无监督学习算法一
什么是聚类
将输入数据分成多个类别,每个类别包含一组相似的数据点的过程就是聚类,分好的类被称为cluster
聚类算法k-means处理过程
- 随机选择k个点作为初始的中心点, 计算每个点到中心点的距离,将每个点分配到距离最近的中心点所属的类别中
- 计算每个类别的中心点(平均值),并更新中心点,重复步骤1
- 直到中心点不再变化,或者达到最大迭代次数
具体实现(伪代码)


成本函数


如何初始化中心点
随机选择k个点作为初始的中心点(k小于m),计算最终中心点和损失函数
重复N次,选择损失函数最小的中心点作为最终的中心点
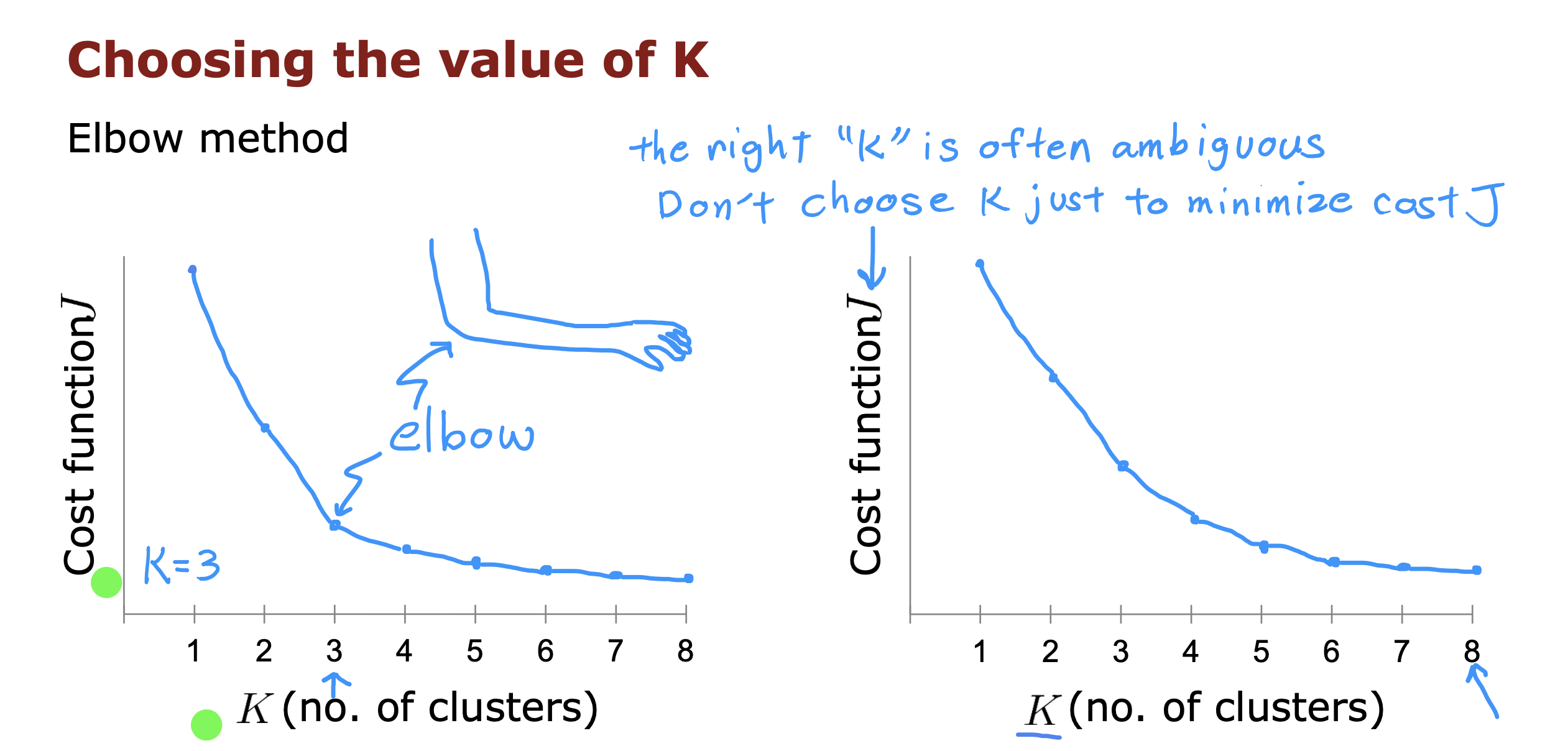
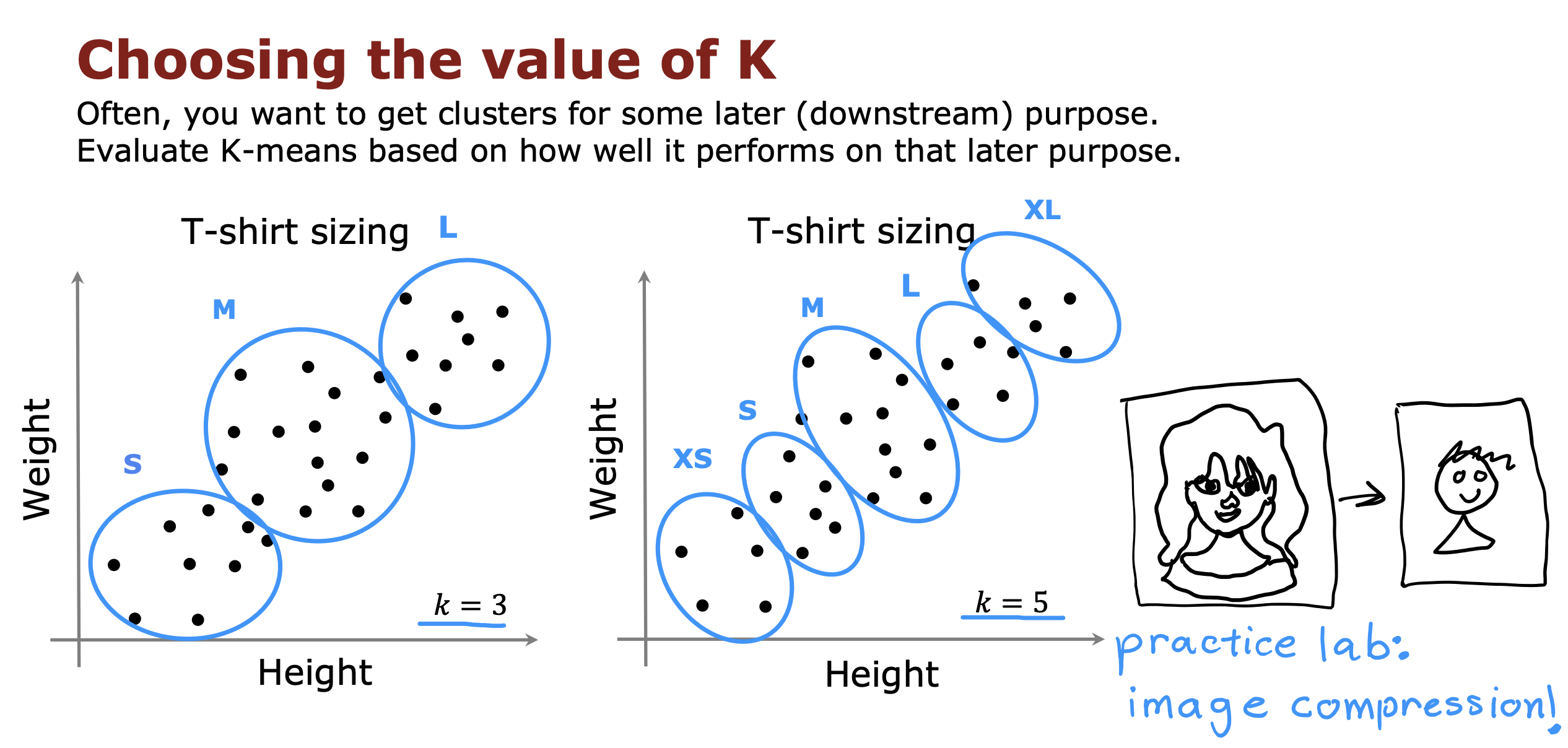
如何选择K的数量
取决后续如何使用分类好的集群数据