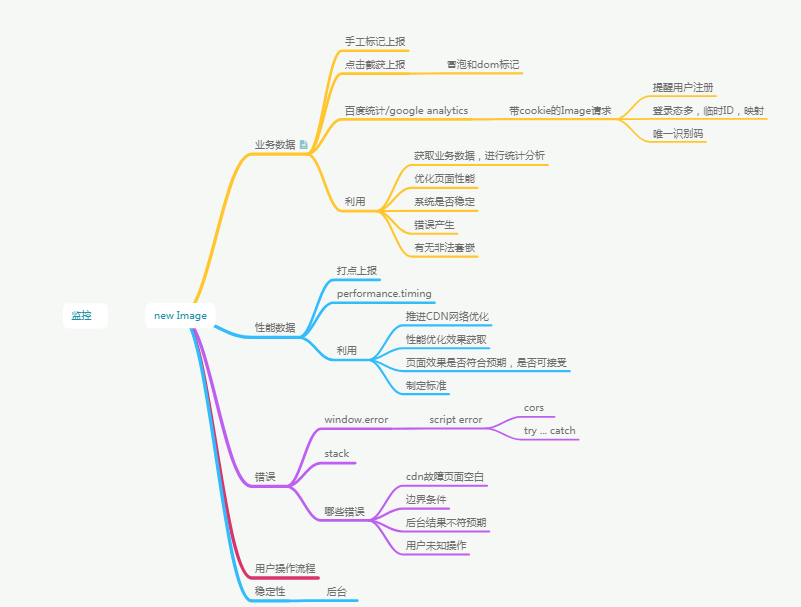
1 | <edit-modal dismiss="dismiss()" config="model.config" after-save="model.afterSave()" aaa="model.hello"></edit-modal> |
1 | export function editModalDirective() { |
link函数
link函数仅在编译时执行一次,三个参数:scope, ele, attrs
ele
即是当前的指令DOM对象,因此可以在ele上绑定触发事件,
但谨慎在数据上利用事件订阅触发机制进行事件绑定,
因为如果在外层包react组件的情况下,可能会导致数据刷新,但没有事件绑定,从而无法触发事件
注意在获取深层子dom时可能会获取不到
attrs
指ele所在dom上的属性集合,没有在scope属性中声明的属性也能看到
但要注意,属性值就是标签上变量的名,不是标签上变量指代的值
标签上属性赋值变量的值在参数scope中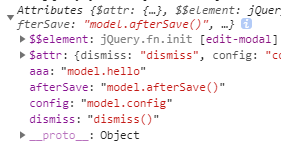
scope
link函数参数scope指向当前指令的作用域
参数scope的ctrl属性(controllerAs属性的值)即EditModalCtrl
因为这里配置了controller,bindToController,controllerAs,
所以在scope属性中声明的属性(config)方法(dismiss,after)会被归并到controller中,会以ctrl的属性形式出现,
即如果我想拿到属性scope中声明的config,可以这样:scope.ctrl.config
同时可以在EditModalCtrl中访问获取config,即this.config
另外如果没有在属性scope中声明的属性aaa,但在标签中进行了配置(aaa=”model.hello”),是无效的,ctrl上是不会有aaa属性的,即传递不进来
因此可以在link函数中拿到父作用域传递过来的值,分情况进行不同处理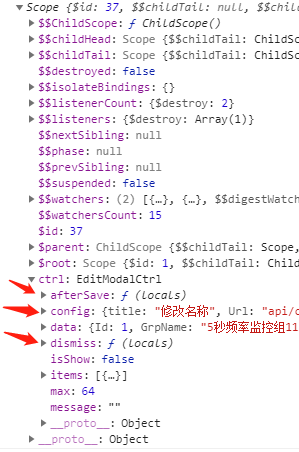
scope属性
建立子域,声明所在标签的属性名,以及传值方式,controler存在情况下被合并
@
@ 在 directive 中使用 xxx 属性绑定父 scope 中的属性。当改变父 scope 中属性的值的时候,directive 会同步更新值,当改变 directive 的 scope 的属性值时,父 scope 无法同步更新值。使用{{}}引用绑定值1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24app.controller("myController", function ($scope) {
$scope.name = "hello world";
}).directive("isolatedDirective", function () {
return {
scope: {
name: "@"
},
template: 'Say:{{name}} <br>改变隔离scope的name:<input type="buttom" value="" ng-model="name" class="ng-pristine ng-valid">'
}
})
<div ng-controller="myController">
<div class="result">
<div>父scope:
<div>Say:{{name}}<br>改变父scope的name:<input type="text" value="" ng-model="name"/></div>
</div>
<div>隔离scope:
<div isolated-directive name="{{name}}"></div>
</div>
<div>隔离scope(不使用{{name}}):
<div isolated-directive name="name"></div>
</div>
</div>
=
= 无论是改变父 scope 还是隔离 scope 里的属性,父 scope 和隔离 scope 都会同时更新属性值,因为它们是双向绑定的关系,使用“”引用绑定值1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25app.controller("myController", function ($scope) {
$scope.user = {
name: 'hello',
id: 1
};
}).directive("isolatedDirective", function () {
return {
scope: {
user: "="
},
template: 'Say:{{user.name}} <br>改变隔离scope的name:<input type="buttom" value="" ng-model="user.name"/>'
}
})
<div ng-controller="myController">
<div>父scope:
<div>Say:{{user.name}}<br>改变父scope的name:<input type="text" value="" ng-model="user.name"/></div>
</div>
<div>隔离scope:
<div isolated-directive user="user"></div>
</div>
<div>隔离scope(使用{{name}}):
<div isolated-directive user="{{user}}"></div>
</div>
</div>
&
& 用来绑定函数,在directive中调用父域中的函数
1 | app.controller("myController", function ($scope) { |
参考: https://blog.coding.net/blog/angularjs-directive-isolate-scope?type=early
transclude
类似于VUE的slot,但不如slot的灵活强,更倾向于定制插入,在固定位置插入
单点嵌入
设置属性 transclude:true
在模板中将 <ng-transclude></ng-transclude>放到要插入的位置
应用时<my-labe><span>1233</span></my-label>;
<span>1233</span> 会自动插入<ng-transclude></ng-transclude>之间
多点嵌入
设置属性 transclude :{模板中flag:页面应用时标签名的驼峰式,}
在模板中制定位置放置flag :<div ng-transclude=”flag”></div>
应用时 <my-label><my-title>123</my-title></my-label>
123 会自动插入<div ng-transclude=”flag”></div>之间
参考:https://segmentfault.com/a/1190000004586636
scope绑定
使用transcludeFn给transclude进来的Dom手动制定scope,
transcludeFn可来自compile,link的参数,或者controller的注入1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26.directive("todo", function(){
return {
restrict:"E",
transclude:"true",
template:"<header>{{header}}</header><div><span>这里是自定义区域</span><content-transclude></content-transclude></div>"
scope:{
header:"@"
},
controller:["$transclude",function(transcludeFn){
this.transcludeFn = transcludeFn;
}]
};
})
.directive("contentTransclude",funtion(){
return {
restrict:"E",
require:"^todo",
link:function(scope,element,attr,todoController){
todoController.transcludeFn(scope.$parent, function(transcludeContent){
element.append(transcludeContent);
});
}
};
})