Assistants API
https://platform.openai.com/docs/assistants/overview

Assistants API 的主要能力
已有能力:
- 创建和管理 assistant,每个 assistant 有独立的配置
- 支持无限长的多轮对话,对话历史保存在 OpenAI 的服务器上
- 通过自有向量数据库支持基于文件的 RAG
- 支持 Code Interpreter
a. 在沙箱里编写并运行 Python 代码
b. 自我修正代码
c. 可传文件给 Code Interpreter - 支持 Function Calling
- 支持在线调试的 Playground
承诺未来会有的能力:
- 支持 DALL·E
- 支持图片消息
- 支持自定义调整 RAG 的配置项
收费:
- 按 token 收费。无论多轮对话,还是 RAG,所有都按实际消耗的 token 收费
- 如果对话历史过多超过大模型上下文窗口,会自动放弃最老的对话消息
- 文件按数据大小和存放时长收费。1 GB 向量存储 一天收费 0.10 美元
- Code interpreter 跑一次 $0.03
划重点:使用 assistant 的意义之一,是可以隔离不同角色的 instruction 和 function 能力。
可以为每个应用,甚至应用中的每个有对话历史的使用场景,创建一个 assistant。
1 | assistant = client.beta.assistants.create( |
管理 thread
Threads:
- Threads 里保存的是对话历史,即 messages
- 一个 assistant 可以有多个 thread
- 一个 thread 可以有无限条 message
- 一个用户与 assistant 的多轮对话历史可以维护在一个 thread 里
1 | # 可以根据需要,自定义 `metadata`,比如创建 thread 时,把 thread 归属的用户信息存入。也可以不传 |
Thread ID 如果保存下来,是可以在下次运行时继续对话的。
从 thread ID 获取 thread 对象的代码
1 | thread = client.beta.threads.retrieve(thread.id) |
此外,还有:
- threads.modify() 修改 thread 的 metadata和tool_resources
- threads.retrieve() 获取 thread
- threads.delete() 删除 thread。
具体文档参考:https://platform.openai.com/docs/api-reference/threads
给 Threads 添加 Messages
这里的 messages 结构要复杂一些:
- 不仅有文本,还可以有图片和文件
- 也有metadata
1 |
|
还有如下函数:
- threads.messages.retrieve() 获取 message
- threads.messages.update() 更新 message 的 metadata
- threads.messages.list() 列出给定 thread 下的所有 messages
具体文档参考:https://platform.openai.com/docs/api-reference/messages
也可以在创建 thread 同时初始化一个 message 列表
1 | thread = client.beta.threads.create( |
开始 Run
- 用 run 把 assistant 和 thread 关联,进行对话
- 一个 prompt 就是一次 run
(执行一次run, 如果run 入参的thread 里面携带(有绑定)message 就相当于向LLM 进行一次提问)
1 | assistant_id = "asst_ahXpE6toS71zFyq9h4iMIDj2" # 从 Playground 中拷贝 |
Run 的底层是个异步调用,意味着它不等大模型处理完,就返回。我们通过 run.status了解大模型的工作进展情况,来判断下一步该干什么。
run.status 有的状态,和状态之间的转移关系如图。
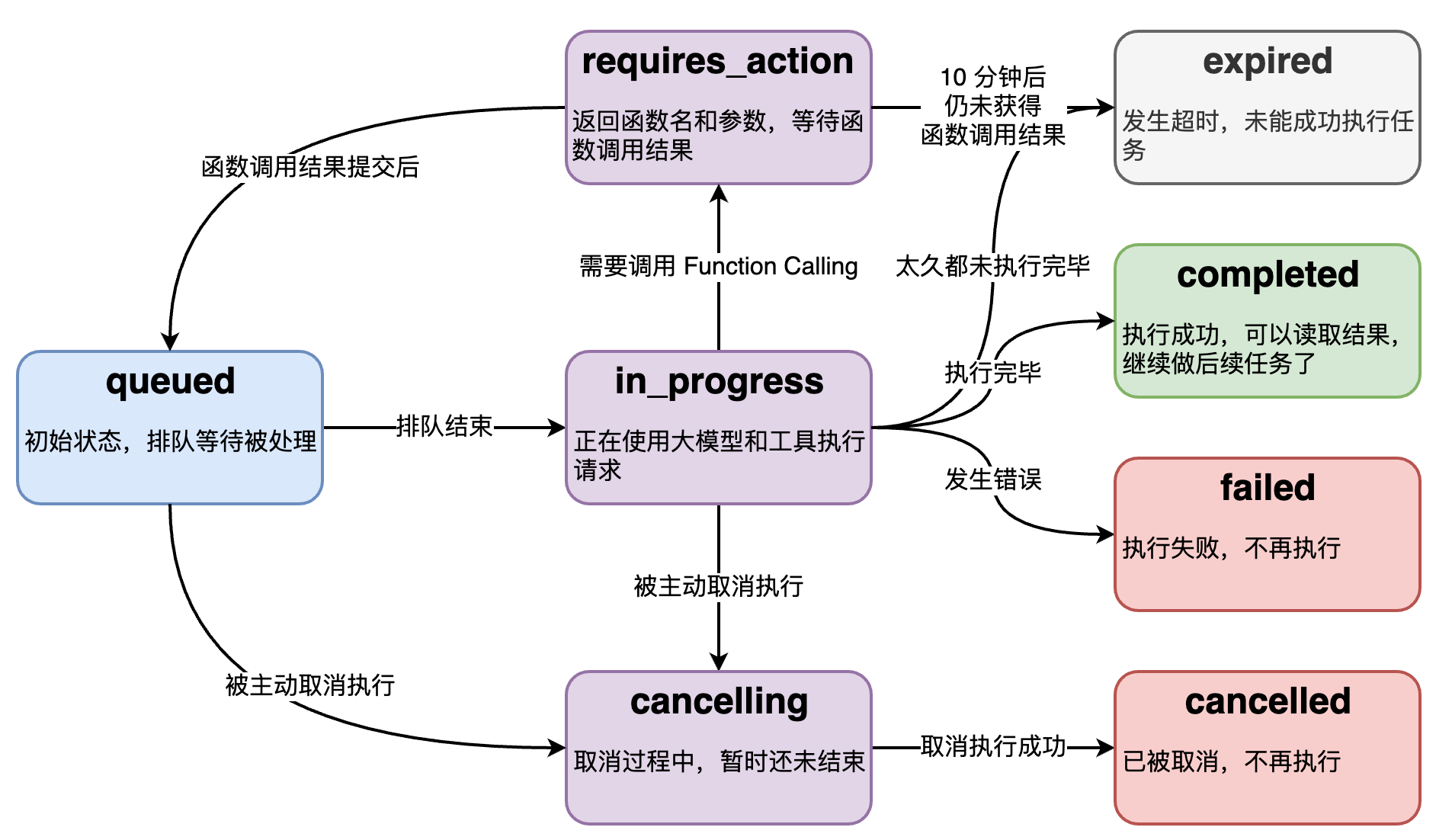
流式运行
- 创建回调函数
1 | from typing_extensions import override |
更多流中的 Event: https://platform.openai.com/docs/api-reference/assistants-streaming/events
- 运行 run
1 | # 添加新一轮的 user message |
还有如下函数:
- threads.runs.list() 列出 thread 归属的 run
- threads.runs.retrieve() 获取 run
- threads.runs.update() 修改 run 的 metadata
- threads.runs.cancel() 取消 in_progress 状态的 run
具体文档参考:https://platform.openai.com/docs/api-reference/runs
使用 Tools
创建 Assistant 时声明 Code_Interpreter
1 | 如果用代码创建: |
发个 Code Interpreter 请求
1 | # 创建 thread |
Code_Interpreter 操作文件
1 | # 上传文件到 OpenAI |
关于文件操作,还有如下函数:
- client.files.list() 列出所有文件
- client.files.retrieve() 获取文件对象
- client.files.delete() 删除文件
- client.files.content() 读取文件内容
具体文档参考:https://platform.openai.com/docs/api-reference/files
创建 Assistant 时声明 Function calling
1 | assistant = client.beta.assistants.create( |
两个无依赖的 function 会在一次请求中一起被调用
1 | # 创建 thread |
创建 Assistant 时声明file_search
tool.type 为file_search时相当于内置的 RAG 功能
创建 Vector Store,上传文件
- 通过代码创建 Vector Store
1 | vector_store = client.beta.vector_stores.create( |
Vector store 和 vector store file 也有对应的 list,retrieve 和 delete等操作。
具体文档参考:
- Vector store: https://platform.openai.com/docs/api-reference/vector-stores
- Vector store file: https://platform.openai.com/docs/api-reference/vector-stores-files
- Vector store file 批量操作: https://platform.openai.com/docs/api-reference/vector-stores-file-batches
创建 Assistant 时声明 RAG 能力
RAG 实际被当作一种 tool
1 | assistant = client.beta.assistants.create( |
指定检索源
1 | assistant = client.beta.assistants.update( |
RAG 请求
1 | # 创建 thread |
多个 Assistants 协作
划重点: 使用 assistant 的意义之一,是可以隔离不同角色的 instruction 和 function 能力。
6顶思维帽实验
技术选型参考
GPTs 现状:
- 界面不可定制,不能集成进自己的产品
- 只有 ChatGPT Plus/Team/Enterprise 用户才能访问
- 未来开发者可以根据使用量获得报酬,北美先开始
- 承诺会推出 Team/Enterprise 版的组织内部专属 GPTs
适合使用 Assistants API 的场景:
- 定制界面,或和自己的产品集成
- 需要传大量文件
- 服务国外用户,或国内 B 端客户
- 数据保密性要求不高
- 不差钱
适合使用原生 API 的场景:
- 需要极致调优
- 追求性价比
- 服务国外用户,或国内 B 端客户
- 数据保密性要求不高
适合使用国产或开源大模型的场景:
- 服务国内用户
- 数据保密性要求高
- 压缩长期成本
- 需要极致调优