下面以根据电影评分推荐电影为例,介绍推荐系统的开发过程
思路整理
根据电影的特征,用户对每个电影都会有一个评分(0-5分),比如电影A的评分是5分,电影B的评分是4分,电影C的评分是3分
一般情况下,用户对某电影评分越高,说明后续对该类型电影的青睐度越高,对于系统来说越值得推荐给用户
即系统需要预测用户对某个电影X的评分,从而决定是否推荐给用户
系统需要依赖的数据是电影的特征数据(X)和以往用户对电影的评分数据(Y)
根据二者的关系,计算出相关的算法参数
当有需要预测一个电影评分的时候,输入待评分电影特征即可得到评分,然后根据阈值判断是否推荐给用户
下面是对一个观众的电影评分预测过程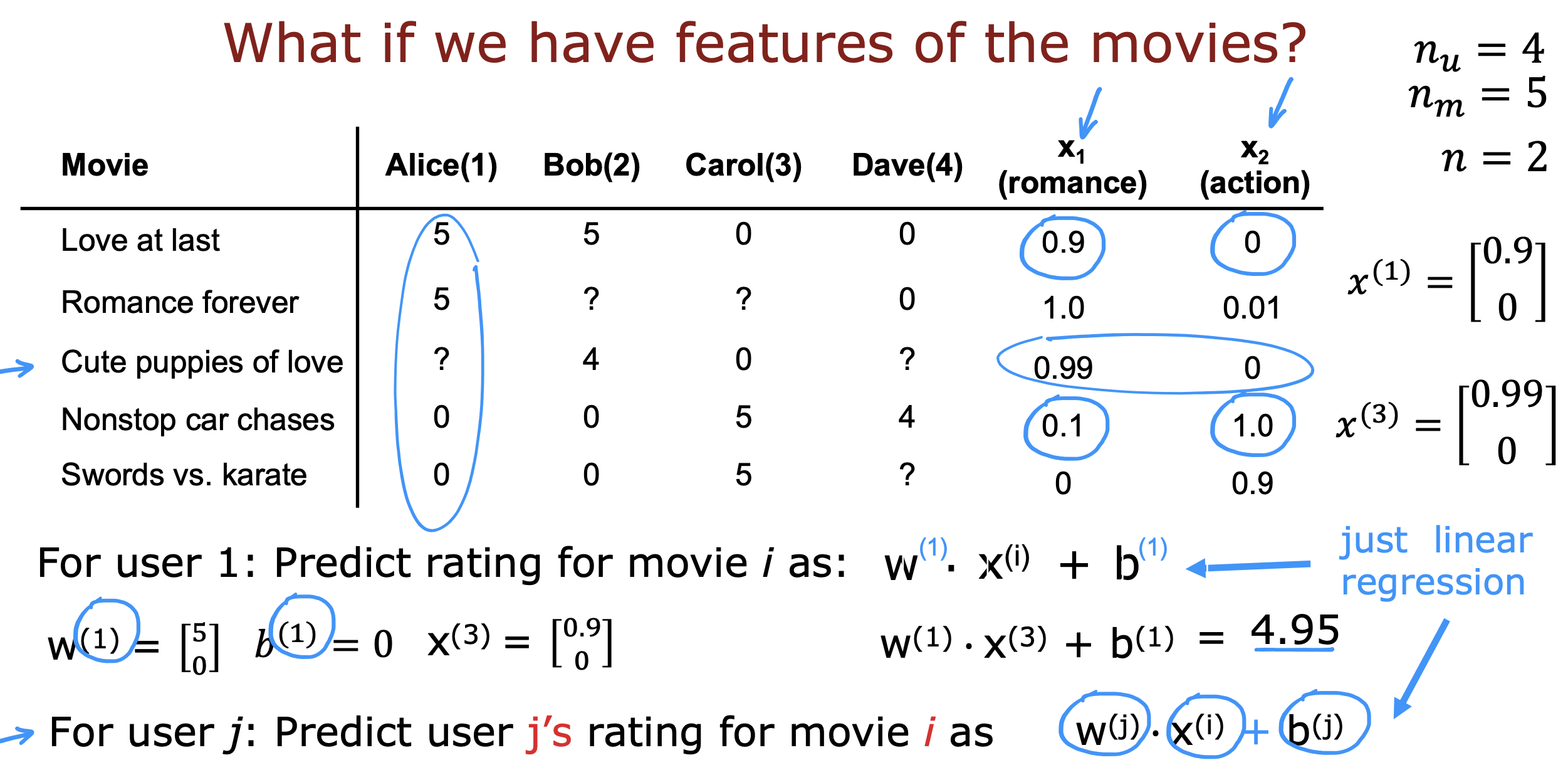
对应的成本函数
如果训练集有多个用户的评分数据,拿到所有用户的参数后加合,就可以预测大众用户对某个电影的整体评分情况
协同过滤算法
对于电影的评分,一开始不能确定使用电影的哪些特征,协同过滤算法将输入,电影的特征X, 也看做是一个参数参与成本函数的计算
从而利用梯度下降过程找到合适的参数和特征值
推导过程
- 已知多个人对一部电影的评分和相关参数,可以反推出X 的 情况
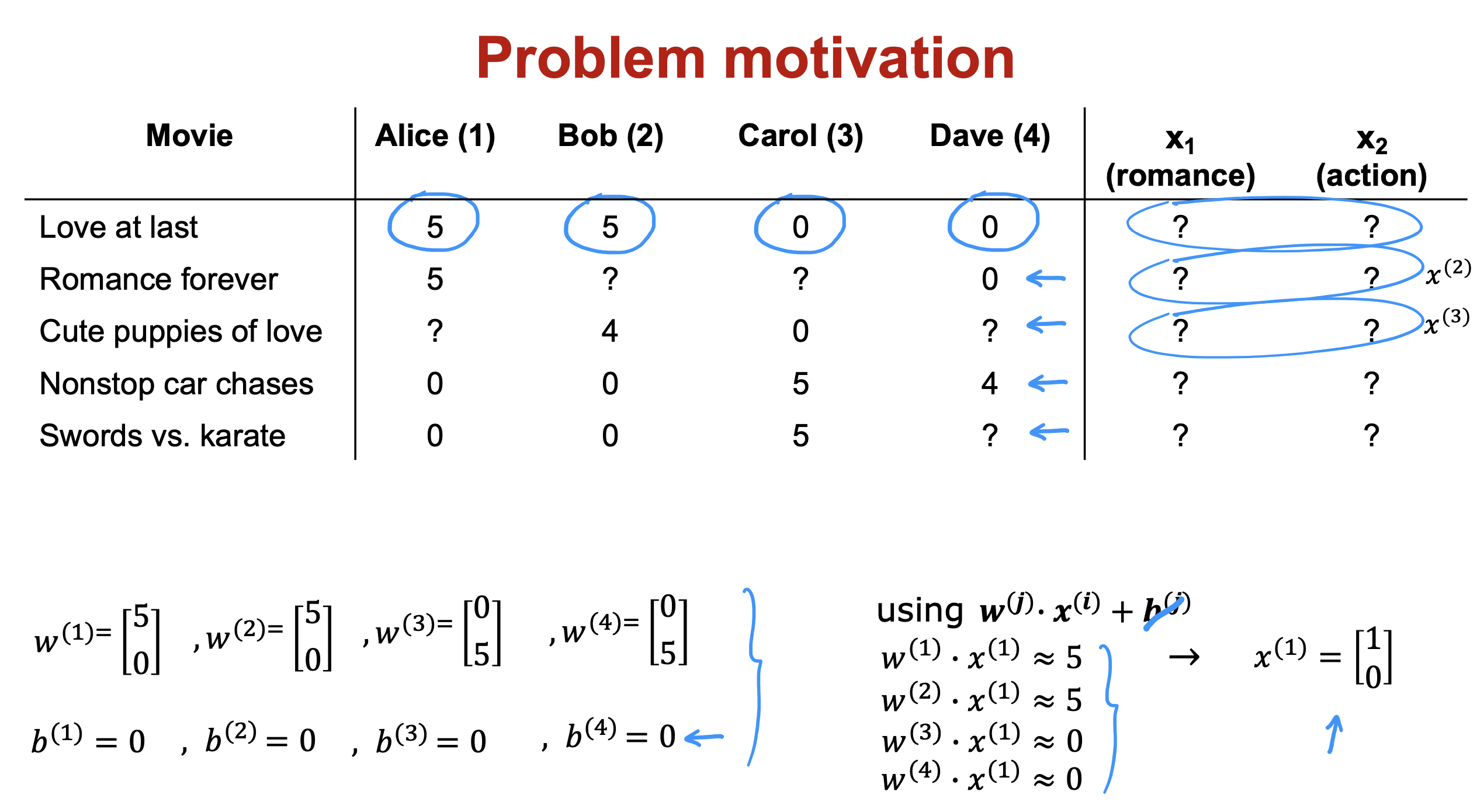
- 如果现在已知多个人对一部电影的评分和相关参数,可以对电影特征X进行成本函数计算
加和之后可以对多个电影的特征进行预测
- 观察成本函数的公式,现在加和参数和特征的成本函数,

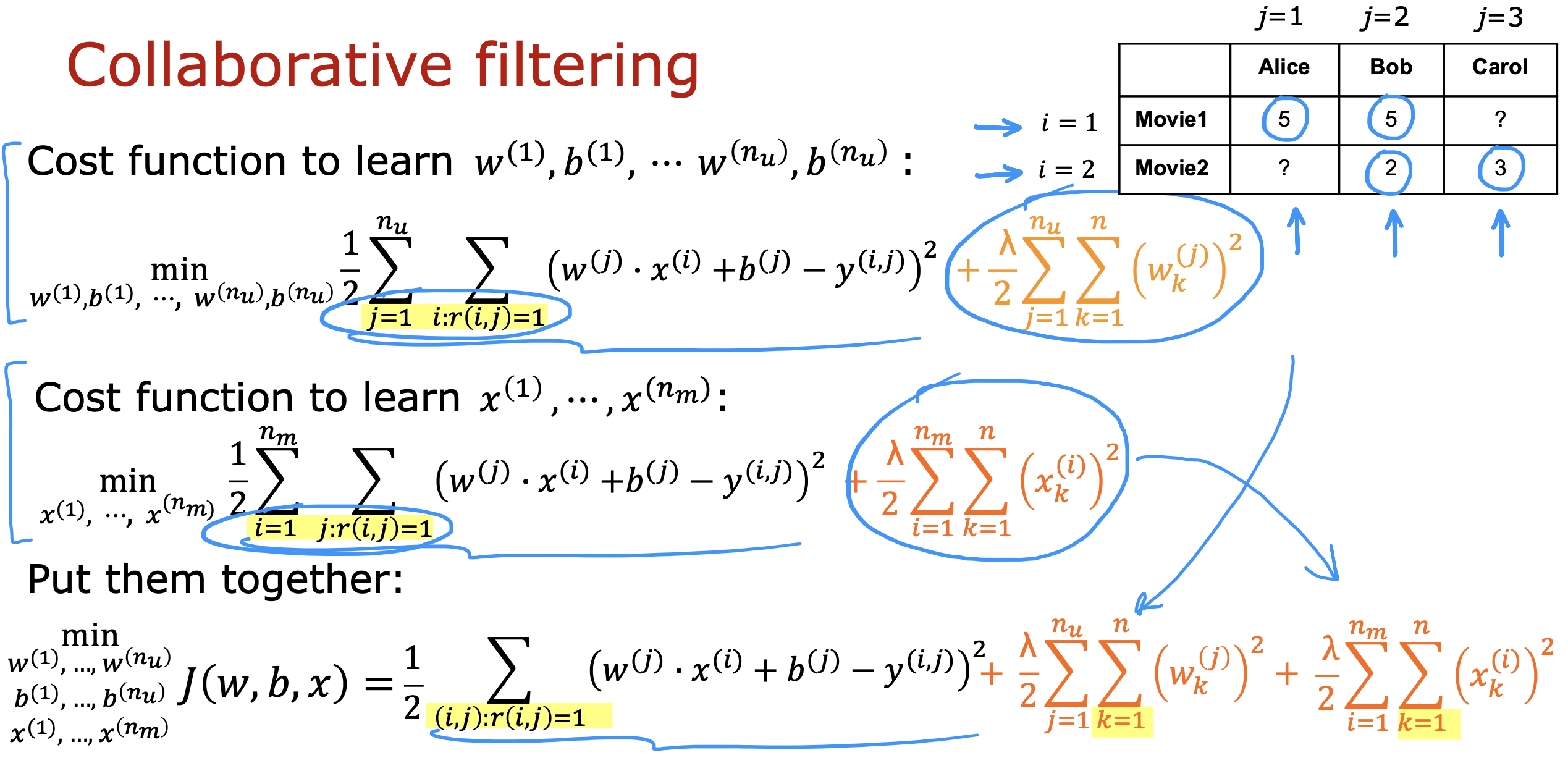
- 可以发现, 梯度下降过程,可以同时找出多个人对电影评分参数和对多部电影的特征值推测

协同在这里的体现在于多个用户对一部电影进行了评价,通过合作得到了对电影的整体评价,同时可以预测出能够代表这部电影的特征值
反过来,可以预测尚未对同一部电影进行评分的其他用户的评分
即从多个用户收集数据,然后预测其他用户的评分
线性回归转向二进制分类
基于线性回归的推荐系统适合于上面评分有连续值的推测,基于上述思路,将评分结果通过逻辑函数转成二进制结果
即可实现二进制分类问题的预测


优化
均值归一化
对于尚未对电影作为任何评价的用户,如果参数为0,那么预测的评分结果为0,会极大影响推荐的准确性
因此,先对多用户评分计算均值,然后对所有用户的评分减去均值,得到新的评分,在新的评分上进行参数获取
进行评分预测的时候再把均值加回来,这样即使参数为0,预测的评分值也是之前评分的均值,对整体评分meian值不会有影响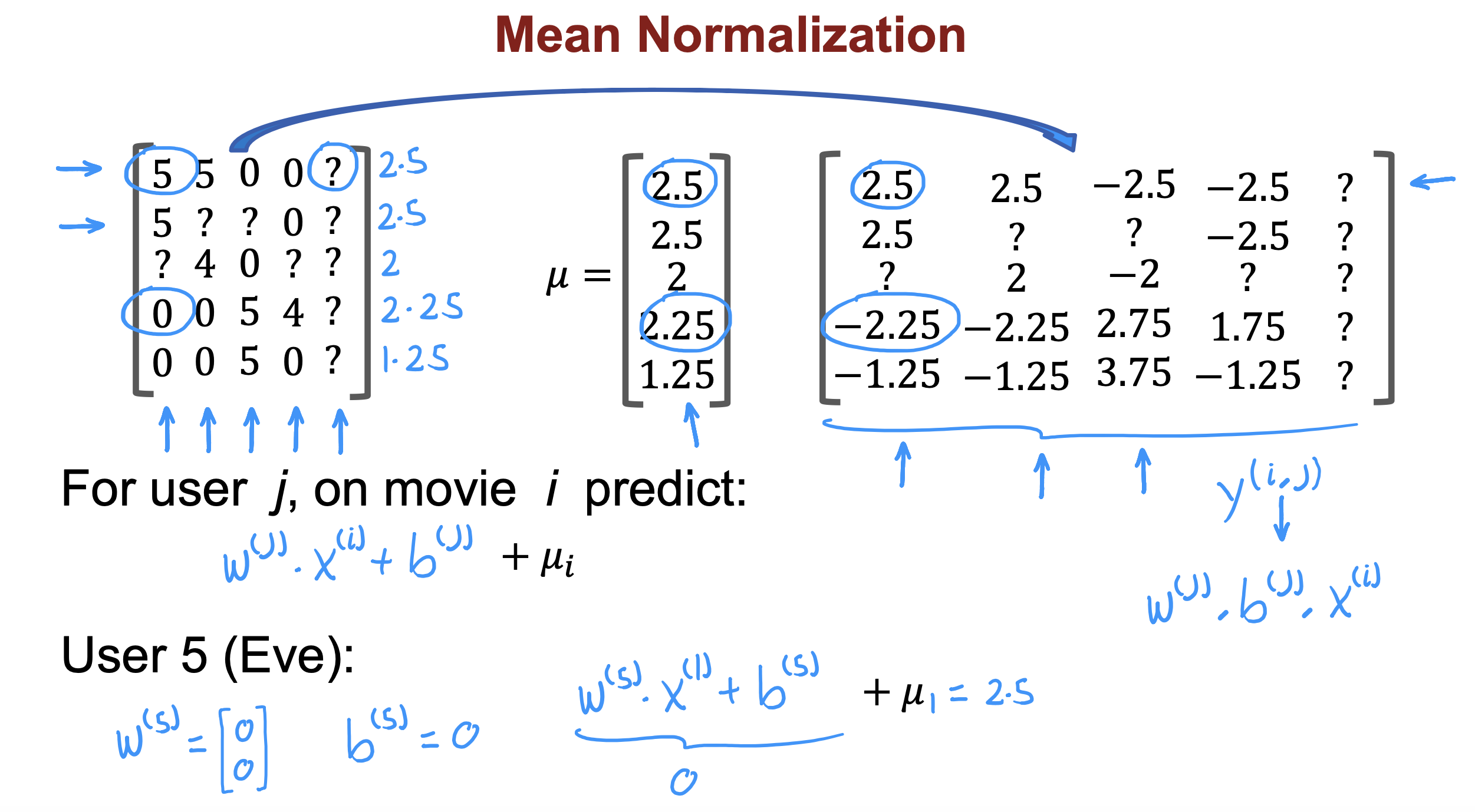
如何找到相似的推荐
找到与当前item 距离最近的其他item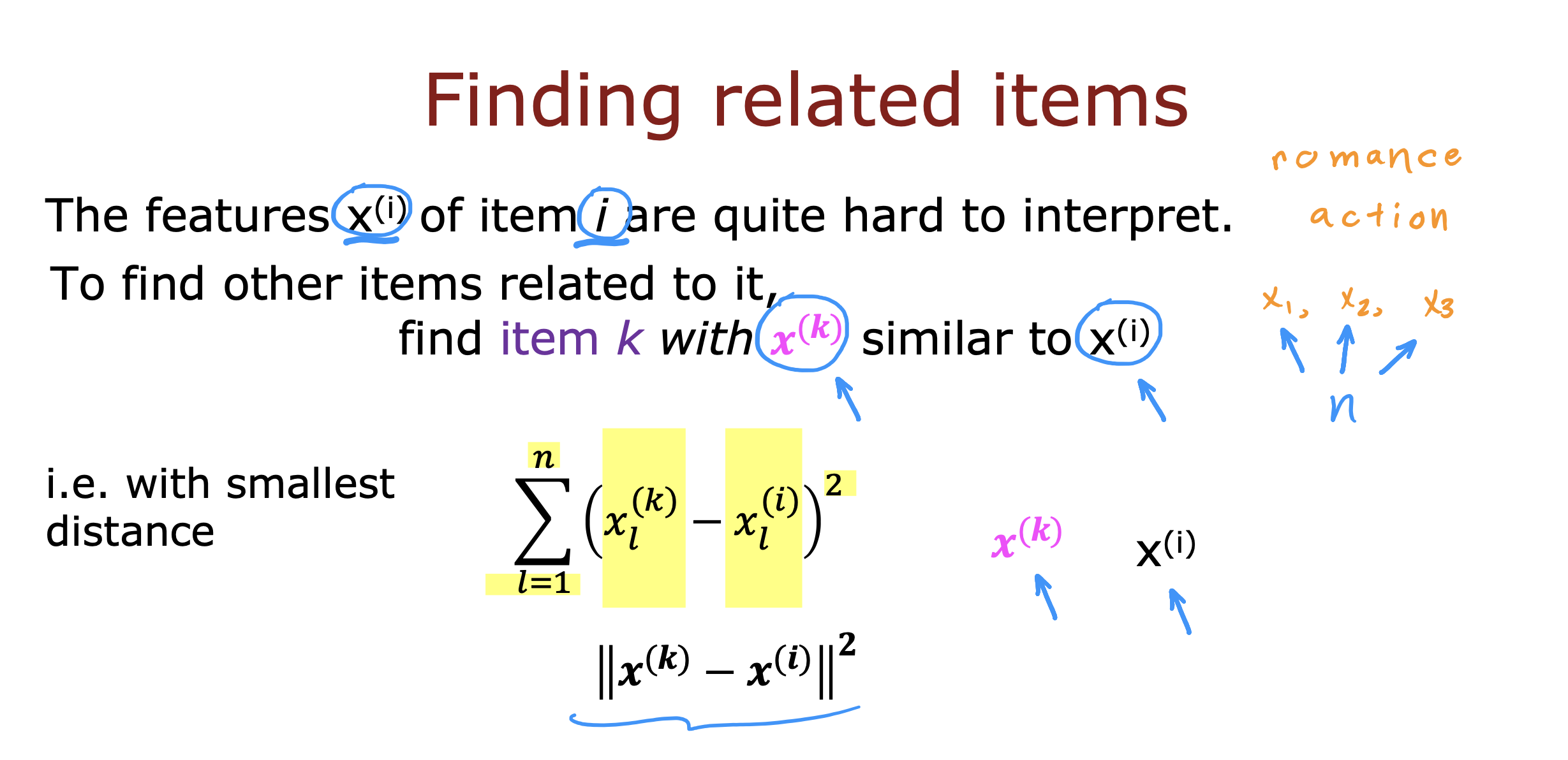
协同过滤的限制
- 对冷启动问题不友好
- 不能直接获取到有价值的特征数据,可能是关于观众或者电影的片面的信息,只能从这些信息上推测用户的爱好

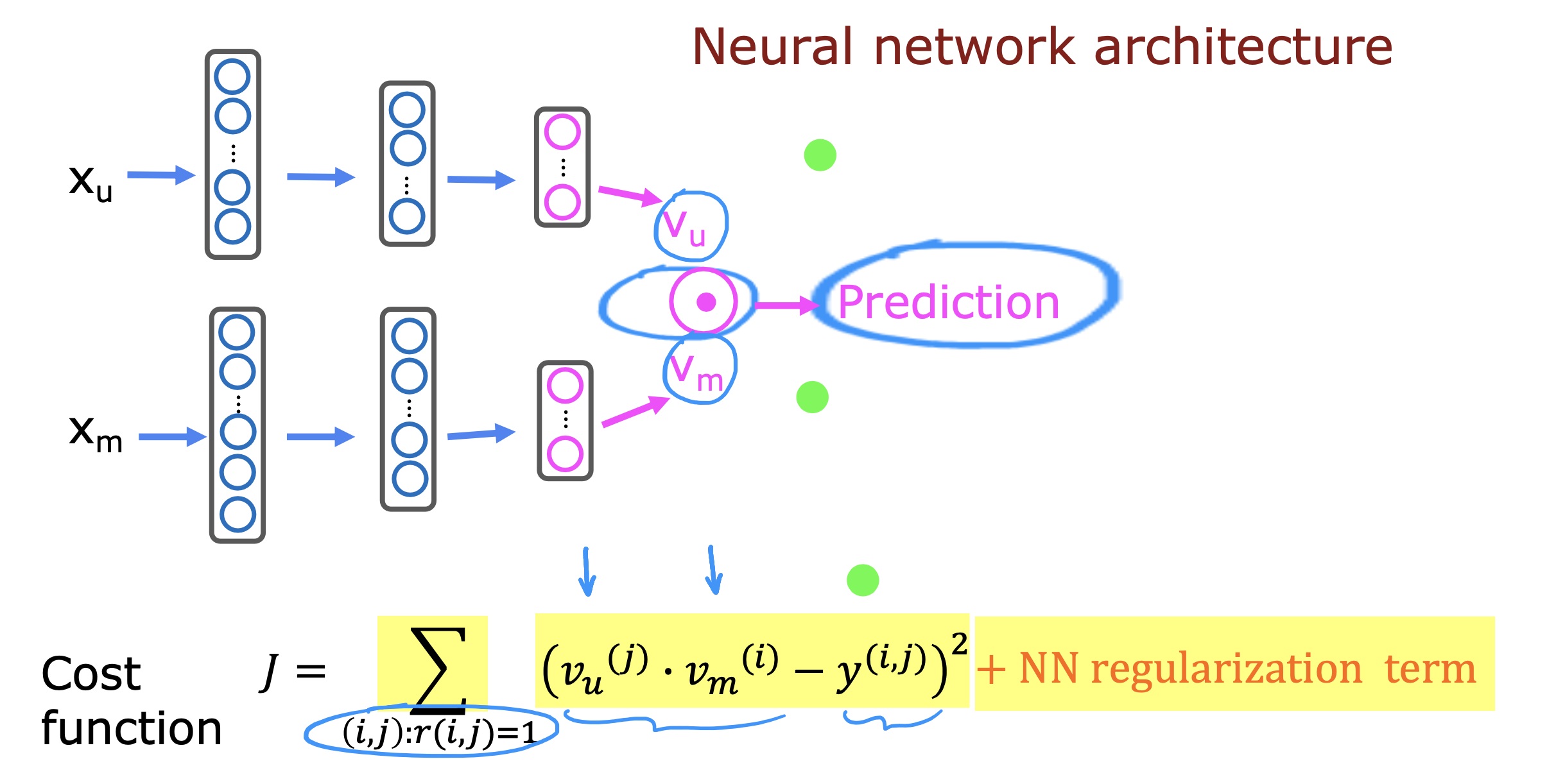
基于内容的推荐算法
对比基于协同过滤的推荐算法(根据用户对相似item的评分进行推荐)
基于内容的推荐算法同时基于用户和item的特征,通过计算item 和用户的匹配度,来判断用户是否对该item感兴趣
主要思路
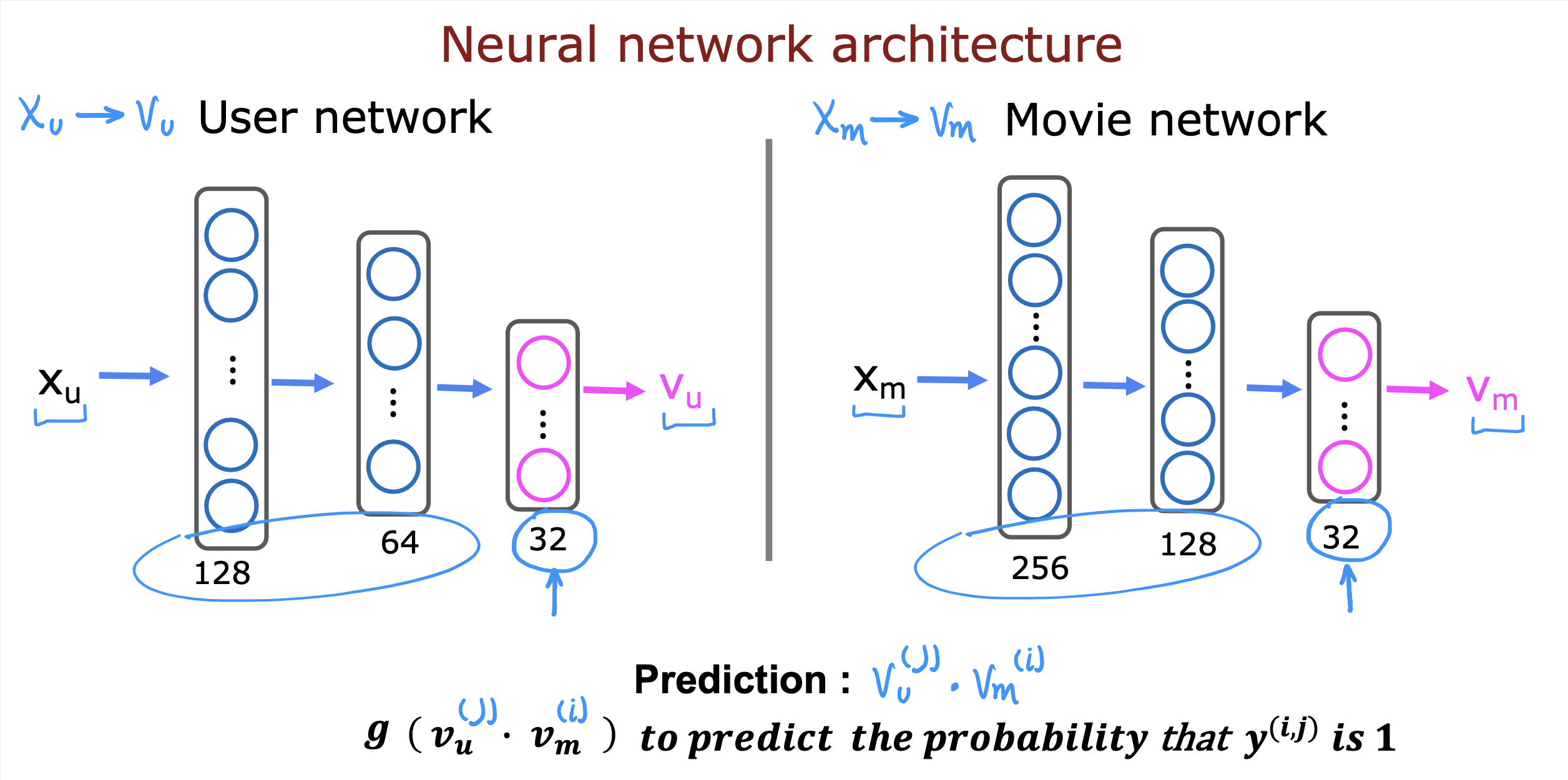
利用神经网络从用户特征和item 特征中提取n 个特征,计算二者的点积从而判断用户是否对item感兴趣,是否要推荐给用户


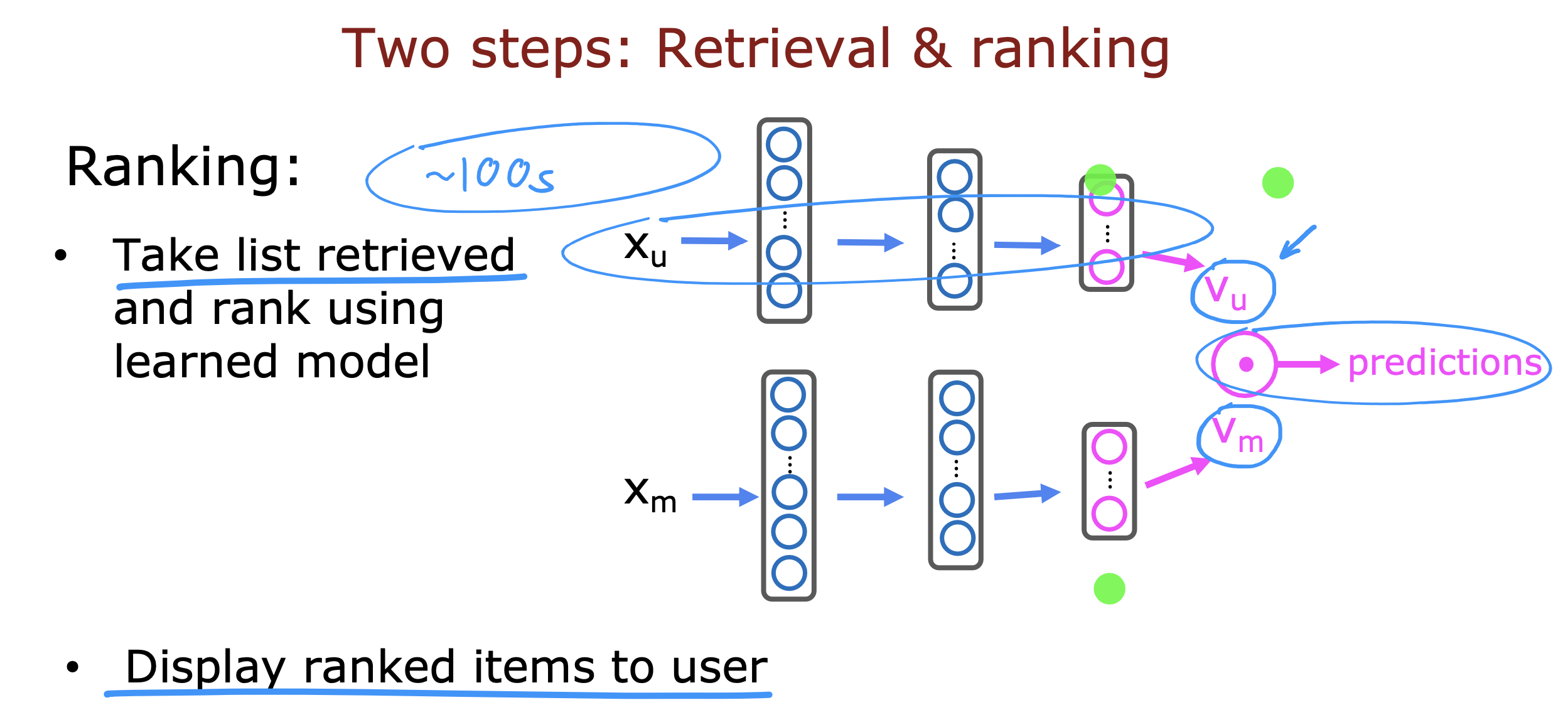
从大目录中进行推荐
进行检索,找出候选列表
但是检索过程需要注意,通过对更多的项目进行检索可以得到更好的结果但是检索的速度回变慢,
为了分析优化权衡二者,可以实施离线实验观察新增的检索项是否增加了检索结果的相关性对候选列表进行fine-tune排序找出得分最高的item给用户