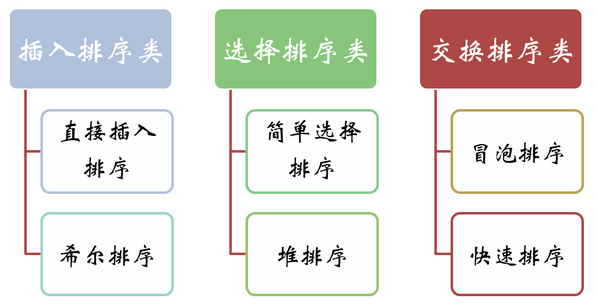
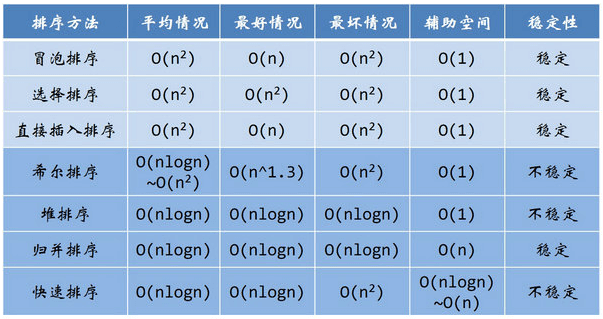
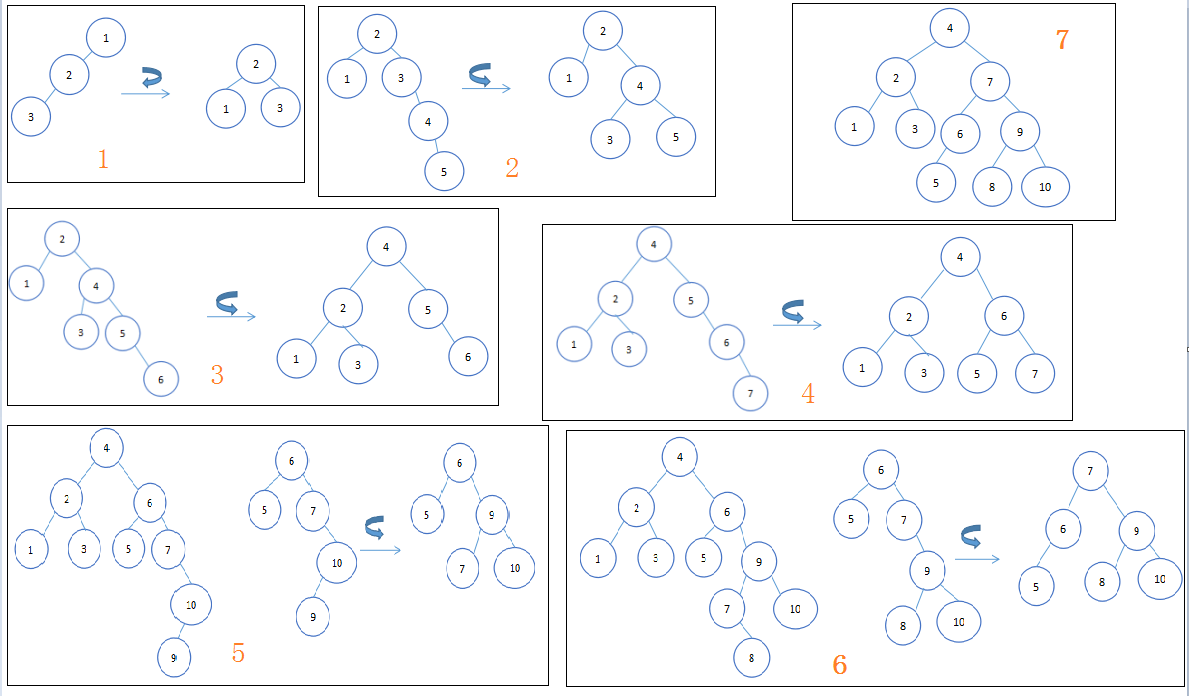
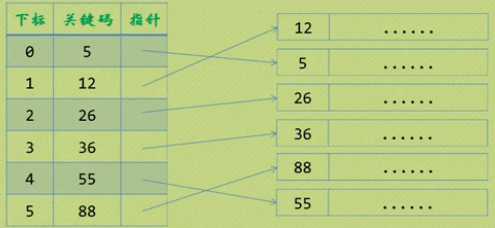
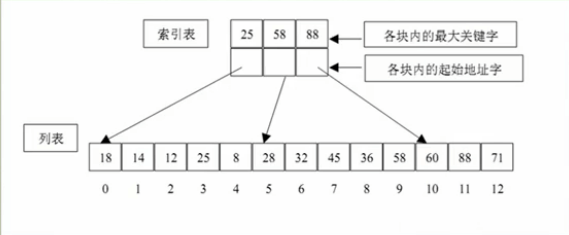
正则表达示主要用在以下一些地方:
1.匹配邮箱、手机号码、验证码
2.替换敏感的关键词。例如:涉及政治和骂人的话
3.文章采集。
4.早期的表情替换技术,ubb文件编码、markdown编辑器替换等
5.以后自己写模板引擎也需要用到正则表达示
正则表达式常见项目场景
开发工具中批量替换
客户端,服务端数据校验
客户端HTML检索(Sizzle)
服务端文本提取
数据爬虫的实现
定界符
定界符,就是定一个边界,边界已内的就是正则表达示
定界符,不能用a-zA-Z0-9\ 其他的都可以用。必须成对出现,有开始就有结束。
/中间写正则/ 正确
$中间写正则$ 正确
%中间写正则% 正确
^中间写正则^ 正确
@中间写正则@ 正确
(中间写正则) 错误
A中间写正则A 错误
匹配函数和原子
preg_matc 函数:根据$正则变量,匹配$字符串变量。如果存在则返回匹配的个数,把匹配到的结果放到$结果变量里。如果没有匹配到结果返回0。
int preg_match ( string $正则 , string $字符串 [, array &$结果] )
原子:需要匹配的内容,我们见到的空格、回车、换行、0-9、A-Za-z、中文、标点符号、特殊符号全为原子
特殊标志的原子:
原子 说明
\d 匹配一个0-9
\D 除了0-9以外的所有字符
\w a-zA-Z0-9_
\W 除了0-9A-Za-z_以外的所有字符
\s 匹配所有空白字符\n \t \r 空格
\S 匹配所有非空白字符
[ ] 指定范围的原子
[^ 字符] 不匹配指定区间的字符^ 抑扬符在中括号里面的作用是不准以中括号里面的字符进行匹配。
使用原子的时候,只能够匹配一个字符
元字符
元字符来修饰原子,实现更多次匹配
元字符 功能说明
*是代表匹配前面的一个原子,匹配0次或者任意多次前面的字符。
+匹配最少1次前面的字符
? 前面的一个字符可有可无【可选】 有或没有
. 更标准一些应该把点算作原子。匹配除了\n以外的所有字符
| 或者。注:它的优先级最低了。
^ 必须要以抑扬符之后的字符串开始
$ 必须要以$之前的字符结尾
{m} 有且只能出现m次
{n,m} 可以出现n到m次
{m,} 至少m次,最大次数不限制
() 改变优先级或者将某个字符串视为一个整体,匹配到的数据取出来也可以使用它
1.正则表达示是有边界的,这个边界是定界符的开始和结尾是正则的边界。
2.this是一个英文单词,后面加上一个空格,意味着这个词结束了,到达了这个词的边界
\b词边界,就是指匹配的字符必须要在最前或者最后。
\B非边界,就是匹配的字符不能在一个正则表达示的最前或者最后
模式匹配
模式匹配符的用法如下:
/ 正则表达式/模式匹配符
模式匹配符 功能
i 模式中的字符将同时匹配大小写字母.
m 当设定了此修正符,“行起始”和“行结束”除了匹配整个字符串开头和结束外,还分别匹配其中的换行符的之后和之前。
如果要匹配的字符串中没有“\n”字符或者模式中没有 ^ 或 $,则设定此修正符没有任何效果
s 将字符串视为单行,换行符\n作为普通字符.
如果设定了此修正符,模式中的圆点元字符(.)匹配所有的字符,包括换行符。
x 将模式中的空白忽略.
1.如果设定了此修正符,模式中的空白字符除了被转义的或在字符类中的以外完全被忽略。
2.未转义的字符类外部的#字符和下一个换行符之间的字符也被忽略。
A 强制仅从目标字符串的开头开始匹配.
D 模式中的美元元字符仅匹配目标字符串的结尾.
U 匹配最近的字符串.
e 将匹配项找出来,进行替换
e模式也叫逆向引用。主要的功能是将正则表达式括号里的内容取出来,放到替换项里面替换原字符串。
使用这个模式匹配符前必须要使用到preg_replace()。
preg_replace的功能:使用$正则匹配项,找到$查找字符串变量。然后用$替换项变量进行替换
mixed preg_replace ( mixed $正则匹配项 , mixed $替换项 , mixed $查找字符串)
常用正则函数
函数名 功能
preg_filter 执行一个正则表达式搜索和替换
preg_grep 返回匹配模式的数组条目
preg_match 执行一个正则表达式匹配
preg_match_all 执行一个全局正则表达式匹配
preg_replace_callback_array 传入数组,执行一个正则表达式搜索和替换使用回调
preg_replace_callback 执行一个正则表达式搜索并且使用一个回调进行替换
preg_replace 执行一个正则表达式的搜索和替换
preg_split 通过一个正则表达式分隔字符串