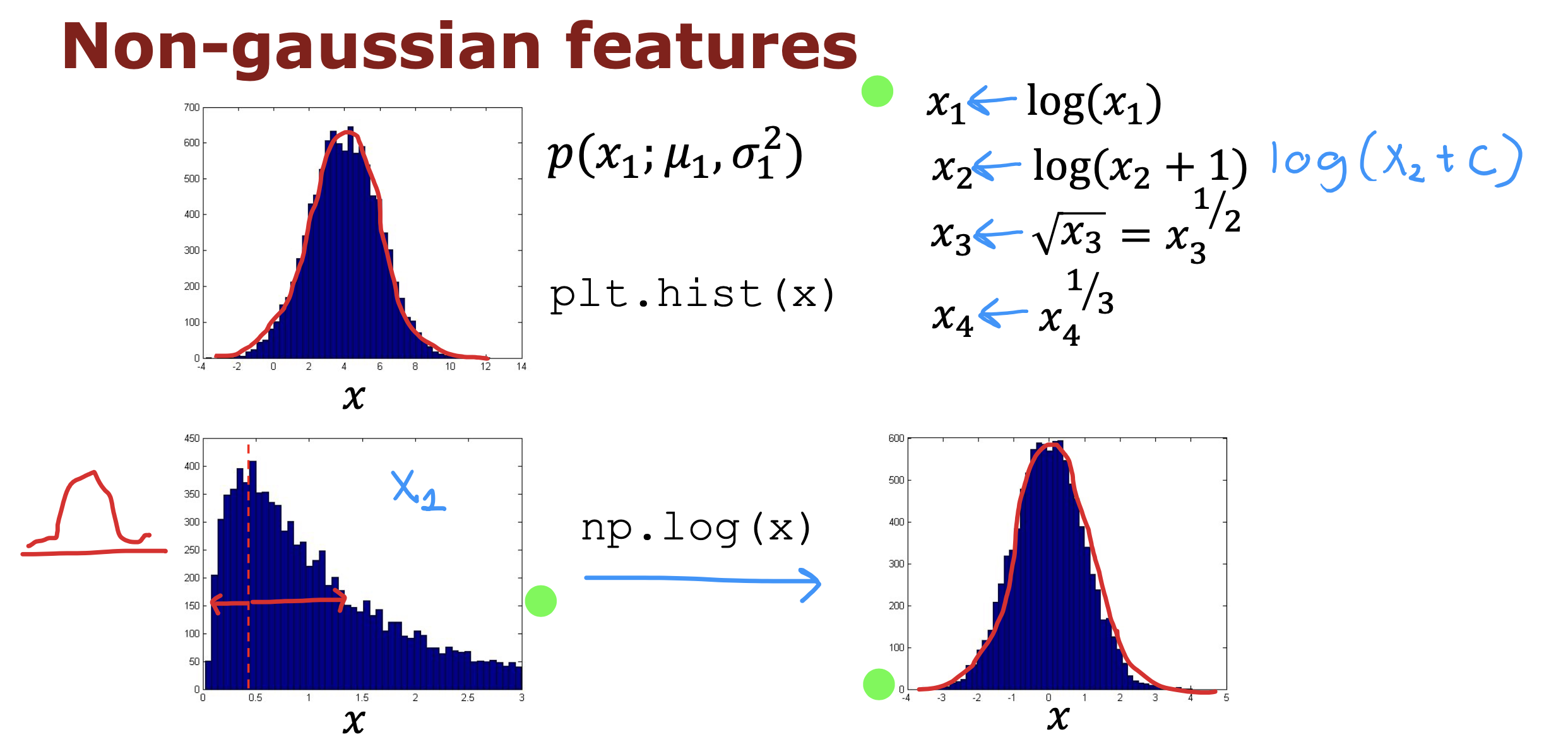
对于误判的异常数据,可以通过增加特征值来进行弥补,保证数据在新加的特征值上存在异常大或者异常小的数据
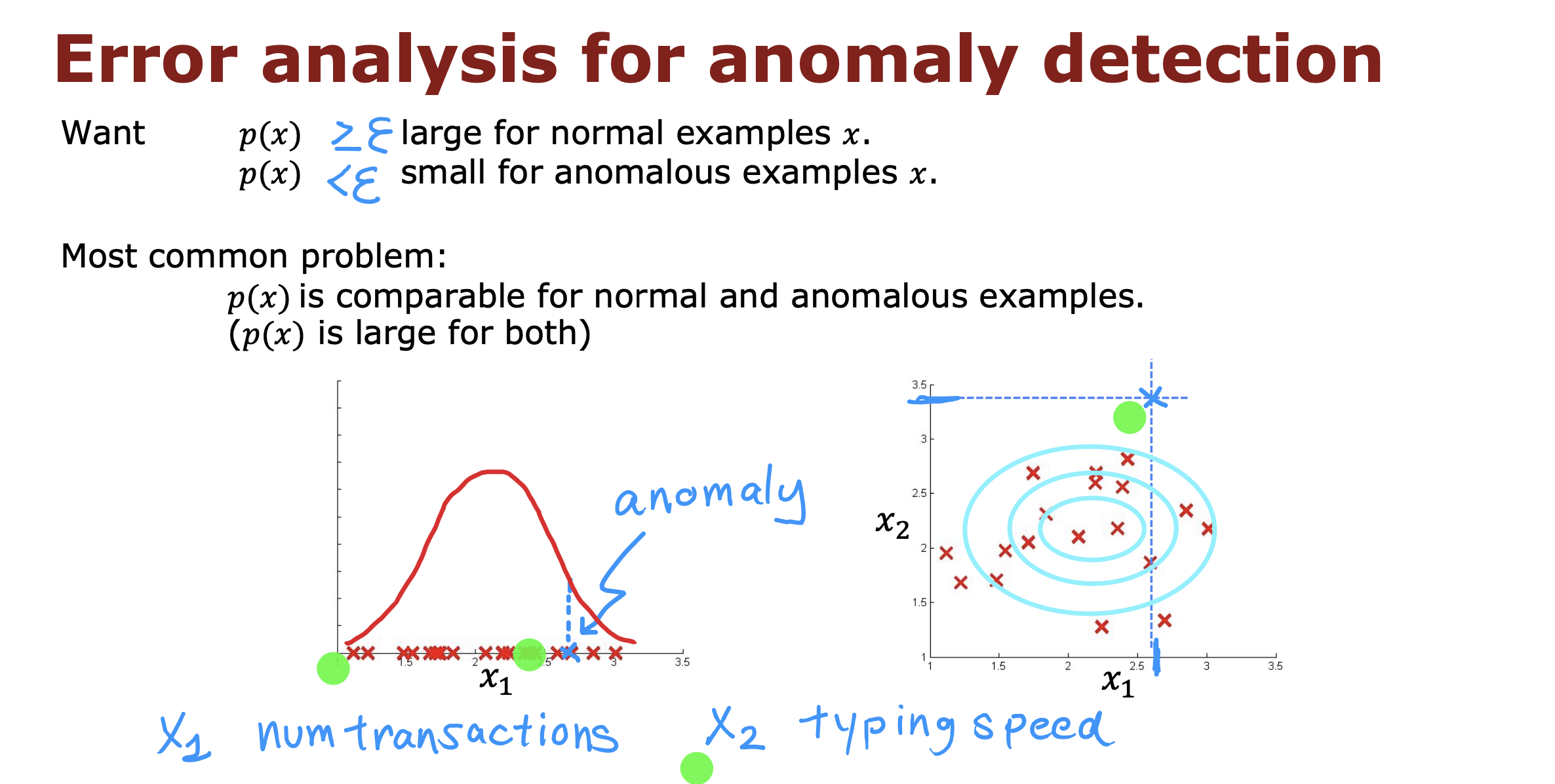
- 可以在已有的原始特征值基础上创造新的特征值参与运算
