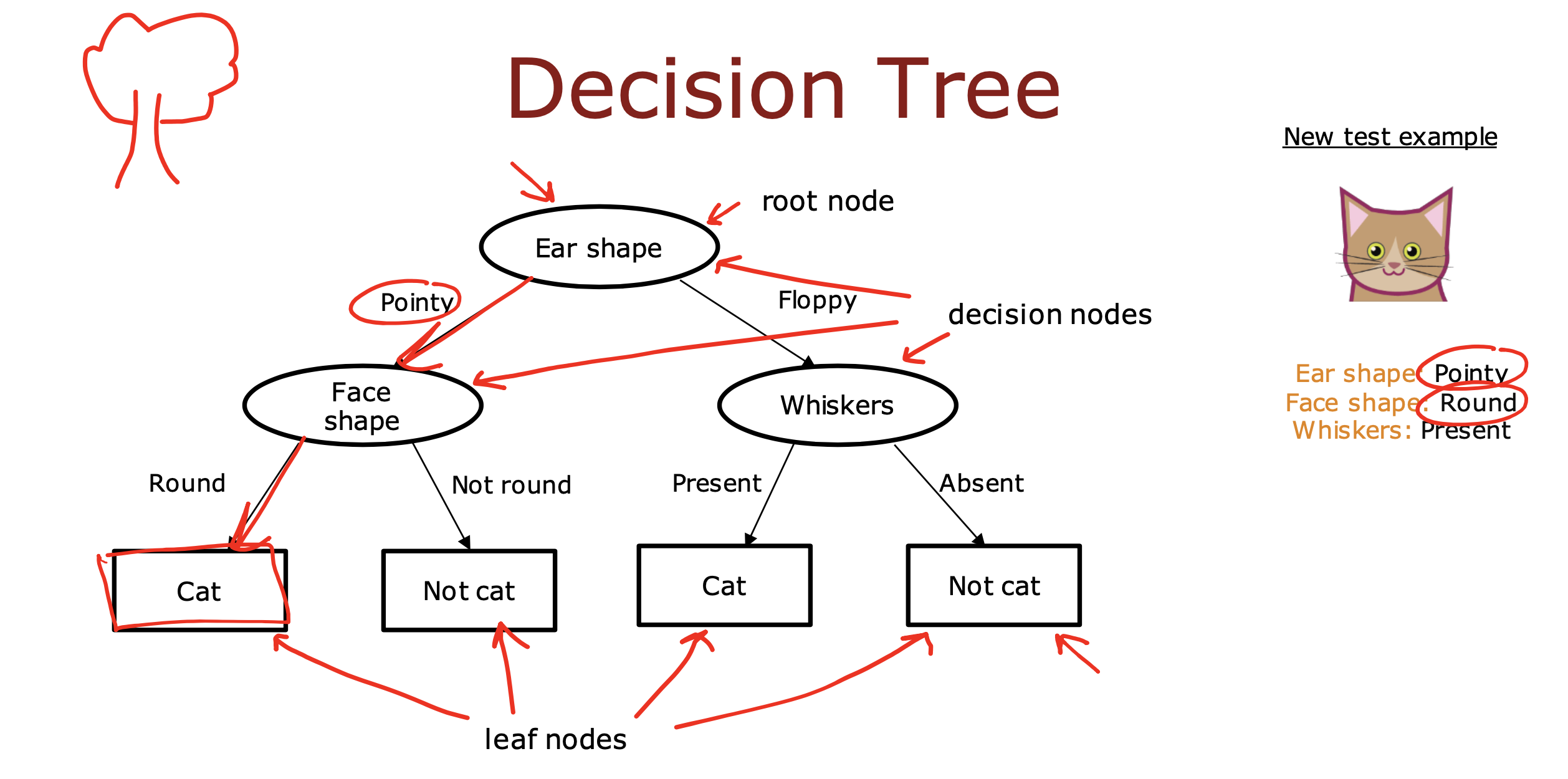
决策树模型是通过计算特征纯度后,选取最大纯度值的特征作为决策节点,
将数据根据是否符合当前特征节点一份为二,再根据特征纯度,继续划分,
最后根据停止划分规则进行数据分类或推测的模型
创建过程
决策树创建过程需要考虑两件事
在每个节点上如果选择根据什么特征进行数据分类
Maximize purity
如果一个特征在把数据分成两组之后,使分组后的数据能够最大程度的趋于同一类,那么这个特征就是纯度高的特征,
即 如果这个特征能够直接决定数据属于哪个分类的程度越高,纯度就越高
比如用DNA特征判断猫狗分类比用耳朵是尖的还是软的更直接,DNA特征就是最大纯度的特征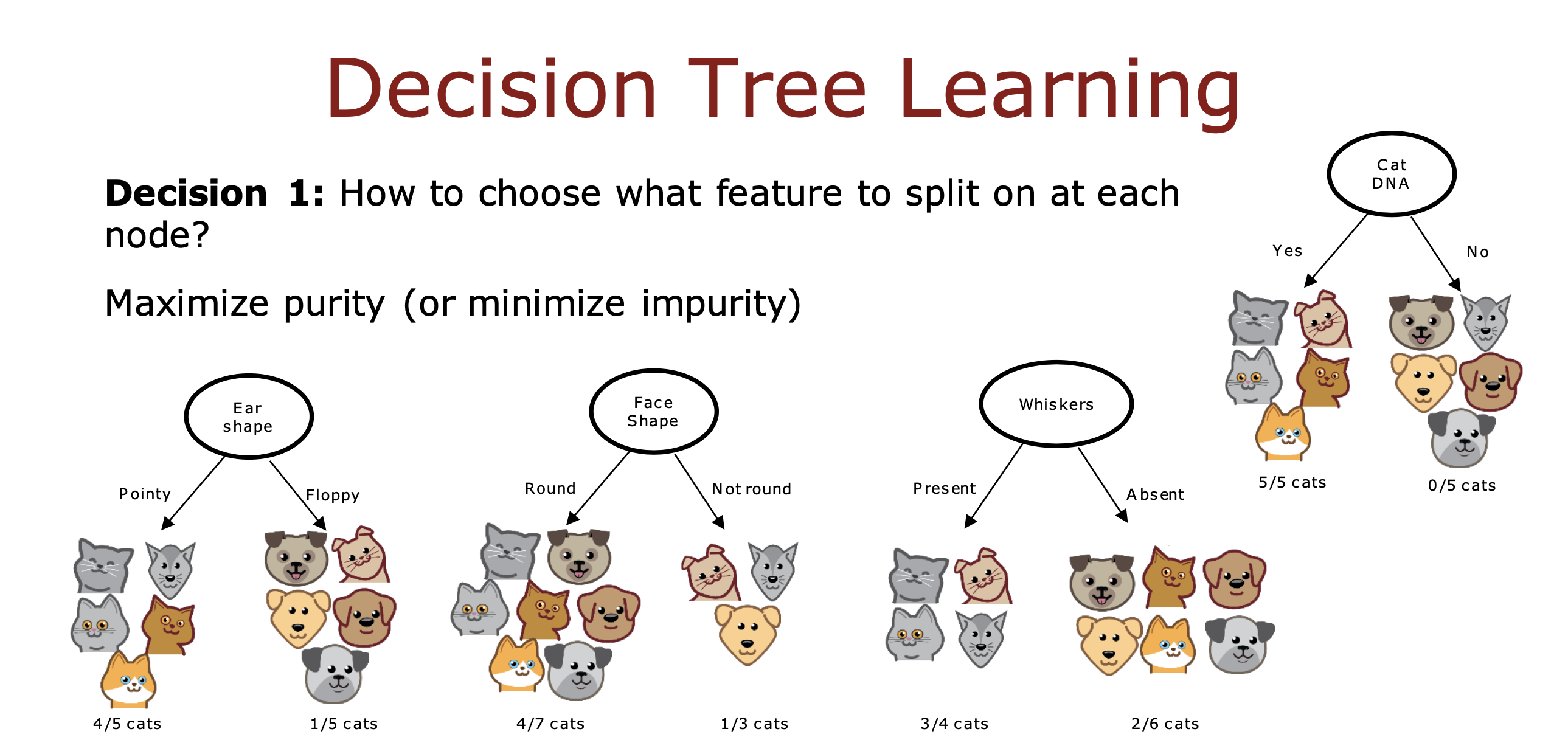
什么时候停止数据分类
a. 当一个节点里面的数据都属于同一类的时候
b. 到达树的深度最大值的时候,树越深,过拟合越有可能,计算成本越高
c. 当特征纯度(熵)低于某个阈值的时候
d. 当节点里的数据个数低于某个阈值的时候

熵
可以理解为数据的混乱程度,如果数据特别混乱,则值越大,返回数据如果种类单一,则值越小,趋近0
这里用熵来计算特征的非纯度或者较杂质程度,
如果根据某个特征分类后的数据的熵 越小,说数据越干净,杂质越少
反之,如果得到的熵越大,说数据越混乱,不同类的数据越多
如下面判断是否是猫的问题
p1 代表是每组数据中猫的比例,都是猫或狗的话熵 是0,5:5 的时候熵 最大值为1,数据最混乱
具体熵 的计算公式如下
信息增益
在了解熵的含义后,用下面的计算过程选择节点的判断特征
根节点的熵减去分类后两个节点熵的加权平均值,值越大说明分类后数据越纯了
这个计算方式得到的值就叫信息增益
即特征信息增益越大,在分类过程中,能够把数据分的越纯
小结
决策树学习过程
对于每个节点,都要像对待根节点一样
根据拿到的数据先找到最大信息增益的特征然后进行分类
整个过程就是一个递归的过程,直到满足停止分类的规则为止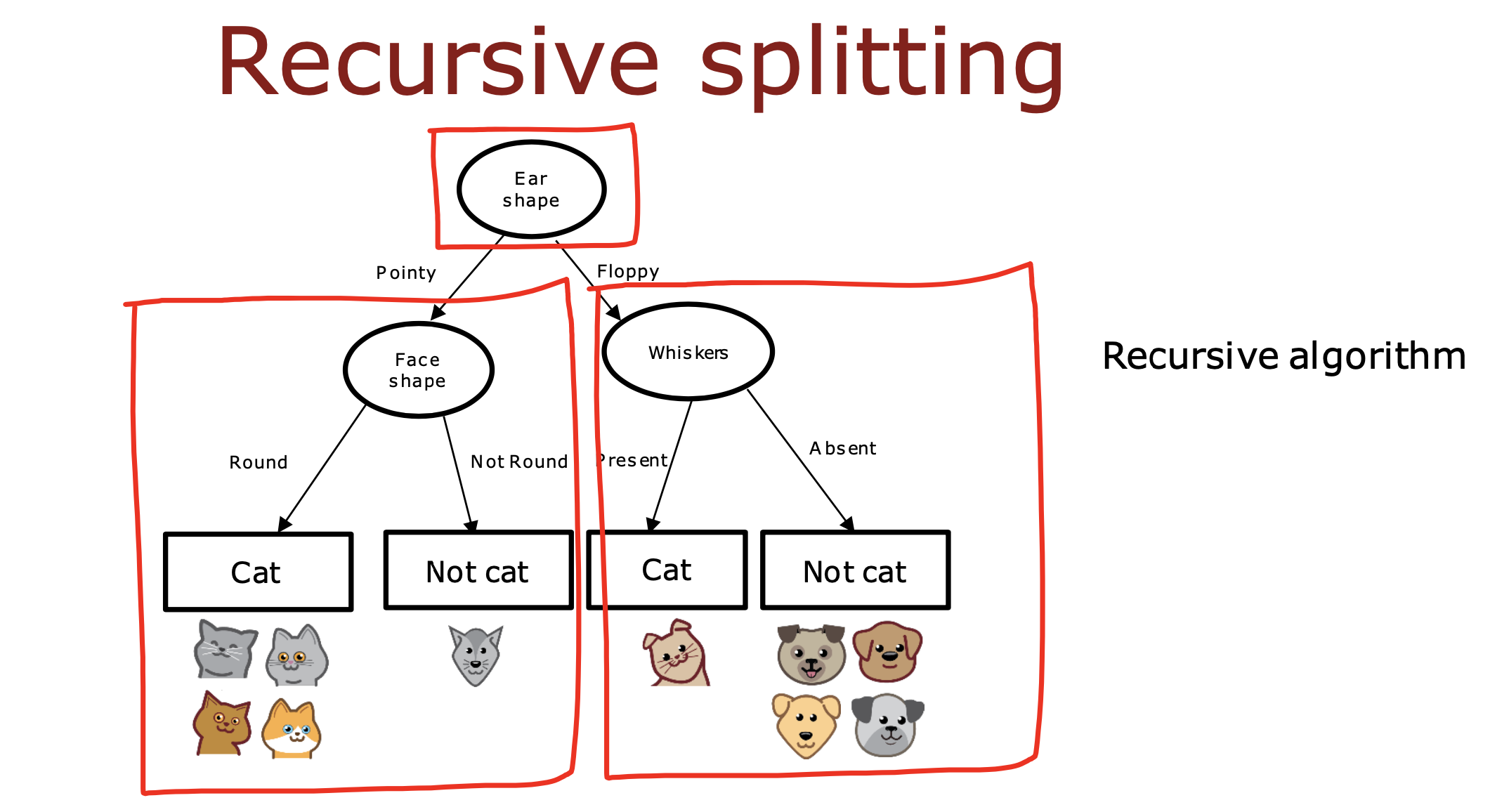
多特征值处理办法
one-hot
If a categorical feature can take on 𝑘 values, create 𝑘 binary features (0 or 1 valued).
如果一个特征有大于2个以上的N可枚举值,那么将当前特征拆分成N个新的代表相应枚举值的特征即可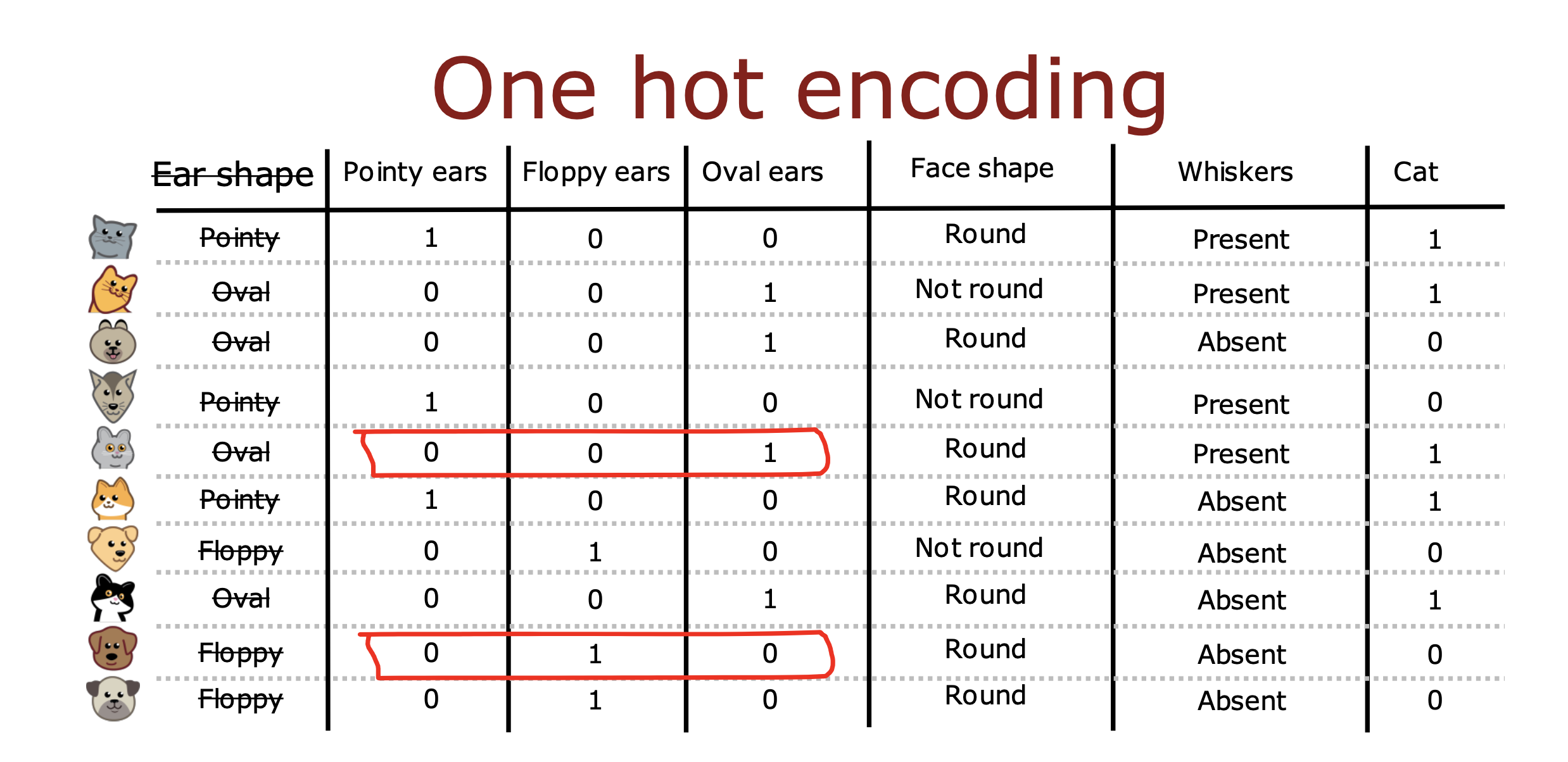
连续值
如果一个特质的值是连续值,不可枚举,那么需要设定一个阈值,大于该阈值一类,小于则是另一类,从而实现对该特征的二分类
阈值的选取还是通过计算信息增益,选取能够使信息增益值最大的阈值参与分类
一般情况下先对所有数据按这个特征值排序,然后选取排序列表中两个数据间的中点做阈值进行信息增益计算,
多轮计算后再从中选取信息增益最大的阈值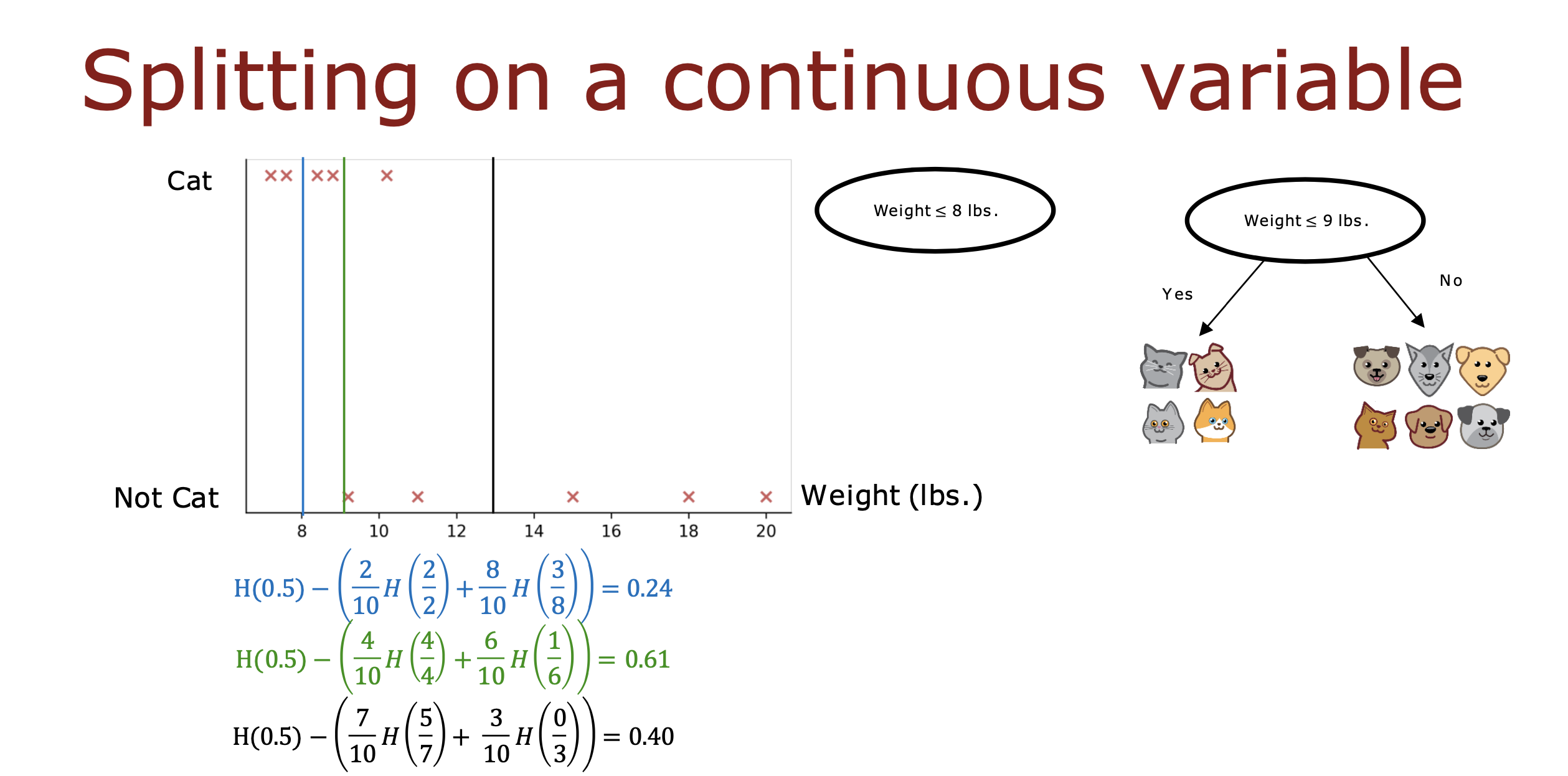
回归树
上面是使用决策树进行分类计算
接下来使用方差对连续数据进行推测,就是回归树
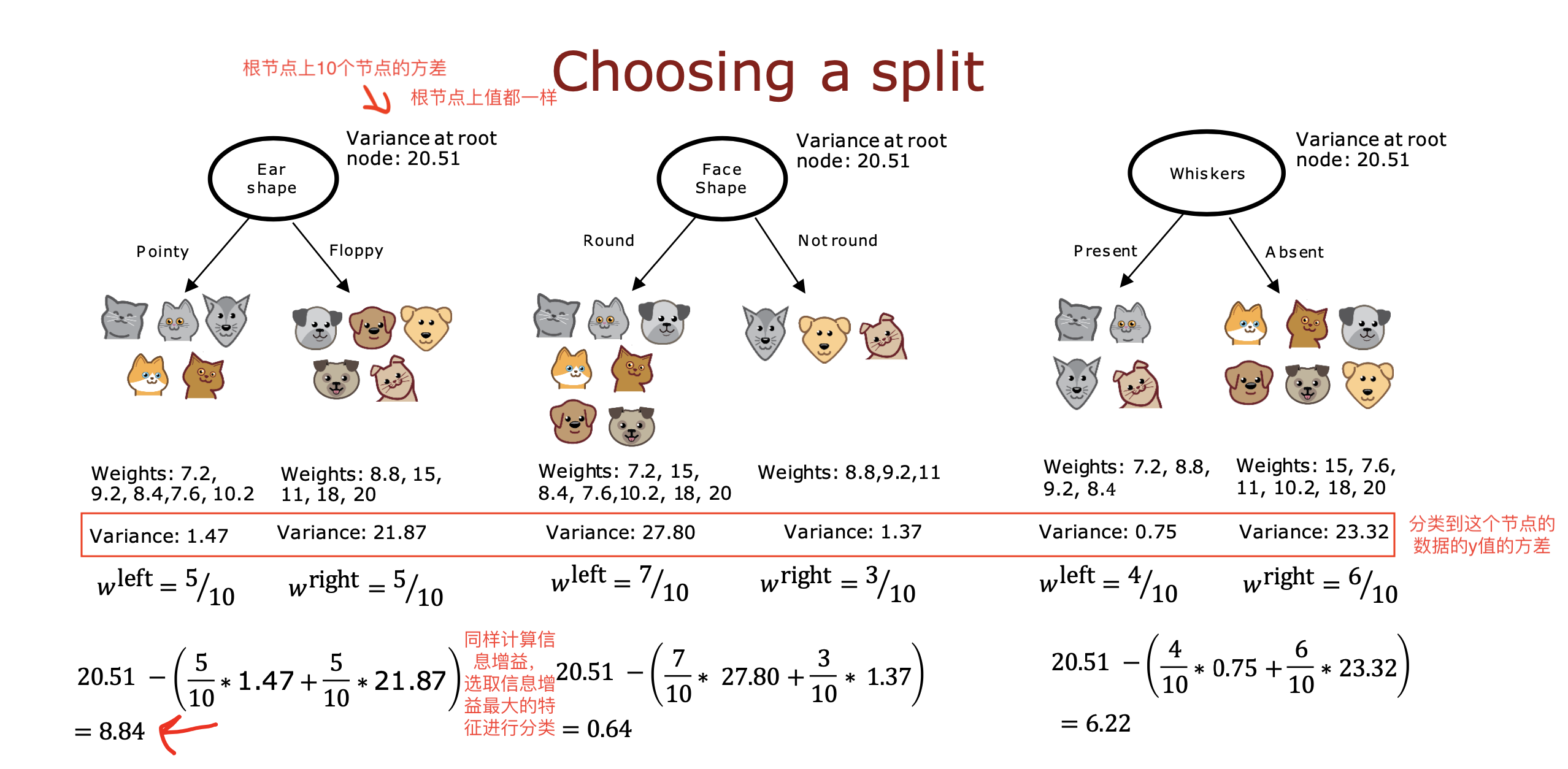
如下图,根据前三个特征,推测weight 的值,weight 是个连续的值,不能枚举的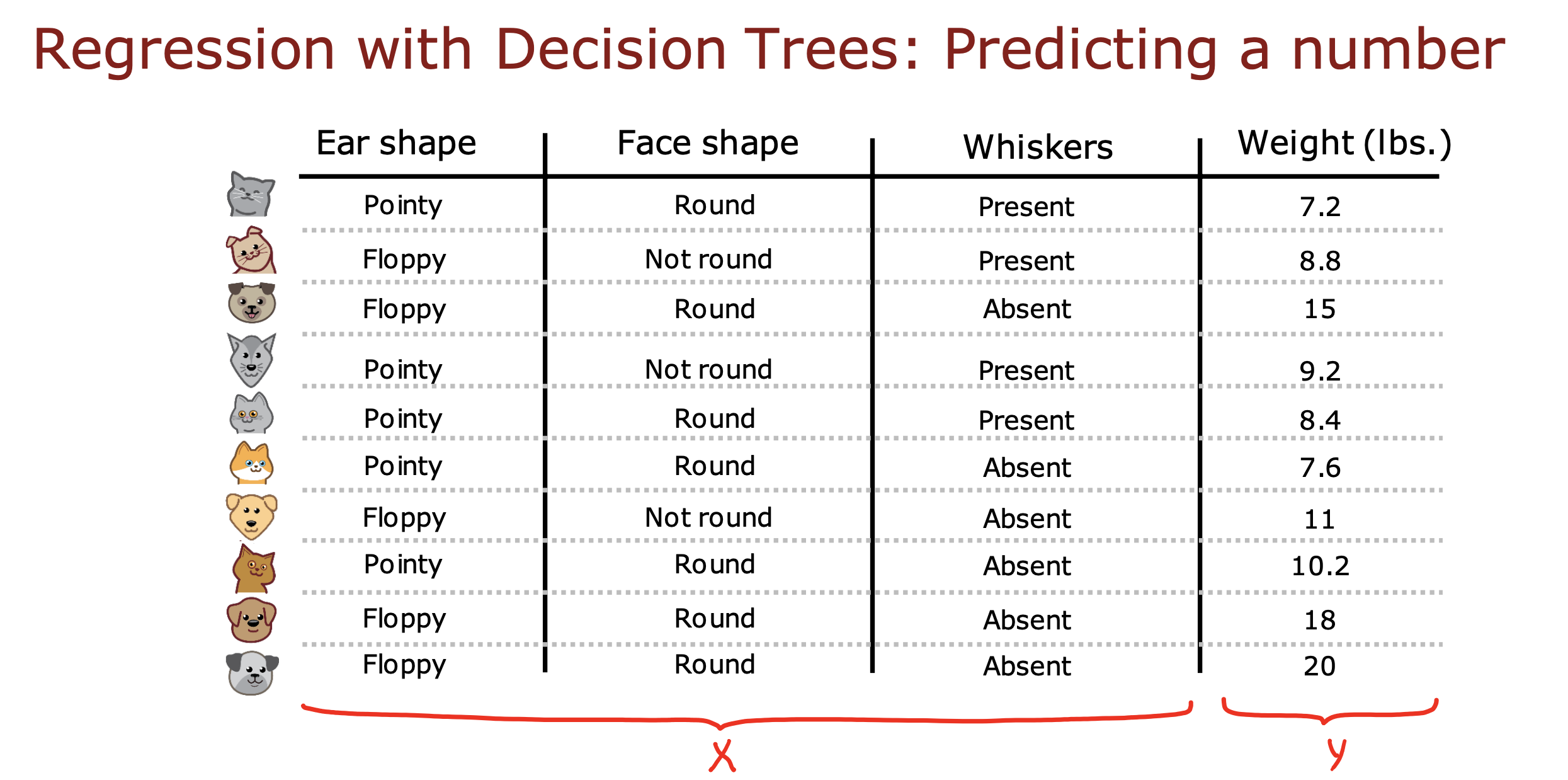
多个决策树
单个决策树对训练数据非常敏感,只要更改一个训练数据,就有可能更改信息增益排序,
从而影响节点特征选择,进而导致整棵树发生变化,使得算法失去健壮性
解决办法就是构建多个树,让他们投票最终的预测结果,使整体的算法对任何单个树可能在做什么不那么敏感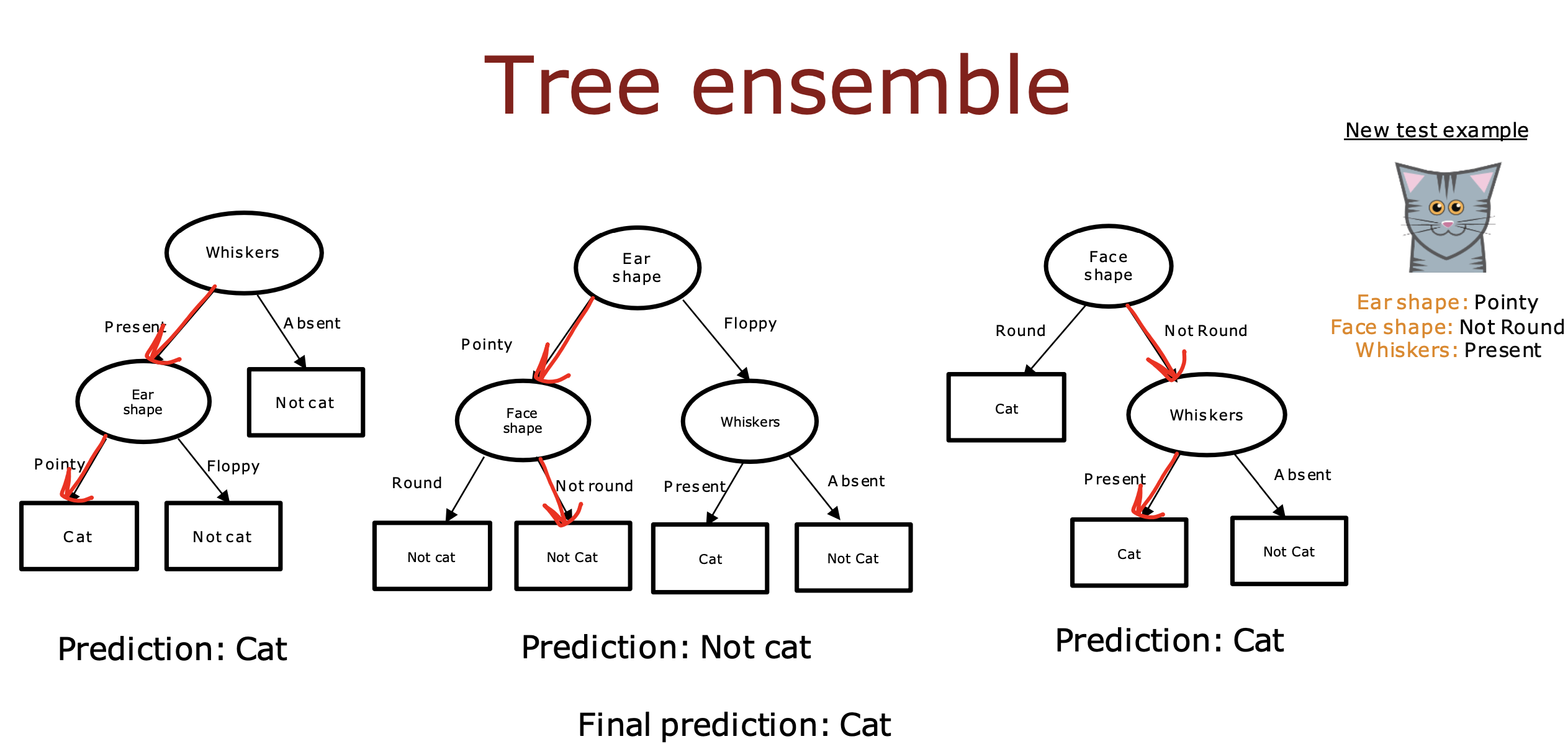
放回抽样
一共有m个训练数据,每次从m个数据中随机抽取1个数据,直到抽取到m个数据,抽取到的数据可能是重复的
随机森林算法
使用放回抽样的数据选取方法,每次拿到m个训练数据,用这个m个训练数据训练决策树,重复 B(小于100)次,
得到B棵决策树,从而形成决策树森林对预测结果进行投票,这种算法就是随机森林算法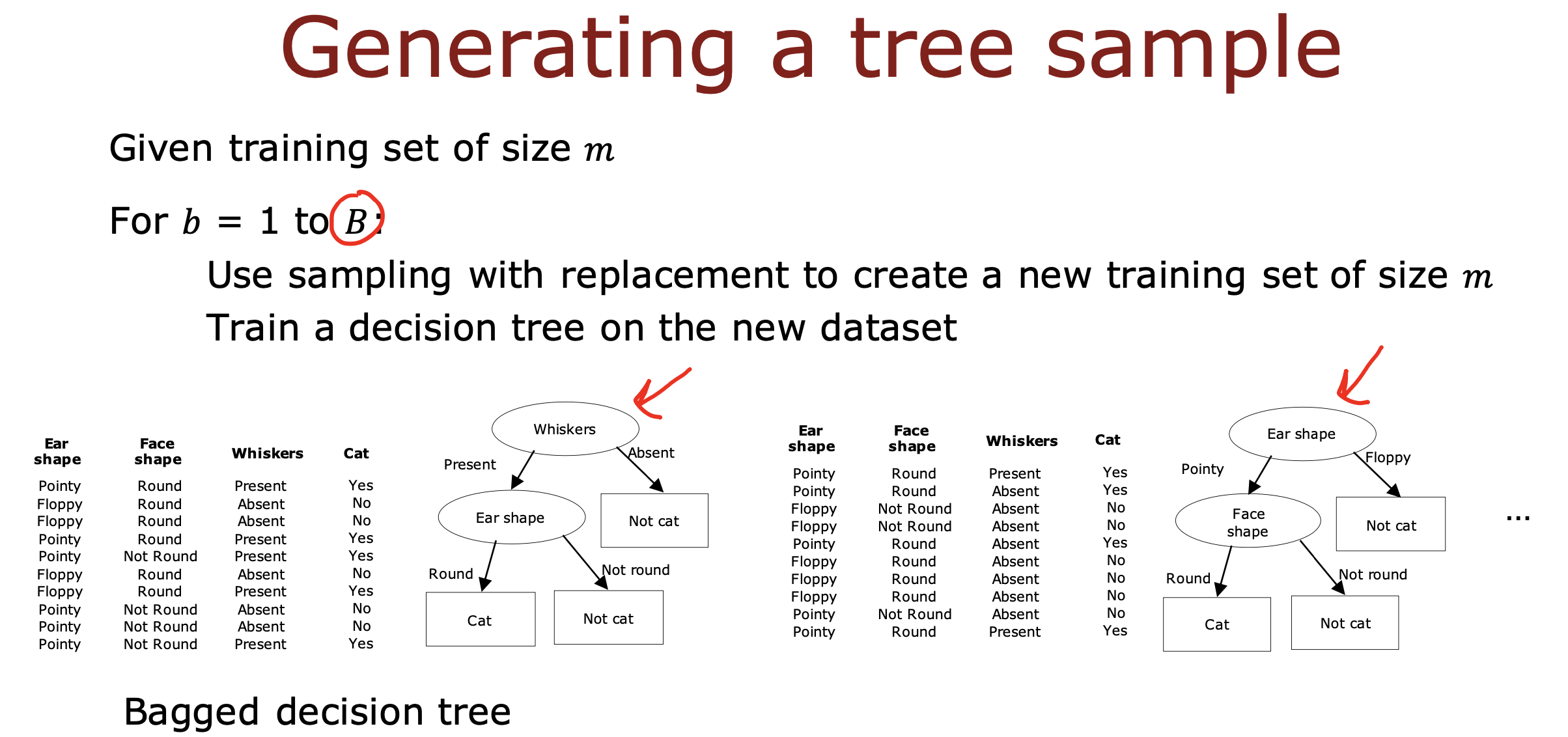
B 如果大于100 一个是训练效果会下降,推测准确性降低,另外一个就是会增加计算成本,使算法变得复杂,得不偿失
随机特征选取
对于具备N个特征的数据,通常选择N的K个特征子集进行训练,如果N特别大,K一般等于N的平方根
XGBoost 随机森林增强算法
除了第一次等概率的从m个训练数据中抽样new dataSet 外,后续的每一轮抽样,都将前一轮推测失败的训练数据的权重加大,
使被抽取到的概率变高,尽可能的将推测失败的数据参与到后续的训练中,从而推动算法更快的学习,并学习的更好,提高算法的准确性
这种算法又称为XGBoost 算法,是随机森林算法的改进版,优点如下

决策树 VS 神经网络

决策树& 决策森林
适合结构化数据(可以用表格表示的数据)
不适合非结构化数据(音视频,图像)
小的决策树可以被人类解释推测过程
训练速度快,缩短算法迭代循环周期,更快的提高算法性能
神经网络
对于所有数据类型都很友好,包括结构化和非结构化
训练速度比决策树要慢
但可以轻松实现迁移学习,但是决策树每次训练只能特定的特征,得到特定的决策树
方便构建多模型系统,神经网络间串联方便