在页面中引入QRcode.js文件,再js部分进行定义
var qrcode = new QRCode(document.getElementById(“qrcode0”), { //qrcode0放置二维码容器的id
width : 150,//二维码大小
height : 150
});
qrcode.makeCode(url);//url,生成二维码的依据
Angularjs 利用图片更换emoji表情
在某些浏览器中,emoji表情不能正常显示,只能显示原始状态如下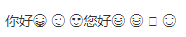
为使表情正常显示,这里利用转码方法将emoji符号用图片替换1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61//对数据$scope.data.remark做表情替换处理,$scope.data.remark是包含emoji符号的字符串
var str=$scope.data.remark;
str=str.replace(rep,function(code) { //code即匹配到的emoji符号,对该符号通过_escapeToUtf32(code)转码,得到对应图片名,然后图片替换
return '<img class="emoji" style="vertical-align:middle" src="assets/img/emoji/'+_escapeToUtf32(code) + '.png">';
})
$scope.data.remark = str;
//用emoji符号的unicode码匹配emoji符号,例如270c匹配 victory hand符号
var rep =/\uD83C[\uDF00-\uDFFF]|\uD83D[\uDC00-\uDE4F]|\u270c|\u261d/g;
//emoji 表情转码
function _escapeToUtf32(str) {
var escaped = [],
unicodeCodes = _convertStringToUnicodeCodePoints(str),
i = 0,
l = unicodeCodes.length,
hex;
for (; i < l; i++) {
hex = unicodeCodes[i].toString(16);
escaped.push('0000'.substr(hex.length) + hex);
}
return escaped.join('-');
}
function _convertStringToUnicodeCodePoints(str) {
var surrogate1st = 0,
unicodeCodes = [],
i = 0,
l = str.length;
for (; i < l; i++) {
var utf16Code = str.charCodeAt(i);
if (surrogate1st != 0) {
if (utf16Code >= 0xDC00 && utf16Code <= 0xDFFF) {
var surrogate2nd = utf16Code,
unicodeCode = (surrogate1st - 0xD800) * (1 << 10) + (1 << 16) + (surrogate2nd - 0xDC00);
unicodeCodes.push(unicodeCode);
}
surrogate1st = 0;
} else if (utf16Code >= 0xD800 && utf16Code <= 0xDBFF) {
surrogate1st = utf16Code;
} else {
unicodeCodes.push(utf16Code);
}
}
return unicodeCodes;
}
//Angularjs对字符串里面的html标签不会按照HTML去解析,会当做字符串显示,
//所以这里需要对字符串进行过滤,使字符串里面的标签能按照html解析
//新建过滤器trust2Html,这里使用$sce方法
app.filter('trust2Html', ['$sce',function($sce) {
return function(val) {
return $sce.trustAsHtml(val);
};
}])
//在页面里面显示经过图片替换的含emoji符号的字符串
<label ng-bind-html="data.remark|trust2Html"></label>
替换后结果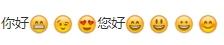
Emoji Unicode Tables
探究jQuery.data
jQuery.data用于处理标签数据绑定
使用方法
1.赋值
a.使用js
$(‘’).data(key,value); 一次赋值一个,value可以是任意js数据类型,包括Array 或者 Object
$(‘’).data(obj);一次赋值多个或者更新多个或者新增多个
b.使用HTML标签属性
利用H5 标签的’data-‘属性添加键值对1
<div data-role="page" data-last-value="43" data-hidden="true" data-options='{"name":"John"}'></div>
2.取值
$(‘’).data(key);获取key对应的数据值
$(‘’).data(); 一次性获取绑定在$(‘’)上的所有数据对象
3.删除
$(‘’).removeData(key);
注意事项
a. <object>(除非是Flash插件),<applet> 或 <embed>> 三个标签不能使用.data方法
b. 通过”data-“属性建立的标签数据,获取时注意
data-last-value=”43” ==> $(‘div’).data(‘lastValue’)
data-options=’{“name”:”John”}’ ==> $(“div”).data(“options”).name ->John
取到的值会自动转化为js的数据类型
c. $(‘’).data()被赋值到js变量A后,之后对$(‘’)进行数据处理,A的内容会进行同步变动,
如果更改A的内容,$(‘’).data()也会同步更改
但如果$(‘’).data()的值被用到了html里面,HTML里面的值不会变动
1 | <!DOCTYPE html> |
angular样式绑定ng-class
ng-class命令可用于绑定不同的样式
使用方法即先在js中,定义样式集合
$scope.STATUS_NAME = [
{‘labelClass’: ‘label1’},
{‘labelClass’: ‘label2’},
{‘labelClass’: ‘label3’},
{‘labelClass’: ‘label4’}
];
对绑定对象赋值
angular.forEach($scope.data, function(data){
//对数组中每一项,根据status属性赋给labelclass属性样式集合中的值
data.labelClass = $scope.STATUS_NAME[data.status].labelClass;
});
在html中定义不同的样式1
2
3
4
5
6
7
8
9
10
11
12
13
14<style type="text/css">
.label1{
background-color:#87CEFA
}
.label2{
background-color:#90EE90
}
.label3{
background-color:#d2cd93
}
.label4{
background-color:#D3D3D3
}
</style>
在html中使用1
2
3<tr role="row" ng-repeat="item in data track by $index">
<td><span class="label" ng-class="item.labelClass">{{item.status_desc}}</span></td>
</tr>
cookie和session
cookie
设置cookie1
2
3
4
5
6
7
8
9bool setcookie (
string $名字
[, string $值]
[, int $过期时间 = 0]
[, string $路径]
[, string $域名]
[, bool $安全 = false]
[, bool $http只读 = false]
);
参数 描述
$名字 必需。规定 cookie 的名称。
$值 可选。规定 cookie 的值。
$有效期 可选。规定 cookie 的有效期。
$路径 可选。规定 cookie 的服务器路径。
$域名 可选。规定 cookie 的域名。
$安全 可选。规定是否通过安全的 HTTPS 连接来传输 cookie。
$http安读 可选。如果true,那么js就无法读取改cookie,增加安全性。
在服务端通过$_COOKIE[‘name’] 来读取cookie了。
session
session_start(); //开启session
$_SESSION[‘userName’] = ‘wang’; //添加session数据
$userName = $_SESSION[‘userName’]; //读取session数据
unset($_SESSION[‘XXX’]);//销毁单个session数据
$_SESSION = array();//销毁全部session数据
session_destory();//这个函数会销毁当前会话中的全部数据,并结束当前会话,但是不会重置当前会话所关联的全局变量,也不会重置会话 cookie
在php.ini配置文件中有这么一行 session.save_handler = files,
files,说明了php默认的是用文件读写的方式来保存session的
session.save_path = “/tmp”, “/tmp”即存储路径
curl
1 | <?php |
函数 curl_setopt
参数1 curl资源变量
参数2 curl参数选项
参数3 curl参数值
CURLOPT_URL 这个参数选项规定了请求的url地址。
CURLOPT_RETURNTRANSFER curl请求后返回对应的结果 若需要返回值即为1。不需请求后返回的结果可设置为0。
如果是get请求,我们不需要设置发送的参数。在post等请求的时候,我们需要设置发送方法为post方法。并设置发送的数据。
CURLOPT_POST 值设为1是使用POST方法,0为不使用POST方法
CURLOPT_POSTFIELDS 设置传递的数据
//声明使用POST方式来进行发送
curl_setopt($ch, CURLOPT_POST, 1);
//发送什么数据呢
curl_setopt($ch, CURLOPT_POSTFIELDS, $data);
如果是https有的时候需要忽略https的安全证书。
CURLOPT_SSL_VERIFYPEER和CURLOPT_SSL_VERIFYHOST 两个参数改为false即忽略了证书。
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false);
CURLOPT_HEADER 决定是是否处理http的头信息,不接收处理的话可将这个值设置为0。
CURLOPT_TIMEOUT 设置请求的超时时间
$output = curl_exec($ch); 如果执行的结果有数据。使用curl_exec执行后,会将结果返回给$output变量。
curl_close($ch); 关闭curl资源。
curlget 截取页面例子
curlpost例子
MySQL的基本知识
五个基本单位
数据库服务器:指用来运行数据库服务的一台电脑
数据库:一个数据库服务器里面有可以有多个数据库。主要用来分类使用。
数据表:专门用来区分一个数据库中的不同数据
数据字段:也叫数据列,日常所见表格里面的列
数据行:真正的数据存在每一个表的行里面
语句类别
1.数据定义语言(DDL ,Data Defintion Language)语句:数据定义语句,用于定义不同的数据段、数据库、表、列、索引等。常用的语句关键字包括create、drop、alter等。
2.数据操作语言(DML , Data Manipulation Language)语句:数据操纵语句,用于添加、删除、更新和查询数据库记录,并检查数据的完整性。常用的语句关键字主要包括insert、delete、update和select等。
3.数据控制语言(DCL, Data Control Language)
语句:数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。
这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括grant、revoke等。
操作语句
create database 数据库名; 创建数据库
show databases; 查看当前服务器有哪些数据库,显示所有数据库名
use 数据库名; 选中数据库,进入到相应的数据库中
show tables; 显示当前数据库下的所有表
drop database 数据库名; 删除数据库
create table 表名(字段名1 字段类型,….字段名n 字段类型n); 建表
desc 表名; 查看表结构,显示表中属性
show create table 表名 \G;
查看表的创建语句,“\G”选项的含义是使得记录能够按照字段竖着排列,对于内 容比较长的记录更易于显示。
可以看到表的 engine(存储引擎) 和 charset(字符集)等信息
在创建表的时候能够制定引擎
例
CREATE TABLE emp (
useraname varchar(10) DEFAULT NULL,
password date DEFAULT NULL,
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
drop table 表名; 删除表
alter table 表名 modify 字段名 类型字段; 修改表字段类型
alter table 表名 add column 字段名 类型; 增加表字段
alter table 表名 add 字段名2 字段类型 after 字段名1; 在字段名1后面增加字段名1
alter table 表名 add 字段名2 字段类型 first; 在最开始的位置增加字段
alter table 表名 drop column 字段名; 删除表字段
alter table 表名 change 字段原名 字段新名 字段类型; 表字段改名
alter table 旧表名 rename 新的表名; 修改表名
修改表字段排列顺序
在前的字段增加和修改语句(add/change/modify)中,最后都可以加一个可选项 first|after。
数据类型
整型
MySQL数据类型 所占字节 值范围
tinyint 1字节 -128~127
smallint 2字节 -32768~32767
mediumint 3字节 -8388608~8388607
int 4字节 范围-2147483648~2147483647
bigint 8字节 +-9.22*10的18次方
1.在创建表字段时,性别我们可以使用无符号的微小整型(tinyint)来表示。用0表示女、用1表示男。用2表示未知。
2.同样人类年龄也是,在创建表字段时可用用无符号的整型。因为人类的年龄还没有负数
3.在实际使用过程中。我们业务中最大需要存储多大的数值。我们创建表时,就选择什么样的类型来存储这样的值。
浮点类型
MySQL数据类型 所占字节 值范围
float(m, d) 4字节 单精度浮点型,m总个数,d小数位
double(m, d) 8字节 双精度浮点型,m总个数,d小数位
decimal(m, d) decimal是存储为字符串的浮点数
浮点是非精确值,会存在不太准确的情况,而decimal叫做定点数。
在MySQL内部,本质上是用字符串存储的。实际使用过程中如果存在金额、钱精度要求比较高的浮点数存储,建议使用decimal(定点数)这个类型
字符类型
MySQL数据类型 所占字节 值范围
CHAR 0-255字节 定长字符串
VARCHAR 0-255字节 变长字符串
TINYBLOB 0-255字节 不超过255个字符的二进制字符串
TINYTEXT 0-255字节 短文本字符串
BLOB 0-65535字节 二进制形式的长文本数据
TEXT 0-65535字节 长文本数据
MEDIUMBLOB 0-16 777 215字节 二进制形式的中等长度文本数据
MEDIUMTEXT 0-16 777 215字节 中等长度文本数据
LOGNGBLOB 0-4 294 967 295字节 二进制形式的极大文本数据
LONGTEXT 0-4 294 967 295字节 极大文本数据
VARBINARY(M) 允许长度0-M个字节的定长字节符串 值的长度+1个字节
BINARY(M) M 允许长度0-M个字节的定长字节符串
时间类型
MySQL数据类型 所占字节 值范围
date 3字节 日期,格式:2014-09-18
time 3字节 时间,格式:08:42:30
datetime 8字节 日期时间,格式:2014-09-18 08:42:30
timestamp 4字节 自动存储记录修改的时间
year 1字节 年份
复合类型
MySQL数据类型 说明 举例
set 集合类型 set(“member”, “member2″, … “member64″)
enum 枚举类型 enum(“member1″, “member2″, … “member65535″)
一个 ENUM 类型只允许从一个集合中取得一个值;而 SET 类型允许从一个集合中取得任意多个值。
常用中文字符集
gbk_chinese_ci 简体中文, 不区分大小写
utf8_general_ci Unicode (多语言), 不区分大小写
mysql在写utf-8的时候写的是utf8。不加中间的中横线
存储引擎
使用show engines命令可显示当前服务器支持的所有引擎
引擎名称
MyISAM 常用。读取效率很高的引擎
InnoDB 常用。写入,支持事处等都支持
Archive 不常用。归档引擎,压缩比高达1:10,用于数据归档
NDB 不常用。主要在MySQL 集群服务器中使用,
行锁:写入、更新操作的时候将这一行锁起来,不让其他人再操作了。
表锁:写入、更新操作时,将表给锁起来不让其他人再操作了。
事务:同时操作多个数据,若其中的一个数据操作失败。可回滚到操作之前。常用于银行、电商、金融等系统中
MyISAM
不支持事务,表锁(表级锁,加锁会锁住整个表),支持全文索引,操作速度快。常用于读取多的业务。
myisam存储引擎表由myd和myi组成。.myd用来存放数据文件,.myi用来存放索引文件。
对于myisam存储引擎表,mysql数据库只缓存其索引文件,数据文件的缓存由操作系统本身来完成。
InnoDB
支持事务,主要面向在线事务处理(OLTP)方面的应用。
行锁设计,支持外键,即默认情况下读取操作不加锁。
索引
1.普通索引 最基本的索引,它没有任何限制
alter table 表 add index(字段)
2.唯一索引 某一行企用了唯一索引则不准许这一列的行数据中有重复的值。针对这一列的每一行数据都要求是唯一的
alter table 表 add UNIQUE(字段)
3.主键索引 它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引,常用于用户ID。类似于书中的页码
alter table 表 add PRIMARY KEY(字段)
4.全文索引 对于需要全局搜索的数据,进行全文索引
alter table 表 add FULLTEXT(字段)
创建表时可在创建表语句后加上对应的类型即可声明索引:
CREATE TABLE test (
id INT NOT NULL ,
username VARCHAR(20) NOT NULL ,
password INT NOT NULL ,
content INT NOT NULL ,
PRIMARY KEY (id),
INDEX pw (password),
UNIQUE (username),
FULLTEXT (content)
) ENGINE = InnoDB;
插入记录
方法一:
insert into 表 values(值1,值2,值n);
表中有多少个字段就必须要插入多少个值。一个不能多,一个也不能少。若有默认值,不想传,可以写上null。
顺序应该和表字段的排序一致。
方法二:
insert into 表(字段1,字段2,字段n) values(值1,值2,值n);
除非有必填字段必须要写入值外。如果有默认值的不想写可以忽略不写。mysql会自动补主默认值。
以表(字段1,字段2,字段n)字段顺序为值的顺序。
基本语法变形:一次插入多条记录
INSERT INTO user(username,password,sex)
values(‘ll’, ‘abcdef’, 1),
( ‘loe’, ‘bcdeef’, 0),
( ‘key’, ‘123456’, 1),
(‘tom’, ‘987654’, 1);
查询
select from 表; 查询表中所有字段中的所有结果,”“ 是一种正则表达式的写法,表示匹配所有
select 字段1[,字段2,字段n] from 表; 指定字段查询
select distinct 字段 from 表; 查询单个字段不重复记录 distinct
select 字段 from 表 where 条件; 条件查询 where,条件可以是逻辑比较运算符的比较式
select 字段 from 表 order by 字段 排序关键词; 查询结果按照字段排序关键词排序
排序关键词:
asc 升序排列,从小到大(默认)
desc 降序排列,从大到小
select 字段 from 表 order by 字段1 排序关键词,… …字段n desc|asc;
order by 后面可以跟多个不同的字段排序,并且排序字段的不同结果集的顺序也不同,
如果排序字段的值一样,则值相同的字段按照第二个排序字段进行排序。
select 字段 from 表 limit 数量; 对于查询或者排序后的结果集,如果希望只显示一部分而不是全部,使用 limit 关键字结果集数量限制。
select 字段 from 表 order by 字段 关键词 limit 数量; 限制结果集并排序
select 字段 from 表 limit 偏移量,数量; 结果集区间选择,偏移量从0开始,0是第一条数据
select 函数(字段) from 表; 从表中将按字段查询的结果进行函数处理
函数
sum 求和
count 统计总数
max 最大值
min 最小值
avg 平均值
select from 表 group by 字段; 将表中数据按字段分组
select from 表 group by 字段 having 条件; 分组结果再过滤。having 是筛选组 而where是筛选记录
例:统计省份数量后再进行分组显示: select count(province),province from money group by province;
整体的SQL语句配合使用的语法结构如下:
SELECT
[字段1 [as 别名1],[函数(字段2) ,]……字段n]
FROM 表名
[WHERE where条件]
[GROUP BY 字段]
[HAVING where_contition]
[order 条件]
[limit 条件]
例
查询money表字段:id,username,balance,province 要求id>1 余额大于50,使用地区进行分组。我们使用用户id进行降序,要求只准显示3条。
select id,username,balance,province from money where id > 1 and balance > 50 group by province order by id desc limit 3;
多表联合查询
内连接
将两个表中存在联结关系的字段符合联结关系的那些记录形成记录集的联结。
基本语法1:
select 表1.字段 [as 别名],表n.字段 from 表1 [别名],表n where 条件;
取满足条件的数据的在各表中的各字段
例
select user.uid ,user.username as username,order_goods.oid,order_goods.uid,order_goods.name as shopname from user,order_goods where user.uid = order_goods.uid;
若表user中某条数据x的uid与表order_goods中的某条数据y的uid相同,则取出user表中数据x的 uid、username,取出order_goods中数据y的uid,name,其中order_goods的name的值以shopname的值显示
基本语法2:
select 表1.字段 [as 别名],表n.字段 from 表1 INNER JOIN 表n on 条件;
例
select user.uid ,user.username as username,order_goods.oid,order_goods.uid,order_goods.name as shopname from user inner join order_goods on user.uid = order_goods.uid;
效果同基本语法1
## 外连接
会选出其他不匹配的记录,分为外左联结和外右联结。
左连接:包含所有的左边表中的记录甚至是右边表中没有和它匹配的记录
select 表1.字段 [as 别名],表n.字段 from 表1 LEFT JOIN 表n on 条件;
例
select * from user left join order_goods on user.uid = order_goods.uid;
以左边user为主,查询哪些用户未购买过商品,并将用户信息显示出来,user表全部显示
右连接:包含所有的右边表中的记录甚至是右边表中没有和它匹配的记录
select 表1.字段 [as 别名],表n.字段 from 表1 right JOIN 表n on 条件;
例
select * from user right join order_goods on user.uid = order_goods.uid;
查询商品表中哪些用户购买过商品,并将用户信息显示出来,order_goods全部显示
子查询
需要的条件是另外一个select语句的结果,即使用子查询
用于子查询的关键字包括in、not in、=、!=、exists、not exists等。
select 字段 from 表 where 字段 in(条件)
例
select * from user where uid in (select uid from order_goods);
从order_goods取出uid这一列,将uid在user中对应的数据取出来
记录联合
使用 union 和 union all 关键字,将两个表的数据按照一定的查询条件查询出来后,将结果合并到一起显示。
union all 把结果直接合并在一起
union 是将 union all 后的结果进行一次distinct,去除重复记录后的结果。
修改
使用update
update 表名 set 字段1=值1,字段2=值2,字段n=值n where 条件;
例
update emp set balance=balance-500 where userid = 15;
将emp表中userid为15的数据的balance减15
同时对两个表进行更新
update 表1,表2 set 字段1=值1,字段2=值2,字段n=值n where 条件
例
update money m,user u m.balance=m.balanceu.age where m.userid=u.id;
修改money,将money表的别名设置为m;user表的别名设置为u;将m表的余额改为m表的balance用户表的age。执行条件是:m.userid = u.id
删除
用delete
DELETE FROM 表 [where 条件];
删除时如果不加where条件,会清空掉整个表的记录,返回被删除的记录数
清空表 如果使用,
truncate table 表名;
表中若有自增字段,这个自增字段会将起始值恢复成1
权限
添加权限
grant 权限 on 库.表 to ‘用户‘@’主机’ identified by ‘密码’;
grant select, insert on test.* to ‘liwenkai‘@’localhost’ identified by ‘4311’;
给予liwenkai用户,在本机连接test库所有表的权限。操作的这些表具有查询和写入权限
删除权限
revoke 权限 on 库.表 from ‘用户‘@’主机’;
revoke select, insert on test.* to ‘liwenkai‘@’localhost’ identified by ‘4311’;
给予liwenkai用户,在本机连接test库所有表的权限。操作的这些表具有查询和写入权限
参数说明
grant all 在grant后接all说明给予所有权限
revoke all 在revoke后接all说明删除所有权限
权限 on . . 所明给予所有库所有表的操作权限
‘用户‘@’主机’ 主机里面若为%。任意来源的主机均可以使用这个用户来访问
php中MySQL的使用
php连接数据库
查看数据库主机,用户名
use myaql;
select Host from user;
select user from user;
连接数据库服务器
mysql_connect函数
$con = mysql_connect(“localhost”,”peter”,”abc123”);
参数1 主机
参数2 数据库服务器登陆名
参数3 密码
参数4 数据库的名称
参数5 数据库服务器端口不填默认3306
若参数4,数据库名称在此步已填并择,不需要执行第三步
判断链接是否正常
如果有错误,存在错误号
if (mysql_errno($conn)) {
echo mysql_error($conn);
exit;
}
mysql_errno 返回连接错误号,无错误返回0
参数1 传入mysql_connect返回的资源
mysql_error 返回连接错误字符串
参数1 传入mysql_connect返回的资源
选择数据库
mysql_select_db函数
mysql_select_db(‘user’,$conn);
参数1 传入mysql_connect返回的资源
参数2 需要连接的数据库名
设置字符集
mysql_set_charset
mysql_set_charset(‘utf8’,$conn);
参数1 字符集类型
参数2 传入mysql_connect返回的资源
准备SQL语句
要传入数据库的操作语句
注意参数如何拼接
如果是int类型的就使用
$sql=”insert into user(mycon) values(“.$my_con.”)”;
//或者
$sql=’insert into user(mycon) values(‘.$my_con.’)’;
如果是字符型的就要使用单引号或者双引号括起来
$sql=”insert into user(mycon) values(‘“.$my_con.”‘)”;
//或者这样写
$sql=’insert into user(mycon) values(“‘.$my_con.’”)’;
多个
$sql = “INSERT INTO user (username,password,createtime,createip)
values
(‘“ . $username . “‘,’” . $password . “‘,” . $time . “,’” . $ip . “‘)”;
发送SQL语句
$result = mysql_query($sql,$conn);
根据不同操作,判断执行是否正常或者遍历数据
发送的是select类别的语句,通常需要将结果输出显示出来。就需要用到遍历显示数据的函数
函数 mysql_fetch_array
功能 得到result结果集中的数据,返回数组进行便利
参数1 传入查询出来的结果变量
参数2 传入MYSQLI_NUM返回索引数组,MYSQLI_ASSOC返回关联数组,MYSQLI_BOTH返回索引和关联
函数 mysql_fetch_assoc
功能 得到result结果集中的数据,返回关联数组进行便利
参数1 传入查询出来的结果变量
函数 mysql_fetch_row
功能 得到result结果集中的数据,返回索引数组进行便利
参数1 传入查询出来的结果变量
函数 mysql_fetch_object
功能 得到result结果集中的数据,返回对象进行遍历
参数1 传入查询出来的结果变量
函数 mysql_num_rows
功能 返回查询出来的结果总数
参数1 传入查询出来的结果变量
函数 sql_num_rows
功能 返回查询出来的结果总数
参数1 传入查询出来的结果变量
如果发送的是insert的语句,通常需要得到是否执行成功,或者同时拿到自增的ID。
函数 mysqli_fetch_field
功能 遍历数据行
参数1 传入查询出来的结果变量
如果发送的是update和delete类别的语句。只需要判断是否执行成功即可。
if ($result) {
echo ‘成功’;
} else {
echo $sql;//查看是否是SQL语句拼接有问题
echo ‘失败’;
}
关闭数据库
函数 mysqli_close
功能 关闭数据库连接
参数1 传入mysqli_connect返回的资源
mysql_close($conn);//关闭数据库
显示服务器信息函数
函数 mysqli_get_server_info
功能 返回服务器信息
参数1 传入mysqli_connect返回的资源
函数 mysqli_get_server_version
功能 返回服务器版本
参数1 传入mysqli_connect返回的资源
数据显示乱码终极解决办法
多个不同的文件系统中一定要统一编码。
9个要点分别是:
1.html编码与MySQL编码一致
2.PHP编码与MySQL编码一致
3.若有header头发送字符集,请与数据库一样
如果php中有header头,一定要是utf-8的
header(‘content-type:text/html;charset=utf-8’);
4.<meta http-equiv=“Content-Type”content=“text/html; charset=utf-8” />要和页面的文字编码一致
5.数据库建库的字符集要统一
6.表的字符集要统一
7.列的字符集要统一(表设了,列就默认写表的)
8.连接,校验的字符集要统一
通过mysqli_set_charset(‘utf8’)来MySQL连接、结果和校验的字符集设置。
注:数据库的字符集声明和文件中的略有不同。utf8为mysql数据库的,utf-8为文件中使用的
9.结果集的字符集要统一
图片上传
用函数画图
1 | <?php |
画验证码
图片加水印
bool imagecopymerge ( resource $目标图片 , resource $来源图片, int $目标开始的x , int $目标开始的y, int $来源的x , int $来源的y , int $来源的宽 , int $来源的高 , int $透明度)
注意:
透明度的值为0-100的整数。imagecopy和imagecopymerge的区别在于一个有透明度,一个没有透明度。
大致步骤:
1.打开原图(也叫操作的目标图片)
2.打开水印图(也叫水印来源图片)
3.使用 imagecopymerge 将小图合并至大图的指定位置
4.输出图片
5.销毁资源
代码链接
图像放缩和裁剪
操作方式说明:
从来源图片的开始点(x,y)起,指定的宽高的大小图片。放至到目标图片的起点(x,y),指定宽高大小的图片中。
缩放图片
imagecopyresampled 重采样拷贝部分图像并调整大小
bool imagecopyresampled ( resource $目标图 , resource $来源图 , int $目标开始的x位置 , int $目标开始的y位置 , int $来源开始的x位置 , int $来源开始的y位置 , int $目标图片的宽 , int $目标图片的高, int $来源图片的宽 , int $来源图片的高 )
大致步骤:
1.打开来源图片
2.设置图片缩放百分比(缩放)
3.获得来源图片,按比调整大小
4.新建一个指定大小的图片为目标图
5.将来源图调整后的大小放到目标中
6.销毁资源1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24//打开来源图片
$image = imagecreatefrompng('fbb.png');
//定义百分比,缩放到0.1大小
$percent = 0.1;
// 将图片宽高获取到
list($width, $height) = getimagesize('fbb.png');
//设置新的缩放的宽高
$new_width = $width * $percent;
$new_height = $height * $percent;
//创建新图片
$new_image = imagecreatetruecolor($new_width, $new_height);
//将原图$image按照指定的宽高,复制到$new_image指定的宽高大小中
imagecopyresampled($new_image, $image, 0, 0, 0, 0, $new_width, $new_height, $width, $height);
header('content-type:image/jpeg');
imagejpeg($new_image);
?>
裁剪图片
imagecopyresized 拷贝部分图像并调整大小
bool imagecopyresized ( resource $目标图 , resource $来源图 , int $目标开始的x位置 , int $目标开始的y位置 , int $来源开始的x位置 , int $来源开始的y位置 , int $目标图片的宽 , int $目标图片的高, int $来源图片的宽 , int $来源图片的高 )
大致步骤:
1.打开来源图片和目标图片
2.截取来源图片中的点,设置宽高。放至到目标图片中。(裁剪)
3.保存图片输入
4.销毁资源
1 | <?php |
文件上传
修改php.ini文件配置
php.ini文件在不同的集成环境包中都在安装目录的php文件下,如果有多个版本php,则在每个版本里面都会有一个php.ini文件
配置项 功能说明
file_uploads on为 开启文件上传功能,off为关闭
post_max_size 系统允许的POST传参的最大值
upload_max_filesize 系统允许的上传文件的最大值
memory_limit 内存使用限制
【建议尺寸: file_size(文件大小) < upload_max_filesize < post_max_size < memory_limit】
max_execution_time 设定脚本的最大执行时间。
也可以根据需求做适当的改变。通常不需要来修改,系统默认值即可。超大文件上传的时候,可能会涉及到这一项参数的修改
上传时间太长了,会超时。如果你将此项参数设为0,则是不限制超时时间,不建议使。
html页面
1.form 表单中的参数method 必须为post。若为get是无法进行文件上传的
2.enctype须为multipart/form-data
代码链接
文件上传
按照数组和步骤完成文件上传
所有文件的信息存储在$_FILES[‘file’]中
代码链接
多文件上传
写了2个或者多个input
将每个input name设置为”file[]”
对每个input上传文件后 $_FILE[‘file’]的每个属性将变成数组,依次对应每个input上传的文件
上传进度处理
首先要修改php.ini的相关配置
配置项 说明
session.upload_progress.enabled 是否启用上传进度报告(默认开启) 1为开启,0为关闭
session.upload_progress.cleanup 是否在上传完成后及时删除进度数据(默认开启, 推荐开启)
session.upload_progress.prefix[=upload_progress_]
进度数据将存储在_SESSION[session.upload_progress.prefix . _POST[session.upload_progress.name]]
session.upload_progress.name[=PHP_SESSION_UPLOAD_PROGRESS]
如果_POST[session.upload_progress.name]没有被设置, 则不会报告进度.
session.upload_progress.freq[=1%] 更新进度的频率(已经处理的字节数), 也支持百分比表示’%’.
session.upload_progress.min_freq[=1.0] 更新进度的时间间隔(秒)
文件上传的进度信息存储在$_SESSION中
代码链接
文件
读
readfile 传入一个文件路径,输出一个文件
int readfile ( string $文件名)
file_get_contents 传入一个文件或文件路径,打开这个文件返回文件的内容。文件的内容是一个字符串。
string file_get_contents ( string filename)
资源类型处理方式
fopen函数,打开资源,参数为文件打开路径,打开文件模式,返回资源类型
resource fopen ( string $文件名, string 模式)
fread函数 读取打开的文件资源。读取指定长度的文件资源,读取一部份向后移动一部份。至到文件结尾。
string fread ( resource $操作资源, int 读取长度)
fclose函数的功能是关闭资源。资源有打开就有关闭
bool fclose ( resource $操作资源 )
fopen的模式
模式 说明
r 只读方式打开,将文件指针指向文件头。
r+ 读写方式打开,将文件指针指向文件头。
w 写入方式打开,将文件指针指向文件头并将文件大小截为零。如果文件不存在则尝试创建
w+ 读写方式打开,将文件指针指向文件头并将文件大小截为零。如果文件不存在则尝试创建
a 写入方式打开,将文件指针指向文件末尾。如果文件不存在则尝试创建
a+ 读写方式打开,将文件指针指向文件末尾。如果文件不存在则尝试创建之
x 创建并以写入方式打开,将文件指针指向文件头。如果文件已存在,则 fopen() 调用失败并返回 FALSE,并生成一条 E_WARNING 级别的错误信息。如果文件不存在则尝试创建
x+
创建并以读写方式打开,将文件指针指向文件头。如果文件已存在,则 fopen() 调用失败并返回 FALSE,并生成一条 E_WARNING 级别的错误信息。如果文件不存在则尝试创建
t windows下将\n转为\r\n
b 二进制打开模式
创建和修改
file_put_contents 向指定的文件当中写入一个字符串,如果文件不存在则创建文件。返回的是写入的字节长度
int file_put_contents ( string $文件路径, string $写入数据])
fwrite 配合fopen进行写入操作,写入方式打开,将文件指针指向文件头并将文件大小截为零。如果文件不存在则尝试创建
int fwrite ( resource $文件资源变量, string $写入的字符串 [, int 长度])
1.不论有没有新建都会打开文件重新写入
2.原有的文件内容会被覆盖掉
3.文件不存在会创建
模式
x 每次写入会干掉原有文件的内容,文件不存在都会创建
a 每次写入都会向文件的尾端追加内容
tmpfile 创建一个临时文件,返回资源类型。关闭文件即被删除
resource tmpfile ( )
rename 重命名文件 返回一个bool值,将旧的名字改为新的名字
bool rename($旧名,$新名);
copy 复制文件 将指定路径的源文件,复制一份到目标文件的位置。
bool copy(源文件,目标文件)
unlink 删除文件 这个删除是直接删除。使用的是windows电脑,在回收站看不到这个文件
bool unlink(指定路径的文件)
检测文件属性函数
bool file_exists ( $指定文件名或者文件路径) 功能:文件是否存在。
bool is_readable ( $指定文件名或者文件路径) 功能:文件是否可读
bool is_writeable ( $指定文件名或者文件路径) 功能:文件是否可写
bool is_executable ( $指定文件名或者文件路径) 功能:文件是否可执行
bool is_file ( $指定文件名或者文件路径) 功能:是否是文件
bool is_dir ( $指定文件名或者文件路径) 功能:是否是目录
void clearstatcache ( void ) 功能:清楚文件的状态缓存
常用函数
rewind ( resource handle) 指针回到开始处
fseek ( resource handle, int offset [, int from_where]) 文件指针向后移动指定字符
filesize 检测文件的大小
file(文件名) 把整个文件读入一个数组中
fgets(文件名) 从文件指针中读取一行,读到最后返回false
fgetc(文件名) 从文件指针中读取一个字符,读到最后返回false
ftruncate(文件名,长度) 将文件截断到给定的长度
filectime(文件名) 文件创建时间
filemtime(文件名) 文件修改时间
fileatime(文件名) 文件上次访问时间
文件锁定
bool flock ( resource $handle , int $operation) 轻便的咨询文件锁定
锁类型 说明
LOCK_SH 取得共享锁定(读取的程序)
LOCK_EX 取得独占锁定(写入的程序
LOCK_UN 释放锁定(无论共享或独占)
例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<?php
$fp = fopen("demo.txt", "r+");
// 进行排它型锁定
if (flock($fp, LOCK_EX)) {
fwrite($fp, "文件这个时候被我独占了哟\n");
// 释放锁定
flock($fp, LOCK_UN);
} else {
echo "锁失败,可能有人在操作,这个时候不能将文件上锁";
}
fclose($fp);
?>
处理文件夹
处理文件夹的基本思想如下:
1.读取某个路径的时候判断是否是文件夹
2.是文件夹的话,打开指定文件夹,返回文件目录的资源变量
3.使用readdir读取一次目录中的文件,目录指针向后偏移一次
4.使用readdir读取到最后,没有可读的文件返回false
5.关闭文件目录
opendir 打开文件夹,返回操作资源
readdir 读取文件夹资源
is_dir 判断是否是文件夹
closedir 关闭文件夹操作资源
filetype 显示是文件夹还是文件,文件显示file,文件夹显示dir
例1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21<?php
//设置打开的目录是D盘
$dir = "d:/";
//判断是否是文件夹,是文件夹
if (is_dir($dir)) {
if ($dh = opendir($dir)) {
//读取一次向后移动一次文件夹指针
echo readdir($dh).'<br />';
echo readdir($dh).'<br />';
echo readdir($dh).'<br />';
echo readdir($dh).'<br />';
//读取到最后返回false
//关闭文件夹资源
closedir($dh);
}
}
?>
文件权限设置
函数用法与linux的权限操作的用法一样。
函数 功能说明
chmod 修改读取模式
chgrp 修改用户组
chown 修改权限
文件路径函数
array pathinfo ( string $路径)
功能:传入文件路径返回文件的各个组成部份1
2
3
4
5
6
7
8<?php
$path_parts = pathinfo('d:/www/index.inc.php');
echo '文件目录名:'.$path_parts['dirname']."<br />";//d:/www
echo '文件全名:'.$path_parts['basename']."<br />";//index.inc.php
echo '文件扩展名:'.$path_parts['extension']."<br />";//php
echo '不包含扩展的文件名:'.$path_parts['filename']."<br />"; //index.inc
?>
string basename ( string $路径[, string $suffix ])
功能:传入路径返回文件名
第一个参数传入路径。
第二个参数,指定我文件名到了指定字符停止。
dirname(string $路径)
功能:返回文件路径的文件目录部份
mixed parse_url ( string $路径 )
功能:将网址拆解成各个部份
string http_build_query ( mixed $需要处理的数据)
功能:生成url 中的query字符串1
2
3
4
5
6
7
8//定义一个关联数组
$data = [
'username'=>'php',
'area'=>'hubei'
];
//生成query内容
echo http_build_query($data);//username=php&area=hubei
http_build_url()
功能: 生成一个url