跑测试
重新听
transformer
to do
整理书中知识点
LangSmith
LangSmith
安装 LangSmith
1
pip install --upgrade langsmith
注册账号,并申请一个
LANGCHAIN_API_KEY在环境变量中设置以下值
1
2
3export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_PROJECT=YOUR_PROJECT_NAME #自定义项目名称(可选)
export LANGCHAIN_API_KEY=LANGCHAIN_API_KEY # LangChain API Key程序中的调用将自动被记录
1
2
3
4import os
from datetime import datetime
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_PROJECT"] = "hello-world-"+datetime.now().strftime("%d/%m/%Y %H:%M:%S")
基本功能
- Traces
- LLM Calls
- Monitor
- Playground
1 | from langchain.prompts import ( |
在线标注(在平台上进行标注)
上传已有数据集
定义评估函数
运行测试
基于 LLM 的评估函数
1 | https://docs.smith.langchain.com/evaluation/faq/evaluator-implementations |
Langfuse
维护一个生产级的 LLM 应用,我们需要做什么
- 各种指标监控与统计:访问记录、响应时长、Token 用量、计费等等
- 调试 Prompt
- 测试/验证系统的相关评估指标
- 数据集管理(便于回归测试)
- Prompt 版本管理(便于升级/回滚)
针对以上需求,目前有两个生产级 LLM App 维护平台
- LangFuse: 开源 + SaaS(免费/付费),LangSmith 平替,可集成 LangChain 也可直接对接 OpenAI API;
- LangSmith: LangChain 的官方平台,SaaS 服务(免费/付费),非开源,企业版支持私有部署;
根据自己的技术栈,选择:
- LangFuse:开源平台,支持 LangChain 和原生 OpenAI API
- LangSmith: LangChain 的原始管理平台
- Prompt Flow:开源平台,支持 Semantic Kernel
LangFuse
开源,支持 LangChain 集成或原生 OpenAI API 集成
项目地址:https://github.com/langfuse
文档地址:https://langfuse.com/docs
API文档:https://api.reference.langfuse.com/
- Python SDK:
https://python.reference.langfuse.com/ 通过官方云服务使用:
- 注册: cloud.langfuse.com
- 创建 API Key
1 | LANGFUSE_SECRET_KEY="sk-lf-..." |
- 通过 Docker 本地部署
1 | # Clone repository |
几个基本概念
- Trace 一般表示用户与系统的一次交互,其中记录输入、输出,也包括自定义的 metadata 比如用户名、session id 等;
- 一个 trace 内部可以包含多个子过程,这里叫 observarions;
- Observation 可以是多个类型:
- Event 是最基本的单元,用于记录一个 trace 中的每个事件;
- Span 表一个 trace 中的一个”耗时”的过程;
- Generation 是用于记录与 AI 模型交互的 span,例如:调用 embedding 模型、调用 LLM。
- Observation 可以嵌套使用。
通过装饰器记录(上报)
observe() 装饰器的参数
1 | def observe( |
1 | from langfuse.decorators import observe |
通过 langfuse_context 记录 User ID、Metadata 等
1 | from langfuse.decorators import observe, langfuse_context |
通过 LangChain 的回调集成
1 | from langfuse.decorators import langfuse_context, observe |
用 Trace 记录一个多次调用 LLM 的过程
1 | import uuid |
用 Session 记录一个用户的多轮对话
1 | @observe() |
数据集与测试
在线标注(在平台上进行标注)
上传已有数据集
定义评估函数
运行测试
Prompt 调优与回归测试
Prompt 版本管理
目前只支持 Langfuse 自己的 SDK
1 | # 按名称加载 |
如何比较两个句子的相似性:一些经典 NLP 的评测方法(选)
用途:比较llm 返回值和预期值,从而进行打分计算
- 编辑距离:也叫莱文斯坦距离(Levenshtein),是针对二个字符串的差异程度的量化量测,量测方式是看至少需要多少次的处理才能将一个字符串变成另一个字符串。
- 具体计算过程是一个动态规划算法:https://zhuanlan.zhihu.com/p/164599274
- 衡量两个句子的相似度时,可以以词为单位计算
- BLEU Score:
- 计算输出与参照句之间的 n-gram 准确率(n=1…4)
- 对短输出做惩罚
- 在整个测试集上平均下述值
- 函数库:https://www.nltk.org/_modules/nltk/translate/bleu_score.html
- Rouge Score:
- Rouge-N:将模型生成的结果和标准结果按 N-gram 拆分后,只计算召回率;
- Rouge-L: 利用了最长公共子序列(Longest Common Sequence)
- 函数库:https://pypi.org/project/rouge-score/
- 对比 BLEU 与 ROUGE:
- BLEU 能评估流畅度,但指标偏向于较短的翻译结果(brevity penalty 没有想象中那么强)
- ROUGE 不管流畅度,所以只适合深度学习的生成模型:结果都是流畅的前提下,ROUGE 反应参照句中多少内容被生成的句子包含(召回)
- METEOR: 另一个从机器翻译领域借鉴的指标。与 BLEU 相比,METEOR 考虑了更多的因素,如同义词匹配、词干匹配、词序等,因此它通常被认为是一个更全面的评价指标。
- 对语言学和语义词表有依赖,所以对语言依赖强。
此类方法常用于对文本生成模型的自动化评估。实际使用中,我们通常更关注相对变化而不是绝对值(调优过程中指标是不是在变好)。
基于 LLM 的测试方法
LangFuse 集成了一些原生的基于 LLM 的自动测试标准。
具体参考:https://langfuse.com/docs/scores/model-based-evals
划重点:此类方法,对于用于评估的 LLM 自身能力有要求。需根据具体情况选择使用。
LangChain
LangChain 也是一套面向大模型的开发框架(SDK)
- LangChain 是 AGI 时代软件工程的一个探索和原型
- 学习 LangChain 要关注接口变更
LangChain 的核心组件
- 模型 I/O 封装
- LLMs:大语言模型
- Chat Models:一般基于 LLMs,但按对话结构重新封装
- PromptTemple:提示词模板
- OutputParser:解析输出
- 数据连接封装
- Document Loaders:各种格式文件的加载器
- Document Transformers:对文档的常用操作,如:split, filter, translate, extract metadata, etc
- Text Embedding Models:文本向量化表示,用于检索等操作
- Verctorstores: (面向检索的)向量的存储
- Retrievers: 向量的检索
- 记忆封装
- Memory:这里不是物理内存,从文本的角度,可以理解为”上文”、”历史记录”或者说”记忆力”的管理
- 架构封装
- Chain:实现一个功能或者一系列顺序功能组合
- Agent:根据用户输入,自动规划执行步骤,自动选择每步需要的工具,最终完成用户指定的功能
- Tools:调用外部功能的函数,例如:调 google 搜索、文件 I/O、Linux Shell 等等
- Toolkits:操作某软件的一组工具集,例如:操作 DB、操作 Gmail 等等
- Callbacks
模型 I/O 封装
通过模型封装,实现不同模型的统一接口调用
1 | from langchain_openai import ChatOpenAI |
Prompt 模板封装
1 | from langchain.prompts import ( |
- PromptTemplate 可以在模板中自定义变量
- ChatPromptTemplate 用模板表示的对话上下文
- MessagesPlaceholder 把多轮对话变成模板
- 从文件加载 Prompt 模板: PromptTemplate.from_file
把Prompt模板看作带有参数的函数
输出封装 OutputParser
自动把 LLM 输出的字符串按指定格式加载。
LangChain 内置的 OutputParser 包括:
- ListParser
- DatetimeParser
- EnumParser
- JsonOutputParser
- PydanticParser
- XMLParser
等等
Pydantic (JSON) Parser
自动根据 Pydantic 类的定义,生成输出的格式说明
Auto-Fixing Parser
利用 LLM 自动根据解析异常修复并重新解析
小结
- LangChain 统一封装了各种模型的调用接口,包括补全型和对话型两种
- LangChain 提供了 PromptTemplate 类,可以自定义带变量的模板
- LangChain 提供了一些列输出解析器,用于将大模型的输出解析成结构化对象;额外带有自动修复功能。
- 上述模型属于 LangChain 中较为优秀的部分;美中不足的是 OutputParser 自身的 Prompt 维护在代码中,耦合度较高。
数据连接封装
1 | # 文档加载器:Document Loaders |
类似 LlamaIndex,LangChain 也提供了丰富的 Document Loaders 和 Text Splitters
小结
- 文档处理部分,建议在实际应用中详细测试后使用
- 与向量数据库的链接部分本质是接口封装,向量数据库需要自己选型
记忆封装:Memory
1 | # 对话上下文:ConversationBufferMemory |
更多类型
- ConversationSummaryMemory: 对上下文做摘要
- ConversationSummaryBufferMemory: 保存 Token 数限制内的上下文,对更早的做摘要
- VectorStoreRetrieverMemory: 将 Memory 存储在向量数据库中,根据用户输入检索回最相关的部分
小结
- LangChain 的 Memory 管理机制属于可用的部分,尤其是简单情况如按轮数或按 Token 数管理;
- 对于复杂情况,它不一定是最优的实现,例如检索向量库方式,建议根据实际情况和效果评估;
- 但是它对内存的各种维护方法的思路在实际生产中可以借鉴。
LangChain Expression Language(LCEL)是一种声明式语言,可轻松组合不同的调用顺序构成 Chain。LCEL 自创立之初就被设计为能够支持将原型投入生产环境,无需代码更改,从最简单的”提示+LLM”链到最复杂的链(已有用户成功在生产环境中运行包含数百个步骤的 LCEL Chain)。
LCEL 的一些亮点包括:
- 流支持
- 异步支持
- 优化的并行执行
- 重试和回退
- 访问中间结果
- 输入和输出模式
- 无缝 LangSmith 跟踪集成
- 无缝 LangServe 部署集成
原文:https://python.langchain.com/docs/expression_language/
Pipeline 式调用 PromptTemplate, LLM 和 OutputParser
1 | from langchain_openai import ChatOpenAI |
使用 LCEL 的价值,也就是 LangChain 的核心价值。
官方从不同角度给出了举例说明:https://python.langchain.com/docs/expression_language/why
通过 LCEL,还可以实现
- 配置运行时变量:https://python.langchain.com/docs/expression_language/how_to/configure
- 故障回退:https://python.langchain.com/docs/expression_language/how_to/fallbacks
- 并行调用:https://python.langchain.com/docs/expression_language/how_to/map
- 逻辑分支:https://python.langchain.com/docs/expression_language/how_to/routing
- 调用自定义流式函数:https://python.langchain.com/docs/expression_language/how_to/generators
- 链接外部 Memory:https://python.langchain.com/docs/expression_language/how_to/message_history
更多例子:https://python.langchain.com/docs/expression_language/cookbook/
什么是智能体(Agent)
将大语言模型作为一个推理引擎, 给定一个任务,智能体自动生成完成任务所需的步骤,执行相应动作(例如选择并调用工具),直到任务完成。
先定义一些工具:Tools
- 可以是一个函数或三方 API
- 也可以把一个 Chain 或者 Agent 的 run()作为一个 Tool
下载一个现有的 Prompt 模板
1 | react_prompt = hub.pull("hwchase17/react") |
直接定义执行执行调用
1 | from langchain_openai import ChatOpenAI |
LangServe
LangServe 用于将 Chain 或者 Runnable 部署成一个 REST API 服务。
1 | # 安装 LangServe |
LangChain.js
Python 版 LangChain 的姊妹项目,都是由 Harrison Chase 主理。
项目地址:https://github.com/langchain-ai/langchainjs
文档地址:https://js.langchain.com/docs/
特色:
- 可以和 Python 版 LangChain 无缝对接
- 抽象设计完全相同,概念一一对应
- 所有对象序列化后都能跨语言使用,但 API 差别挺大,不过在努力对齐
支持环境:
- Node.js (ESM and CommonJS) - 18.x, 19.x, 20.x
- Cloudflare Workers
- Vercel / Next.js (Browser, Serverless and Edge functions)
- Supabase Edge Functions
- Browser
- Deno
安装:
1 | npm install langchain |
当前重点:
- 追上 Python 版的能力(甚至为此做了一个基于 gpt-3.5-turbo 的代码翻译器)
- 保持兼容尽可能多的环境
- 对质量关注不多,随时间自然能解决
LangChain 与 LlamaIndex 的错位竞争
- LangChain 侧重与 LLM 本身交互的封装
- Prompt、LLM、Memory、OutputParser 等工具丰富
- 在数据处理和 RAG 方面提供的工具相对粗糙
- 主打 LCEL 流程封装
- 配套 Agent、LangGraph 等智能体与工作流工具
- 另有 LangServe 部署工具和 LangSmith 监控调试工具
- LlamaIndex 侧重与数据交互的封装
- 数据加载、切割、索引、检索、排序等相关工具丰富
- Prompt、LLM 等底层封装相对单薄
- 配套实现 RAG 相关工具
- 有 Agent 相关工具,不突出
- LlamaIndex 为 LangChain 提供了集成
- 在 LlamaIndex 中调用 LangChain 封装的 LLM 接口:https://docs.llamaindex.ai/en/stable/api_reference/llms/langchain/
- 将 LlamaIndex 的 Query Engine 作为 LangChain Agent 的工具:https://docs.llamaindex.ai/en/v0.10.17/community/integrations/using_with_langchain.html
- LangChain 也曾经集成过 LlamaIndex,目前相关接口仍在:https://api.python.langchain.com/en/latest/retrievers/langchain_community.retrievers.llama_index.LlamaIndexRetriever.html
llamaindex
LlamaIndex 简介
LlamaIndex 是一个为开发「上下文增强」的大语言模型应用的框架(也就是 SDK)。上下文增强,泛指任何在私有或特定领域数据基础上应用大语言模型的情况。例如:
- Question-Answering Chatbots (也就是 RAG)
- Document Understanding and Extraction (文档理解与信息抽取)
- Autonomous Agents that can perform research and take actions (智能体应用)
LlamaIndex 有 Python 和 Typescript 两个版本,Python 版的文档相对更完善。
- Python 文档地址:
https://docs.llamaindex.ai/en/stable/ - Python API 接口文档:
https://docs.llamaindex.ai/en/stable/api_reference/ - TS 文档地址:
https://ts.llamaindex.ai/ - TS API 接口文档:
https://ts.llamaindex.ai/api/
LlamaIndex 是一个开源框架,Github 链接:
https://github.com/run-llama
1 | pip install llama-index |
数据加载
加载本地数据
SimpleDirectoryReader 是一个简单的本地文件加载器。它会遍历指定目录,并根据文件扩展名自动加载文件(文本内容)。
默认的 PDFReader 效果并不理想,我们可以更换文件加载器:
1 | pip install pymupdf |
更多的 PDF 加载器还有 SmartPDFLoader 和 LlamaParse, 二者都提供了更丰富的解析能力,包括解析章节与段落结构等。但不是 100%准确,偶有文字丢失或错位情况,建议根据自身需求详细测试评估。
Data Connectors
对图像、视频、语音类文件,默认不会自动提取其中文字。如需提取, 需要对应读取器。
处理更丰富的数据类型,并将其读取为 Document 的形式(text + metadata)。
文本切分与解析(Chunking)
LlamaIndex 中,Node 被定义为一个文本的「chunk」。
使用 TextSplitters 对文本做切分
1 | from llama_index.core.node_parser import TokenTextSplitter |
LlamaIndex 提供了丰富的 TextSplitter,例如:
- SentenceSplitter: 在切分指定长度的 chunk 同时尽量保证句子边界不被切断;
- CodeSplitter: 根据 AST(编译器的抽象句法树)切分代码,保证代码功能片段完整;
- SemanticSplitterNodeParser: 根据语义相关性对将文本切分为片段
使用 NodeParsers 对有结构的文档做解析
更多的 NodeParser 包括 HTMLNodeParser,JSONNodeParser等等。
索引(Indexing)与检索(Retrieval)
基础概念:在「检索」相关的上下文中,「索引」即 index, 通常是指为了实现快速检索而设计的特定「数据结构」。
向量检索
- SimpleVectorStore 直接在内存中构建一个 Vector Store 并建索引
LlamaIndex 默认的 Embedding 模型是 OpenAIEmbedding(model="text-embedding-ada-002")。
- 使用自定义的 Vector Store,以
Chroma为例:
1 | pip install llama-index-vector-stores-chroma |
更多索引与检索方式
LlamaIndex 内置了丰富的检索机制,例如:
关键字检索
- BM25Retriever:基于 tokenizer 实现的 BM25 经典检索算
- KeywordTableGPTRetriever:使用 GPT 提取检索关键字
- KeywordTableSimpleRetriever:使用正则表达式提取检索关键字
- KeywordTableRAKERetriever:使用RAKE算法提取检索关键字(有语言限制)
- RAG-Fusion QueryFusionRetriever
还支持 KnowledgeGraph、SQL、Text-to-SQL 等等
Ingestion Pipeline 自定义数据处理流程
LlamaIndex 通过 Transformations 定义一个数据(Documents)的多步处理的流程(Pipeline)。
这个 Pipeline 的一个显著特点是,它的每个子步骤是可以缓存(cache)的,即如果该子步骤的输入与处理方法不变,重复调用时会直接从缓存中获取结果,而无需重新执行该子步骤,这样即节省时间也会节省 token (如果子步骤涉及大模型调用)。
此外,也可以用远程的 Redis 或 MongoDB 等存储 IngestionPipeline 的缓存,具体参考官方文档:Remote Cache Management。
IngestionPipeline 也支持异步和并发调用,请参考官方文档:Async Support、Parallel Processing。
检索后处理
LlamaIndex 的 Node Postprocessors 提供了一系列检索后处理模块。
更多的 Rerank 及其它后处理方法,参考官方文档:Node Postprocessor Modules
生成回复(QA & Chat)
单轮问答(Query Engine)
1 | qa_engine = index.as_query_engine() |
流式输出
1 | qa_engine = index.as_query_engine(streaming=True) |
多轮对话(Chat Engine)
1 | chat_engine = index.as_chat_engine() |
流式输出
1 | chat_engine = index.as_chat_engine() |
底层接口:Prompt、LLM 与 Embedding
Prompt 模板
PromptTemplate 定义提示词模板
1 | prompt = PromptTemplate("写一个关于{topic}的笑话") |
ChatPromptTemplate 定义多轮消息模板
1 | from llama_index.core.llms import ChatMessage, MessageRole |
语言模型
1 | from llama_index.llms.openai import OpenAI |
设置全局使用的语言模型
1 | from llama_index.core import Settings |
除 OpenAI 外,LlamaIndex 已集成多个大语言模型,包括云服务 API 和本地部署 API,详见官方文档:Available LLM integrations
Embedding 模型
1 | from llama_index.embeddings.openai import OpenAIEmbedding |
全局设定
1 | Settings.embed_model = OpenAIEmbedding(model="text-embedding-3-small", dimensions=512) |
LlamaIndex 同样集成了多种 Embedding 模型,包括云服务 API 和开源模型(HuggingFace)等,详见官方文档。
1 | 基于 LlamaIndex 实现一个功能较完整的 RAG 系统 |
LlamaIndex 的更多功能
- 智能体(Agent)开发框架:
https://docs.llamaindex.ai/en/stable/module_guides/deploying/agents/ - RAG 的评测:
https://docs.llamaindex.ai/en/stable/module_guides/evaluating/ - 过程监控:
https://docs.llamaindex.ai/en/stable/module_guides/observability/
以上内容涉及较多背景知识,暂时不在本课展开,相关知识会在后面课程中逐一详细讲解。
此外,LlamaIndex 针对生产级的 RAG 系统中遇到的各个方面的细节问题,总结了很多高端技巧(Advanced Topics),对实战很有参考价值,非常推荐有能力的同学阅读。
AssistantsAPI
Assistants API
https://platform.openai.com/docs/assistants/overview

Assistants API 的主要能力
已有能力:
- 创建和管理 assistant,每个 assistant 有独立的配置
- 支持无限长的多轮对话,对话历史保存在 OpenAI 的服务器上
- 通过自有向量数据库支持基于文件的 RAG
- 支持 Code Interpreter
a. 在沙箱里编写并运行 Python 代码
b. 自我修正代码
c. 可传文件给 Code Interpreter - 支持 Function Calling
- 支持在线调试的 Playground
承诺未来会有的能力:
- 支持 DALL·E
- 支持图片消息
- 支持自定义调整 RAG 的配置项
收费:
- 按 token 收费。无论多轮对话,还是 RAG,所有都按实际消耗的 token 收费
- 如果对话历史过多超过大模型上下文窗口,会自动放弃最老的对话消息
- 文件按数据大小和存放时长收费。1 GB 向量存储 一天收费 0.10 美元
- Code interpreter 跑一次 $0.03
划重点:使用 assistant 的意义之一,是可以隔离不同角色的 instruction 和 function 能力。
可以为每个应用,甚至应用中的每个有对话历史的使用场景,创建一个 assistant。
1 | assistant = client.beta.assistants.create( |
管理 thread
Threads:
- Threads 里保存的是对话历史,即 messages
- 一个 assistant 可以有多个 thread
- 一个 thread 可以有无限条 message
- 一个用户与 assistant 的多轮对话历史可以维护在一个 thread 里
1 | # 可以根据需要,自定义 `metadata`,比如创建 thread 时,把 thread 归属的用户信息存入。也可以不传 |
Thread ID 如果保存下来,是可以在下次运行时继续对话的。
从 thread ID 获取 thread 对象的代码
1 | thread = client.beta.threads.retrieve(thread.id) |
此外,还有:
- threads.modify() 修改 thread 的 metadata和tool_resources
- threads.retrieve() 获取 thread
- threads.delete() 删除 thread。
具体文档参考:https://platform.openai.com/docs/api-reference/threads
给 Threads 添加 Messages
这里的 messages 结构要复杂一些:
- 不仅有文本,还可以有图片和文件
- 也有metadata
1 |
|
还有如下函数:
- threads.messages.retrieve() 获取 message
- threads.messages.update() 更新 message 的 metadata
- threads.messages.list() 列出给定 thread 下的所有 messages
具体文档参考:https://platform.openai.com/docs/api-reference/messages
也可以在创建 thread 同时初始化一个 message 列表
1 | thread = client.beta.threads.create( |
开始 Run
- 用 run 把 assistant 和 thread 关联,进行对话
- 一个 prompt 就是一次 run
(执行一次run, 如果run 入参的thread 里面携带(有绑定)message 就相当于向LLM 进行一次提问)
1 | assistant_id = "asst_ahXpE6toS71zFyq9h4iMIDj2" # 从 Playground 中拷贝 |
Run 的底层是个异步调用,意味着它不等大模型处理完,就返回。我们通过 run.status了解大模型的工作进展情况,来判断下一步该干什么。
run.status 有的状态,和状态之间的转移关系如图。
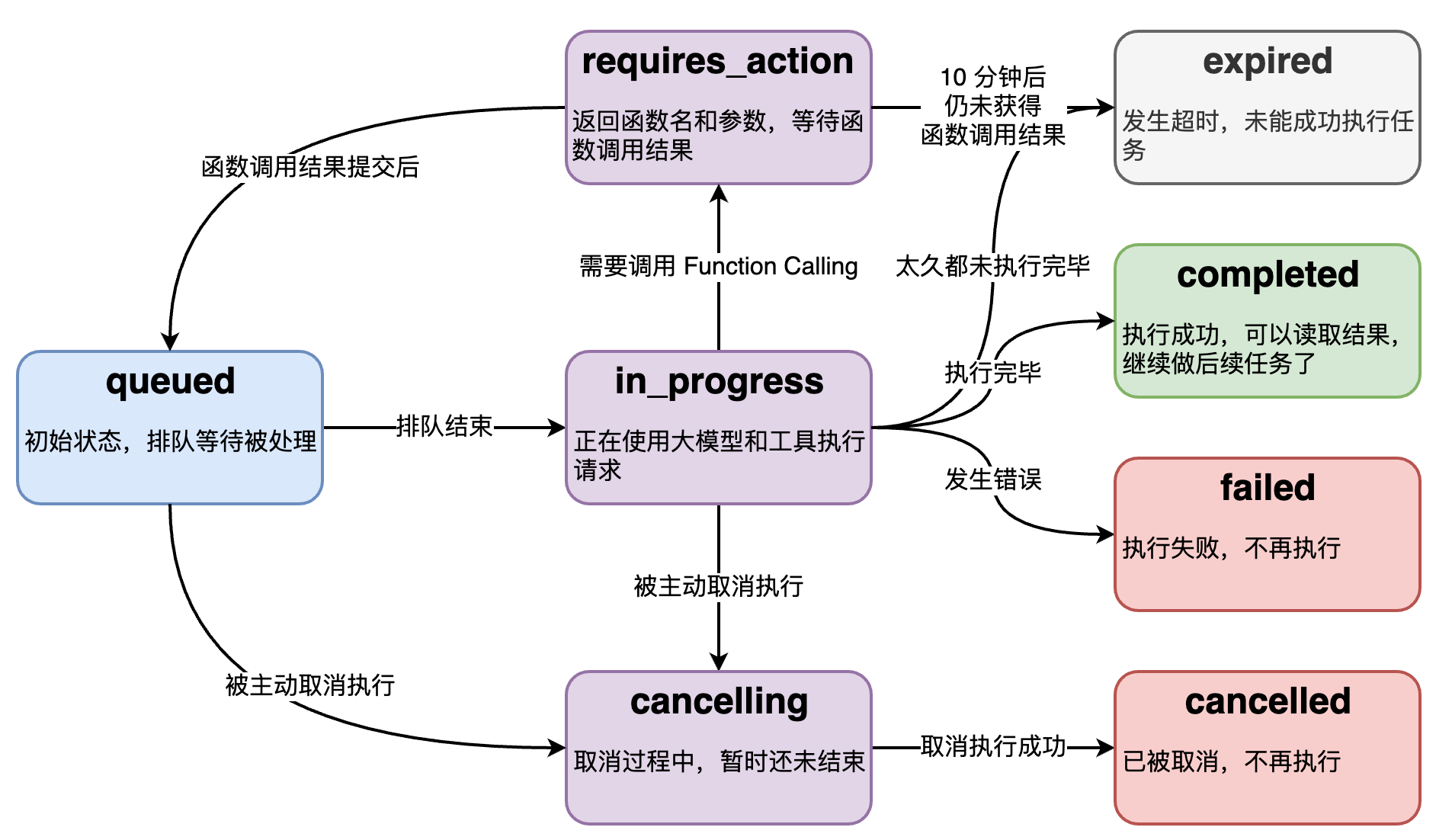
流式运行
- 创建回调函数
1 | from typing_extensions import override |
更多流中的 Event: https://platform.openai.com/docs/api-reference/assistants-streaming/events
- 运行 run
1 | # 添加新一轮的 user message |
还有如下函数:
- threads.runs.list() 列出 thread 归属的 run
- threads.runs.retrieve() 获取 run
- threads.runs.update() 修改 run 的 metadata
- threads.runs.cancel() 取消 in_progress 状态的 run
具体文档参考:https://platform.openai.com/docs/api-reference/runs
使用 Tools
创建 Assistant 时声明 Code_Interpreter
1 | 如果用代码创建: |
发个 Code Interpreter 请求
1 | # 创建 thread |
Code_Interpreter 操作文件
1 | # 上传文件到 OpenAI |
关于文件操作,还有如下函数:
- client.files.list() 列出所有文件
- client.files.retrieve() 获取文件对象
- client.files.delete() 删除文件
- client.files.content() 读取文件内容
具体文档参考:https://platform.openai.com/docs/api-reference/files
创建 Assistant 时声明 Function calling
1 | assistant = client.beta.assistants.create( |
两个无依赖的 function 会在一次请求中一起被调用
1 | # 创建 thread |
创建 Assistant 时声明file_search
tool.type 为file_search时相当于内置的 RAG 功能
创建 Vector Store,上传文件
- 通过代码创建 Vector Store
1 | vector_store = client.beta.vector_stores.create( |
Vector store 和 vector store file 也有对应的 list,retrieve 和 delete等操作。
具体文档参考:
- Vector store: https://platform.openai.com/docs/api-reference/vector-stores
- Vector store file: https://platform.openai.com/docs/api-reference/vector-stores-files
- Vector store file 批量操作: https://platform.openai.com/docs/api-reference/vector-stores-file-batches
创建 Assistant 时声明 RAG 能力
RAG 实际被当作一种 tool
1 | assistant = client.beta.assistants.create( |
指定检索源
1 | assistant = client.beta.assistants.update( |
RAG 请求
1 | # 创建 thread |
多个 Assistants 协作
划重点: 使用 assistant 的意义之一,是可以隔离不同角色的 instruction 和 function 能力。
6顶思维帽实验
技术选型参考
GPTs 现状:
- 界面不可定制,不能集成进自己的产品
- 只有 ChatGPT Plus/Team/Enterprise 用户才能访问
- 未来开发者可以根据使用量获得报酬,北美先开始
- 承诺会推出 Team/Enterprise 版的组织内部专属 GPTs
适合使用 Assistants API 的场景:
- 定制界面,或和自己的产品集成
- 需要传大量文件
- 服务国外用户,或国内 B 端客户
- 数据保密性要求不高
- 不差钱
适合使用原生 API 的场景:
- 需要极致调优
- 追求性价比
- 服务国外用户,或国内 B 端客户
- 数据保密性要求不高
适合使用国产或开源大模型的场景:
- 服务国内用户
- 数据保密性要求高
- 压缩长期成本
- 需要极致调优
RAG
LLM 固有的局限性 🔗
- LLM 的知识不是实时的
- LLM 可能不知道你私有的领域/业务知识
RAG 通过给LLM 增加额外/专有知识文档,提高LLM 回答问题的准确性

搭建过程:
- 文档加载,并按一定条件切割成片段
- 将切割的文本片段灌入检索引擎
- 封装检索接口
- 构建调用流程:Query -> 检索 -> Prompt -> LLM -> 回复
关键字检索的局限性
同一个语义,用词不同,可能导致检索不到有效的结果
解决办法===> 向量检索
向量检索
二维空间中的向量可以表示为(x,y) 表示从原点(0,0) 到点 (x,y) 的有向线段。
以此类推,我可以用一组坐标 (x0,x1,…..xN) 表示一个𝑁 维空间中的向量,𝑁 叫向量的维度。
文本向量(Text Embeddings)
- 将文本转成一组 𝑁 维浮点数,即文本向量又叫 Embeddings
- 向量之间可以计算距离,距离远近对应语义相似度大小
文本向量是怎么得到的 🔗
- 构建相关(正立)与不相关(负例)的句子对儿样本
- 训练双塔式模型,让正例间的距离小,负例间的距离大
向量间的相似度计算
余弦距离 – 越大越相似
欧氏距离 – 越小越相似
向量数据库,是专门为向量检索设计的中间件
澄清几个关键概念:
- 向量数据库的意义是快速的检索;
- 向量数据库本身不生成向量,向量是由 Embedding 模型产生的;
- 向量数据库与传统的关系型数据库是互补的,不是替代关系,在实际应用中根据实际需求经常同时使用。
划重点:
- 不是每个 Embedding 模型都对余弦距离和欧氏距离同时有效
- 哪种相似度计算有效要阅读模型的说明(通常都支持余弦距离计算)
优化方向
文本分割的粒度 🔗
缺陷
- 粒度太大可能导致检索不精准,粒度太小可能导致信息不全面
- 问题的答案可能跨越两个片段
改进: 按一定粒度,部分重叠式的切割文本,使上下文更完整
检索后排序 🔗
问题: 有时,最合适的答案不一定排在检索的最前面
方案:
- 检索时过招回一部分文本
- 通过一个排序模型对 query 和 document 重新打分排序
混合检索(Hybrid Search)
在实际生产中,传统的关键字检索(稀疏表示)与向量检索(稠密表示)各有优劣。
举个具体例子,比如文档中包含很长的专有名词,关键字检索往往更精准而向量检索容易引入概念混淆。
有时候我们需要结合不同的检索算法,来达到比单一检索算法更优的效果。这就是混合检索。
混合检索的核心是,综合文档 𝑑 在不同检索算法下的排序名次(rank),为其生成最终排序。
一个最常用的算法叫 Reciprocal Rank Fusion(RRF)
RAG-Fusion
RAG-Fusion 就是利用了 RRF 的原理来提升检索的准确性。
从AI编程认知AI
一些产品设计的思想
划重点:
- 凡是重复脑力劳动都可以考虑 AI 化
- 凡是「输入和输出都是文本」的场景,都值得尝试用大模型提效
如何理解 AI 能编写程序
编程能力是大模型各项能力的天花板
- 「编程」是目前大模型能力最强的垂直领域,甚至超越了对「自然语言」本身的处理能力。因为:
- 训练数据质量高
- 结果可衡量
- 编程语言无二义性
- 有论文
- “The first model that OpenAI gave us was a Python-only model,” Ziegler remembers. “Next we were delivered a JavaScript model and a multilingual model, and it turned out that the Javascript model had particular problems that the multilingual model did not. It actually came as a surprise to us that the multilingual model could perform so well. But each time, the models were just getting better and better, which was really exciting for GitHub Copilot’s progress.” –Inside GitHub: Working with the LLMs behind GitHub Copilot
- 知道怎么用好 AI 编程,了解它的能力边界、使用场景,就能类比出在其他领域 AI 怎么落地,能力上限在哪
划重点:
- 使用 AI 编程,除了解决编程问题以外,更重要是形成对 AI 的正确认知。
- 数据质量决定 AI 的质量。
一些技巧
- 代码有了,再写注释,更省力
- 改写当前代码,可另起一块新写,AI 补全得更准,完成后再删旧代码
- Cmd/Ctrl + → 只接受一个 token
- 如果有旧代码希望被参考,就把代码文件在新 tab 页里打开
产品设计经验:在 chat 界面里用 @ 串联多个 agent 是一个常见的 AI 产品设计范式。
产品设计经验:让 AI 在不影响用户原有工作习惯的情况下切入使用场景,接受度最高。
产品设计经验:流程化操作步步都需要人工调整、确认
落地经验:只有可量化的结果,才能说服老板买单
GitHub Copilot 基本原理
工作原理
- 模型层:最初使用 OpenAI Codex 模型,它也是 GPT-3.5、GPT-4 的「一部分」。
现在已经完全升级,模型细节未知。 - 应用层: prompt engineering。Prompt 中包含:
a. 组织上下文:光标前和光标后的代码片段
b. 获取代码片段:其它相关代码片段。当前文件和其它打开的同语言文件 tab 里的代码被切成每个 60 行的片段,用Jaccard 相似度- 为什么是打开的 tabs?
- 多少个 tabs 是有效的呢?经验选择:20 个
c. 修饰相关上下文:被取用的代码片段的路径。
d. 优先级:根据一些代码常识判断补全输入内容的优先级
e. 补全格式:在函数定义、类定义、if-else 等之后,会补全整段代码,其它时候只补全当前行
有效性:
- Telemetry(远程遥测如何取消)
- A/B Test
- 智谱的度量方式
AI 能力定律:
AI 能力的上限,是使用者的判断力
AI 能力=min(AI 能力,使用者判断力)
AI 提效定律:
AI 提升的效率,与使用者的判断力成正比,与生产力成反比
效率提升幅度 = 使用者判断力/使用者生产力
解读:
- 使用者的判断力,是最重要的
- 提升判断力,比提升实操能力更重要。所谓「眼高手低」者的福音
- 广阔的视野是判断力的养料
要点总结:
- 通过天天使用,总结使用大模型的规律,认知:凡是「输入和输出都是文本」的场景,都值得尝试用大模型提效。
- 通过体验 GitHub Copilot,认知:AI 产品的打磨过程、落地和目前盈利产品如何打造
- 通过介绍原理,认知:AI 目前的上限,以及 AI 组织数据和达到上限的条件
- 对于 AI 产品如何反馈有效性,认知:AI 产品落地的有效性管理方法
- 通过介绍两大定律,认知:AI 幻觉不可消灭; AI 的能效;
以成功案例为例,理解基本原理,避免拍脑袋
Function Calling
为什么要大模型连接外部世界?
大模型两大缺陷:
- 并非知晓一切
a. 训练数据不可能什么都有。垂直、非公开数据必有欠缺
b. 不知道最新信息。大模型的训练周期很长,且更新一次耗资巨大,还有越训越傻的风险。所以 ta 不可能实时训练。
ⅰ. GPT-3.5 知识截至 2021 年 9 月
ⅱ. GPT-4-turbo 知识截至 2023 年 12 月
ⅲ. GPT-4o 知识截至 2023 年 10 月 - 没有「真逻辑」。它表现出的逻辑、推理,是训练文本的统计规律,而不是真正的逻辑,所以有幻觉。
所以:大模型需要连接真实世界,并对接真逻辑系统执行确定性任务。
ChatGPT 用 Actions 连接外部世界
划重点:
- 通过 Actions 的 schema,GPT 能读懂各个 API 能做什么、怎么调用(相当于人读 API 文档)
- 拿到 prompt,GPT 分析出是否要调用 API 才能解决问题(相当于人读需求)
- 如果要调用 API,生成调用参数(相当于人编写调用代码)
- ChatGPT(注意,不是 GPT)调用 API(相当于人运行程序)
- API 返回结果,GPT 读懂结果,整合到回答中(相当于人整理结果,输出结论)
把 AI 当人看!
Function Calling 的机制
原理和 Actions 一样,只是使用方式有区别。
Function Calling 完整的官方接口文档:
https://platform.openai.com/docs/guides/function-calling

划重点:
- Function Calling 中的函数与参数的描述也是一种 Prompt
- 这种 Prompt 也需要调优,否则会影响函数的召回、参数的准确性,甚至让 GPT 产生幻觉
- 函数声明是消耗 token 的。要在功能覆盖、省钱、节约上下文窗口之间找到最佳平衡
- Function Calling 不仅可以调用读函数,也能调用写函数。但官方强烈建议,在写之前,一定要有真人做确认
1 | from math import * |
更多练习
本地单函数调用
本地多Function 调用(根据name 识别调用不同函数)
通过 Function Calling 查询单数据库
用 Function Calling 实现多表查询(把多表的描述给进去就好了)
Stream 模式(流式(stream)输出不会一次返回完整 JSON 结构,所以需要拼接后再使用,拿到什么就输出什么可减少用户等待时间,调用时client.chat.completions.create设置stream=True即可