强化学习的主要思想不是告诉算法每个输入的正确输出是什么
而是指定一个奖励函数,告诉它什么时候做的好,什么时候做的不好
算法的工作是自动找出如何选择好的动作

一些概念
以火星探测器为例,在其决定路线的过程中产生的几个概念
- S : 当前状态
- a : 动作
- S’ : 下一个状态
- R : 奖励函数
teminal state : 终止状态
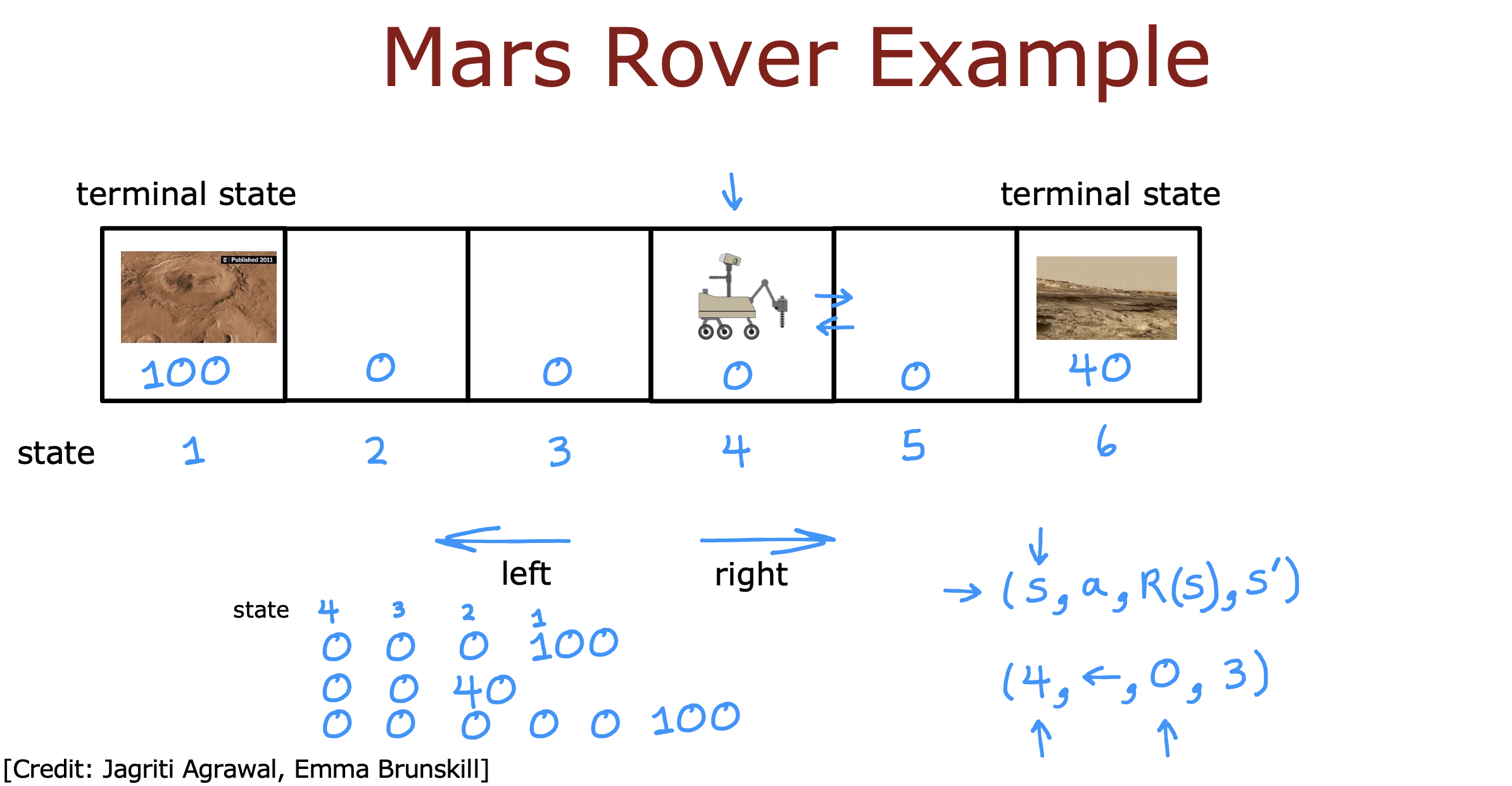
每种路线回报通过计算路上每一步奖励乘以折现系数加和得到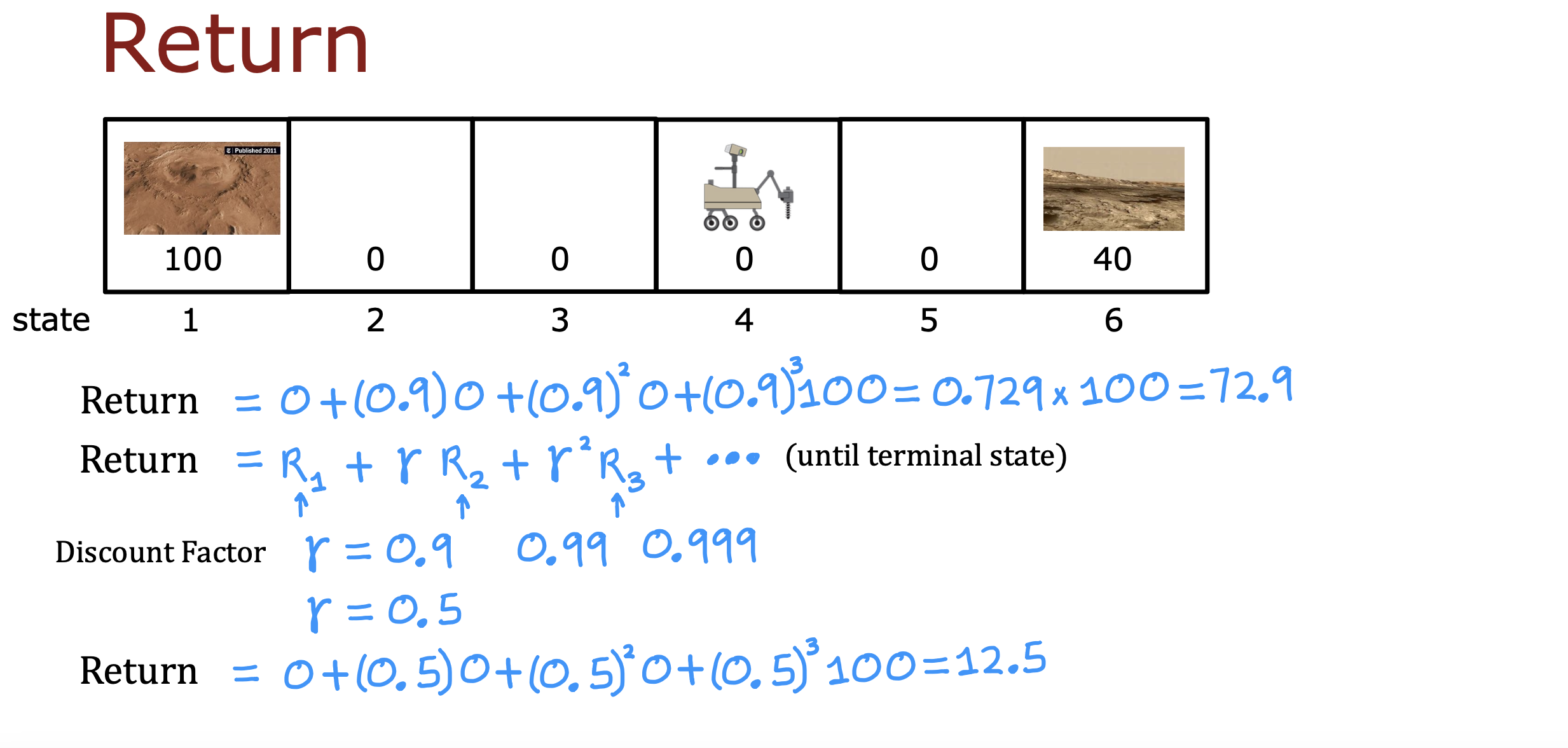
policy : 策略函数,根据当前的状态选择可以获得最大收益的动作
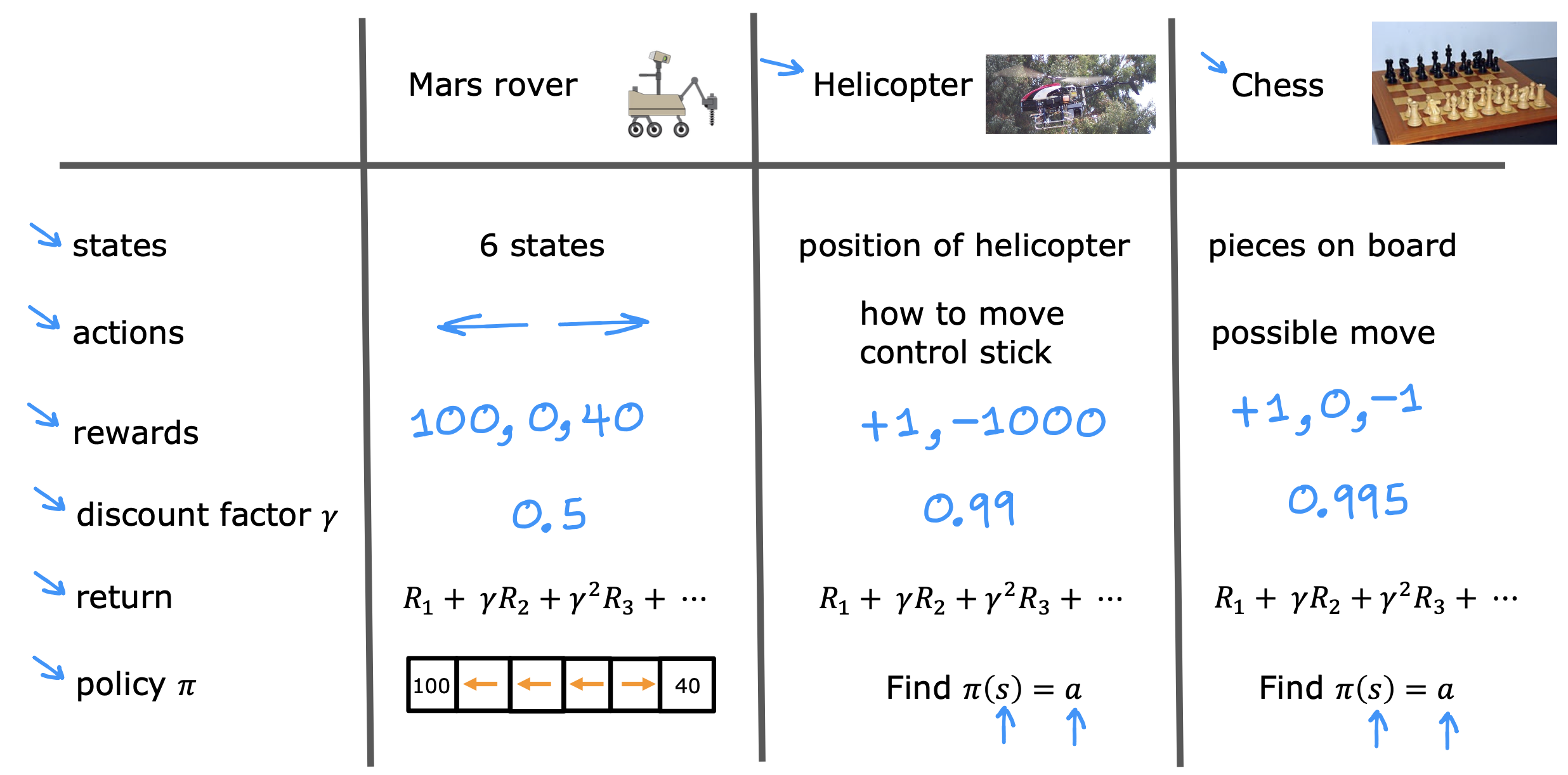
A policy is a function π(s)= a mapping from states to actions, that tells you what action a to take in a given state s.
The goal of reinforcement learning ===>
Find a policy 5 that tells you what action (a = 5(s)) to take in every state (s) so as to maximize the return.
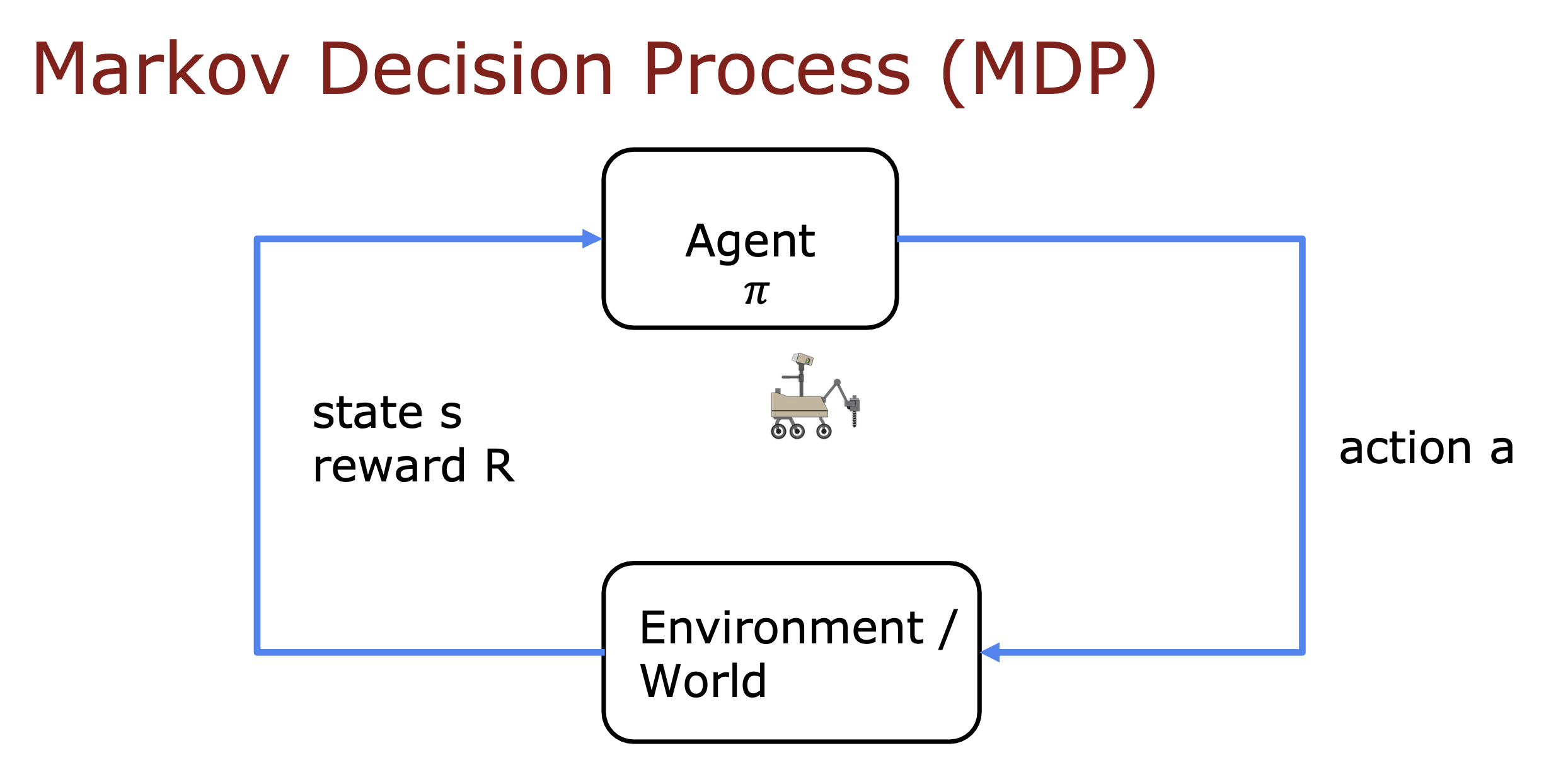
马尔科夫决策过程
未来只取决于当前的名称,而不是到达当前状态之前可能发生的任何事情
状态动作回报函数 Q
当前状态下执行一次函数能够得到的最大回报值
如果能够找到最大回报值也就能知道接下来应该用什么动作

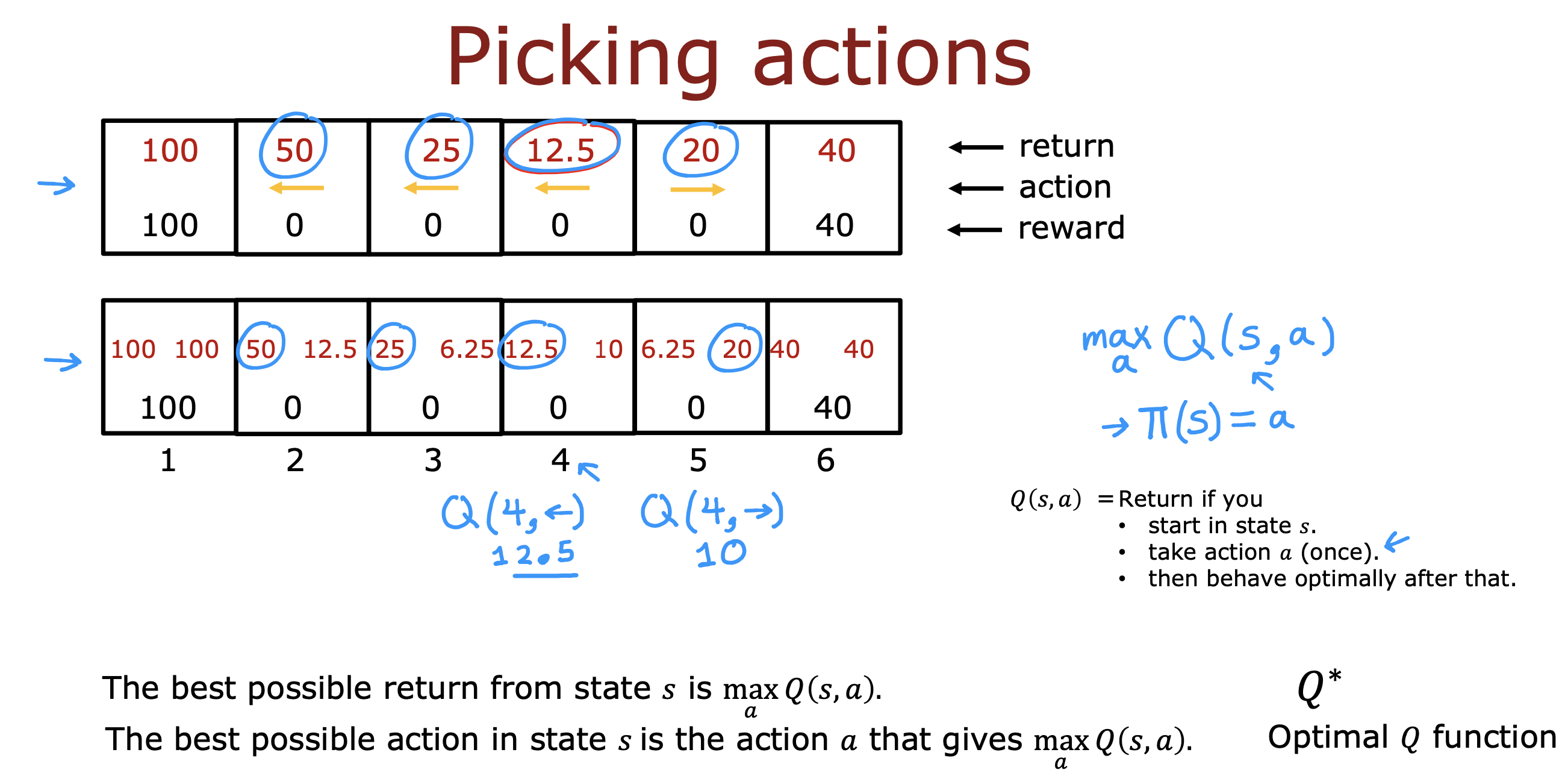
贝尔曼公式



优化
面对环境随机的情况,动作实际执行过程可能存在多个可能路线,导致每次得到的最大回报值不同,因此计算当前状态最大收益时取所有路线情况的平均值进行计算
即使用期望回报值进行计算

DQN 算法
D: deep learning
Q: Q function
N: Network
对于连续状态值的情况,使用神经网络训练Q函数进行深度强化学习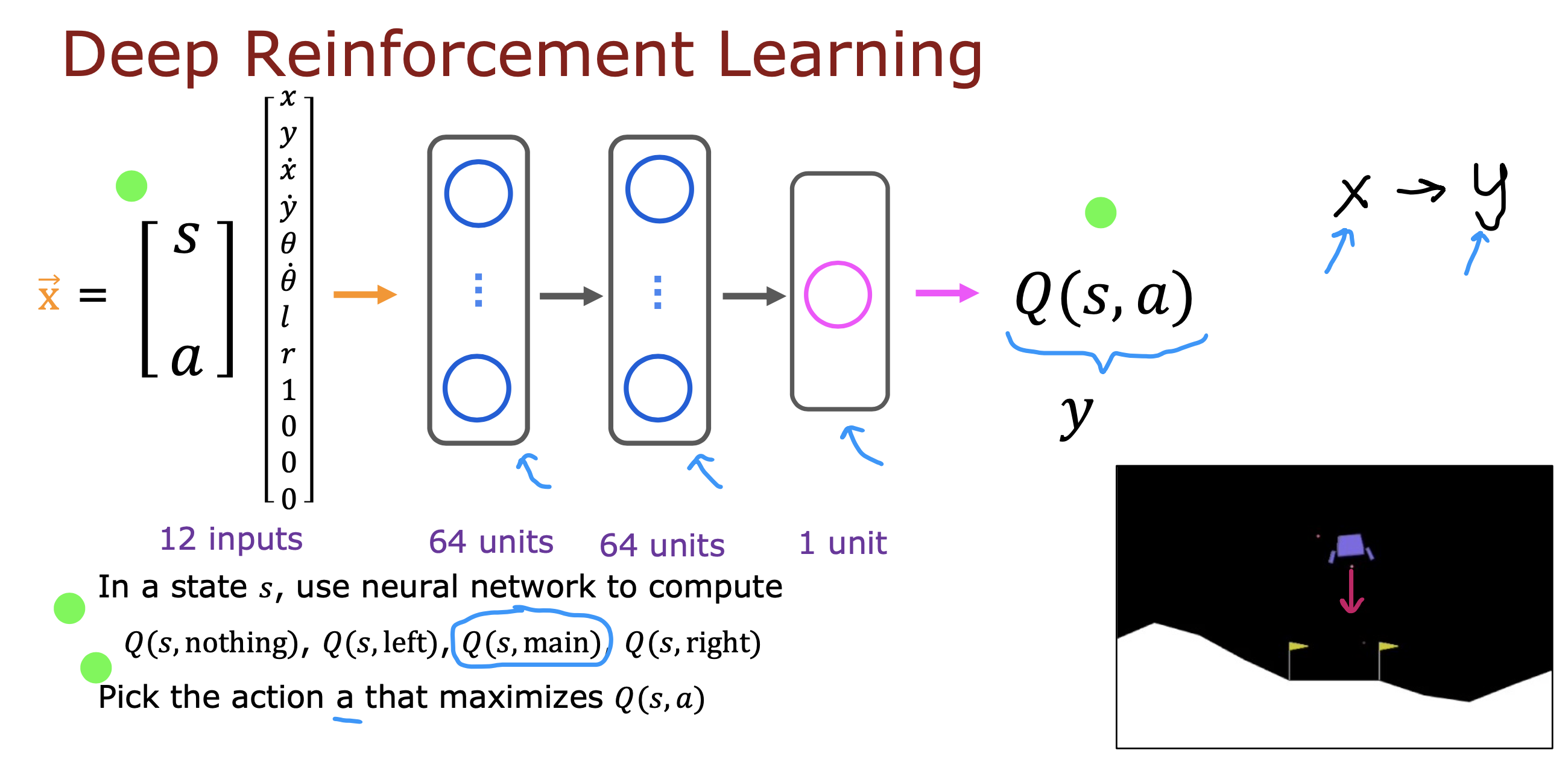


By using experience replay we avoid problematic correlations, oscillations and instabilities. In addition, experience replay also allows the agent to potentially use the same experience in multiple weight updates, which increases data efficiency.
通过使用经验重放,我们可以避免有问题的相关性、振荡和不稳定性。此外,经验重放还允许代理在多次权重更新中使用相同的经验,从而提高数据效率。
优化
优化神经网络结构
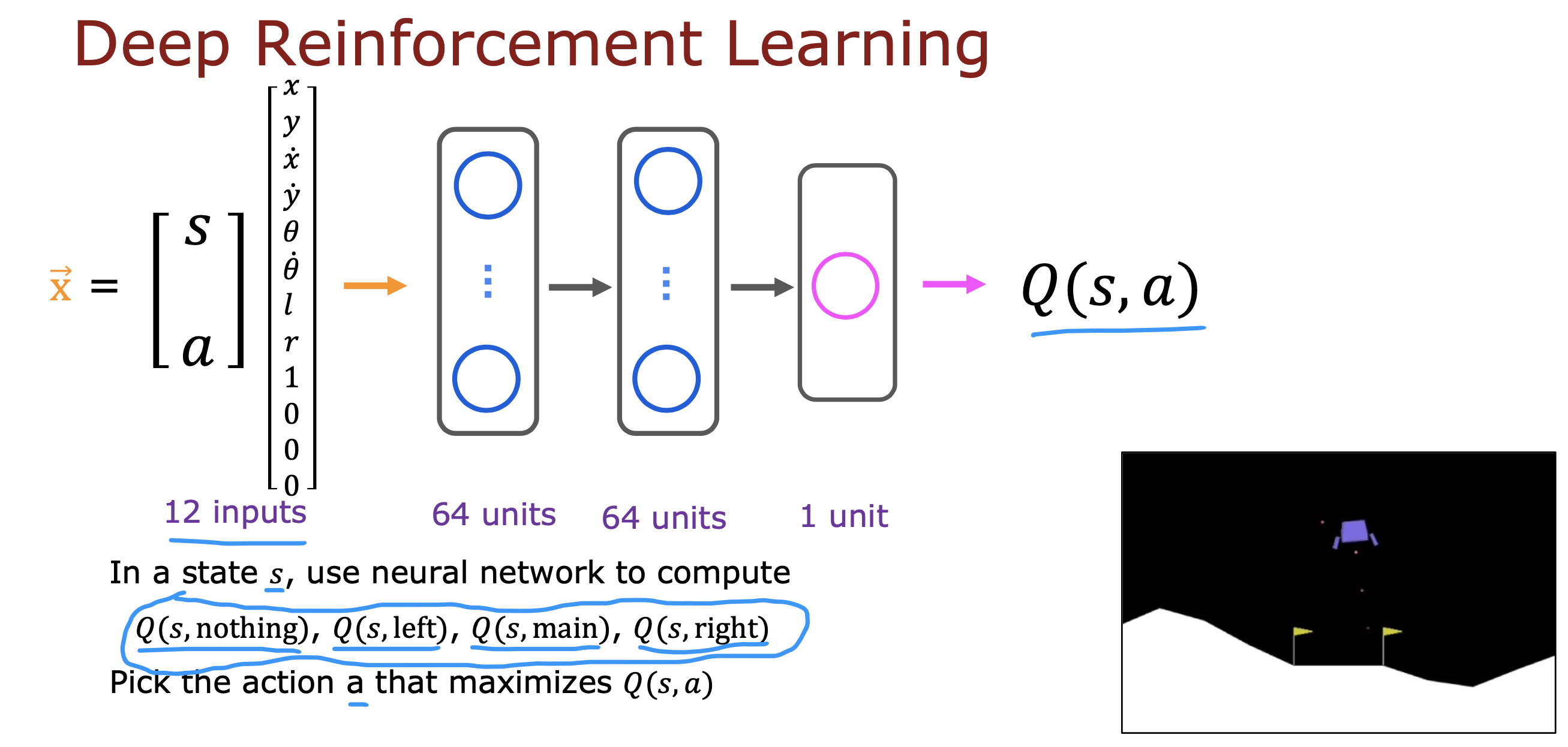
上面将s和a作为X 同时参与训练,最终只会得到一个动作a最大回报函数值,需要进行多次运算
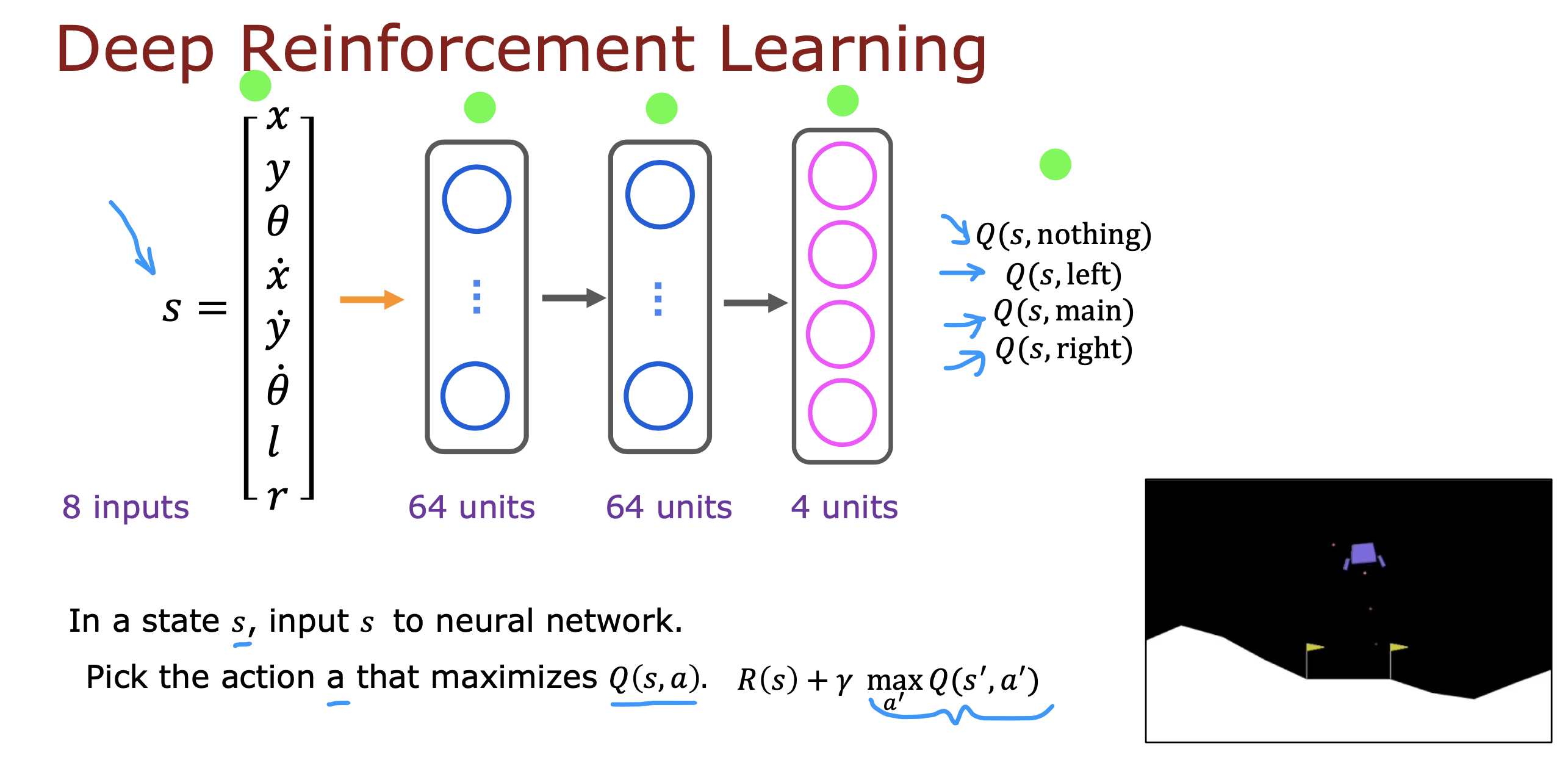
如果仅将s作为输入,输出层产生多个a的回报值,就可以根据回报值大小选择相应的动作
epsilon-greedy policy
选择action 过程中,如果一直按Q值最大原则选择action,万一初始值特别小无法开启我们想要的第一步程序,就会导致无法进行后续的action
epsilon-greedy policy 方案就是找一个合适的阈值epsilon,比如说0.05,
95%的时间选择最大Q值action (贪婪剥削策略)
5%的时间选择随机选择action(探索策略)
这样就可以避免选到固定不符合预期的action,开放一定的窗口有可能选到其他的action
epsilon 大小 类似于梯度,随训练过程进行会逐渐变小,变小的过程,模型也就学会了如何选择更有可能选择符合预期的action

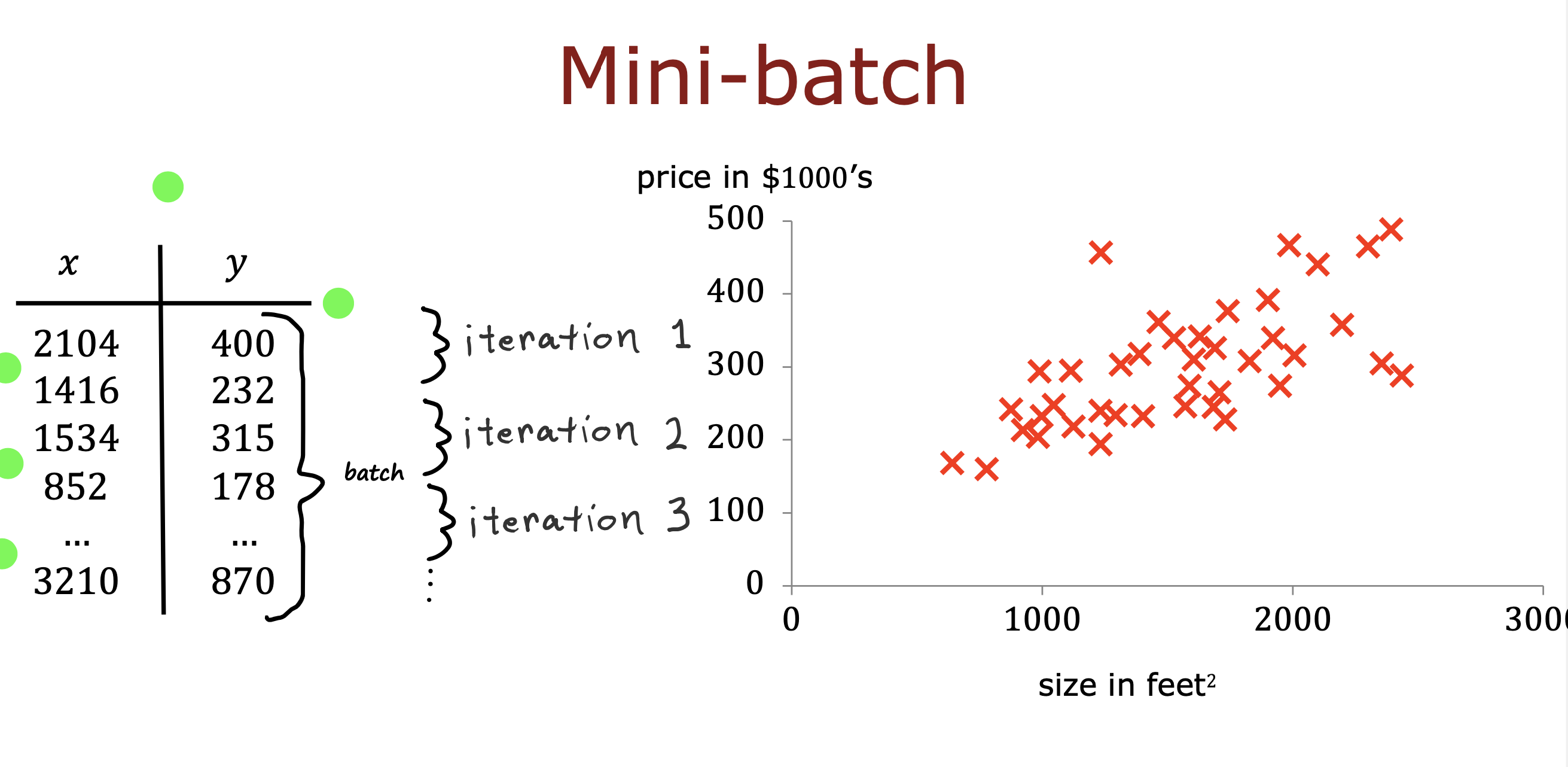
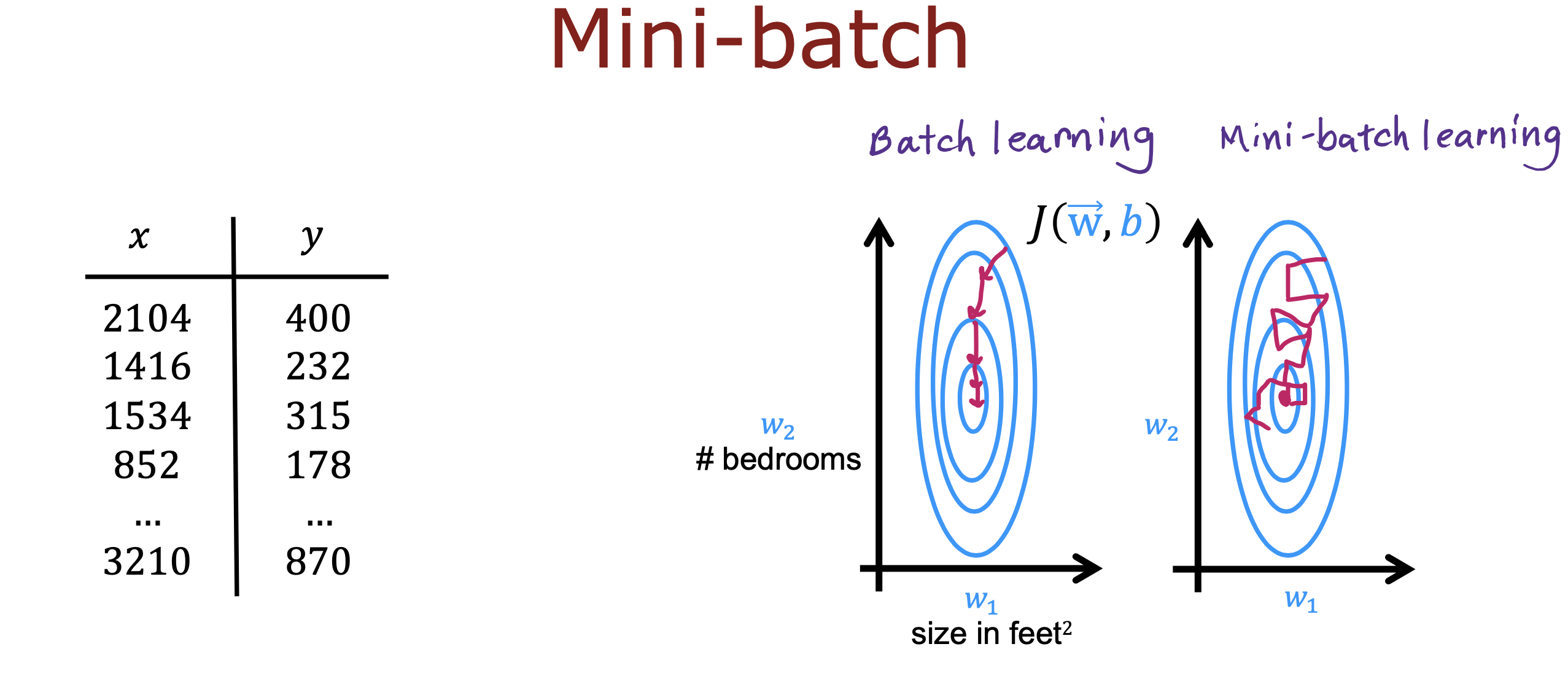
小批量
训练数据如果非常庞大,在训练过程中可能会造成时间消耗,为了提高训练速度,可以采用小批量的方式进行
将训练数据分成多个批次,每次迭代用不同批次数据,虽然梯度会比较嘈杂,但还是会朝着梯度下降的方向进行

软更新
在更新参数过程中,每次按比例更新参数,每次仅更新部分比例的参数,可以使强化学习更好的收敛
强化学习的一些限制
