csv 文本文件,没有多余格式,适用于各种场景使用,不仅适用各种算法,也适用数仓
jupyter notebook
执行: shift + 回车
注释:control + / ===>解释性文字
收起执行的结果: 点击蓝色边框
python install pandas numpy
pandas numpy 数据分析,数据挖掘
建模
拆分数据:
纵向拆分
x: 除目标列以外的列
y: 目标列
横向拆分:
训练集:模型学习
测试集: 验证模型效果
特征处理
特征缩放
数值类型的数据取值范围差异较大,导致模型在建模的时候忽略了某些属性对模型的重要度,
所以就需要通过特征缩放来平衡属性之间的权重
方法:标准化,最小值,最大值归一化
特征离散化
离散化:将连续数据转换成离散数据
数值的属性范围较大导致模型进行判断条件变多,进而影响模型效率
方法:
分箱: 1,1,1,1,1,1,4,5,1,10
等宽分箱:每个区间的范围大小是相同的
0-5 6-10
[1,1,1,1,1,1,4,5] [10]
等频分箱:每个区间的样本数量相同
[1,1,1,1,1] [1,1,4,5,10]
基于聚类的离散化
基于信息熵的;离散化
基于卡方的离散化
1R
特征编码
有一些模型无法处理字符串类型的数据,这个时候就需要通过特征编码将字符串类型数据转换成模型可以处理的数据
方法:
label-encoding(标签编码): 将字符串映射为对应数字eg: male –> 0, female –> 1,应用于二元属性和序数属性
one-hot-encoding(独热编码): 将字符串转换为不同的01组合,应用于标称属性(没有大小顺利的特征)
代码的方式
- 读取文件
1 | pip install pandas |
- 缺失值处理方式
删除:
按行删除:
按列删除: 该列数据超过20%缺失,可以考虑删除该列
填充: 通过特殊值填充,如:均值(数据为浮点性),中位数,众数(数据字符串),0
sklearn 也可以处理缺失值,填充 算法预测
1 |
|
- 异常值处理
异常值:
偏离正常样本过多的值,也叫噪声点,离群点,一般是极大或者极小的值
但不是错误值,只有数值类型(有数值含义)数据才会有异常值
处理:同缺失值
删除: 按行删除
替换: 使用特殊值替换,(当做缺失值处理)
异常值检测
箱线图
Q3 + 1.5IQR < X < Q1 - 1.5IQR
IQR = Q3 - Q1
Q3: 75% 分位数 Q: 25% 分位数
1.5 : 经验值,可容忍范围,可根据实际情况调整
3σ 原则: z-score
|x- μ| > 3σ
σ 标准差 μ 均值
务必根据实际情况分析, 比如年龄,可以设定 1-100 范围为正常值,则不需要再进行上述检测
1 | import matplotlib.pyplot as plt |
3.1 箱线图:进行异常值检测1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22while True:
list_error = []
Q1 = df_drop['malic'].quantile(0.25)
Q3 = df_drop['malic'].quantile(0.75)
IQR = Q3 - Q1
up = Q3 + 1.5*IQR
down = Q1 - 1.5*IQR
n = 0
for x in df_drop['malic']:
if x > up or x<down :
print(x)
df_drop.loc[:, 'malic'] = df_drop['malic'].replace(x,df_drop['malic'].mean()) # 填充
list_error.append(x)
if len(list_error) == 0:
break
for x in df_drop['malic']:
if x > up or x<down :
print(x)
plt.boxplot(df_drop['malic'])
plt.show()
3.2 3σ 原则: z-score
|x- μ| > 3σ
1 |
|
- 拆分数据
1 | # 纵向拆分 |
- 建模
1 | from sklearn.neighbors import KNeighborsClassifier |
- 评估
1 | model_knn.score(X_test,Y_test) |
- 保存模型
1 | pip install joblib |
8 预测
1 |
|
8.1 读取数据
1 | df = pd.read_csv('./wine3_pre.csv') |
8.2. 读取模型
1 | model = joblib.load('./红酒等级预测.pkl') |
8.3. 预测数据
1 | <!-- 把要预测的数据处理成跟训练的时候的维度一样 --> |
8.4 存储预测数据
1 | df.to_csv('./wine_model_pre.csv', index=False) |
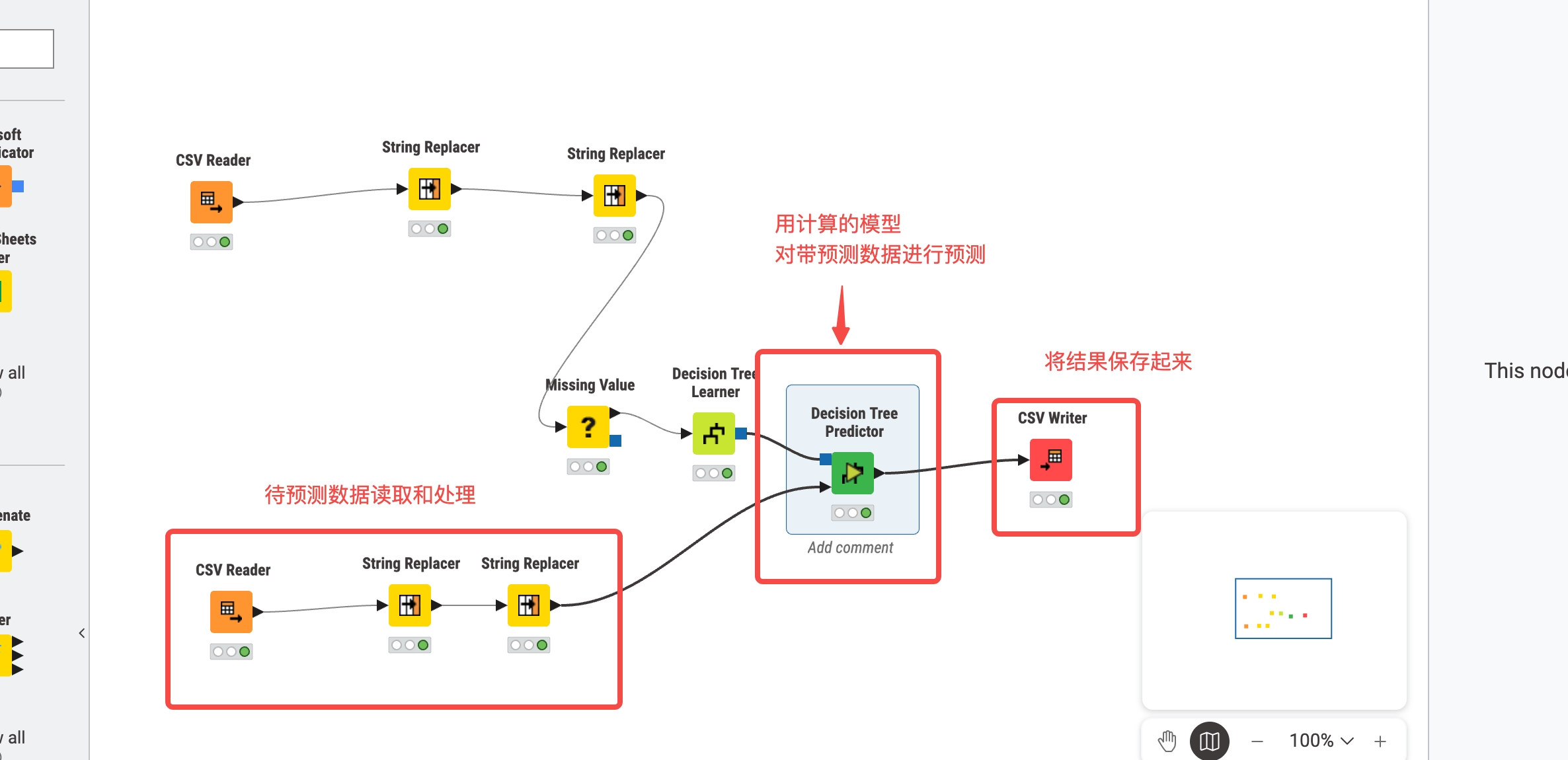
使用 knime
软件下载,要翻墙 https://www.knime.com/downloads
- 创建工作流
- 添加数据源
将csv Reader 拖到工作流绘制中心,并只指定训练数据文件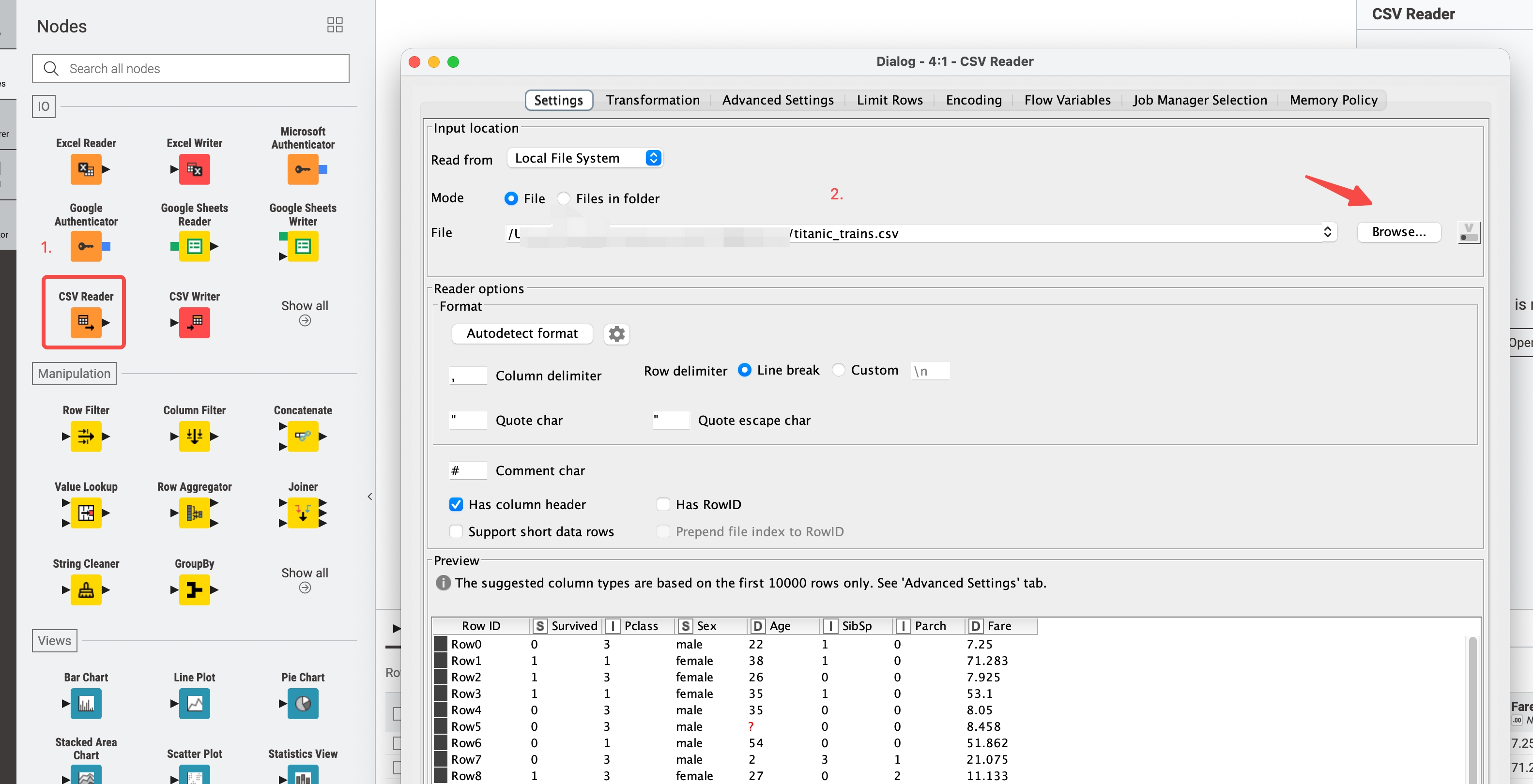
切换 transformation tab 可以指定要保留的列数据,和修改该列数据类型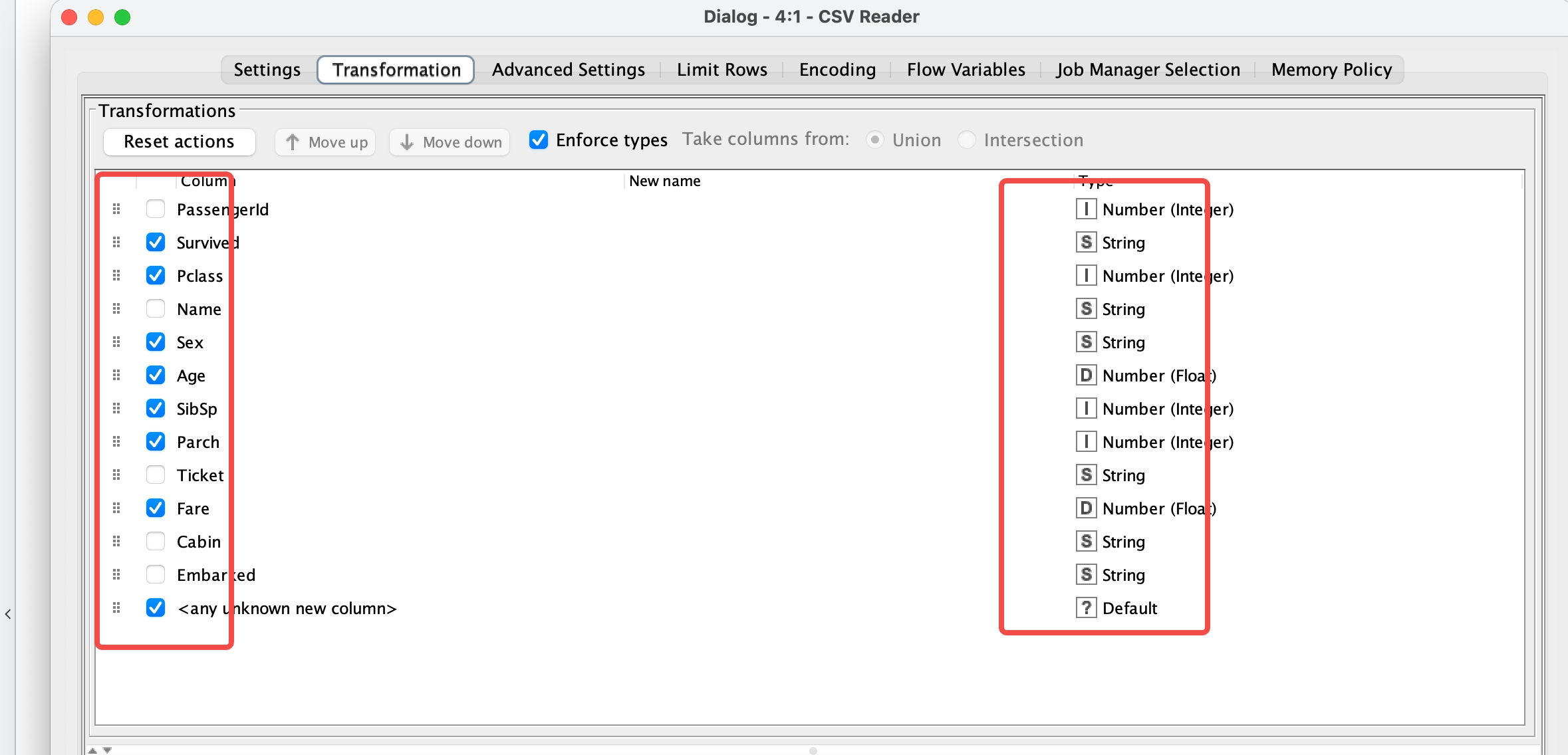
也可以再后续添加 string Replacer 进行具体数值转换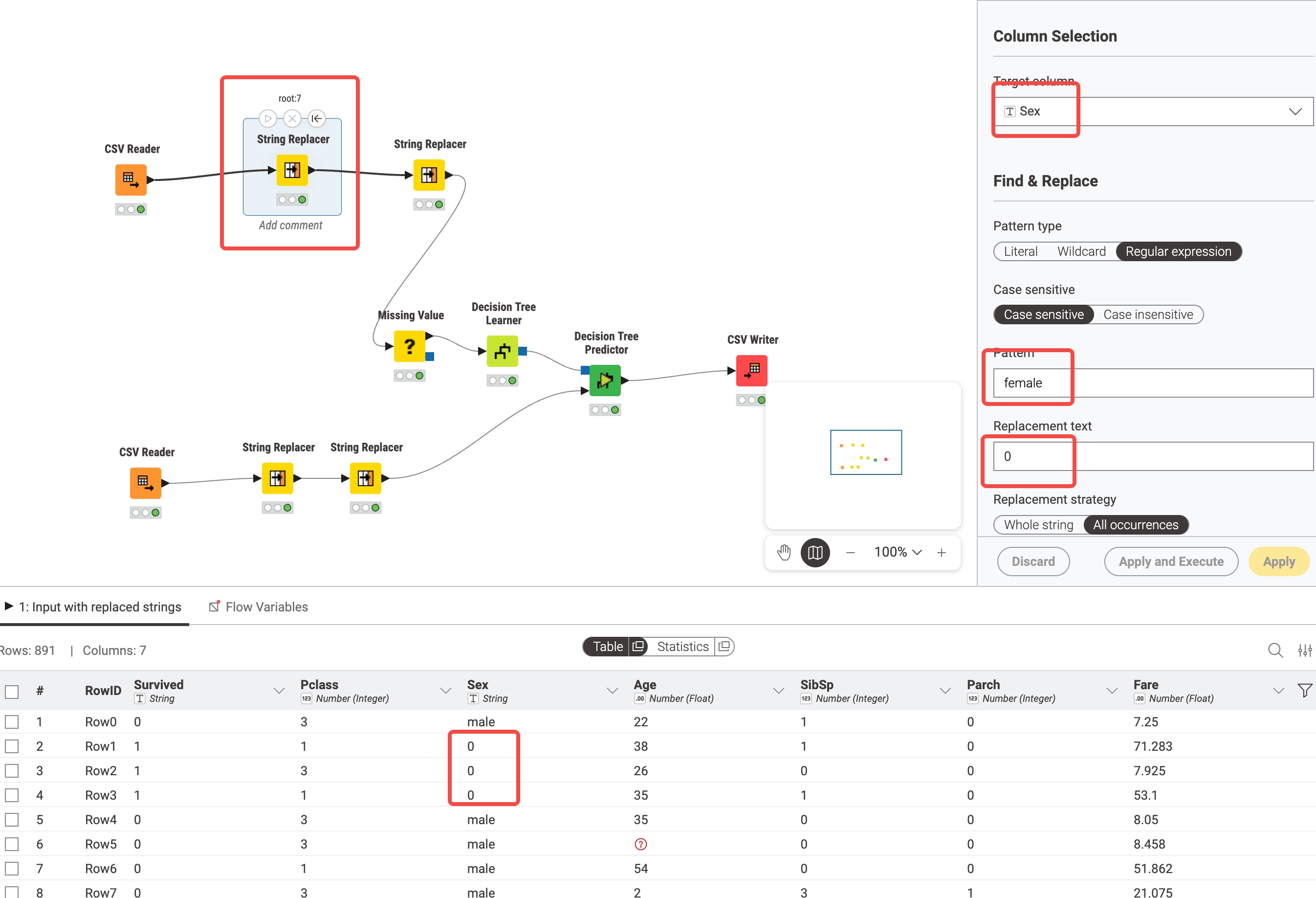
看起来一次只能改一个值,多个值进行转换,可以添加多个string Replacer
- 缺失异常值处理
添加misssing Value, 对常见数据类型添加缺失值处理规则
也可以对指定列进行缺失值处理规则指定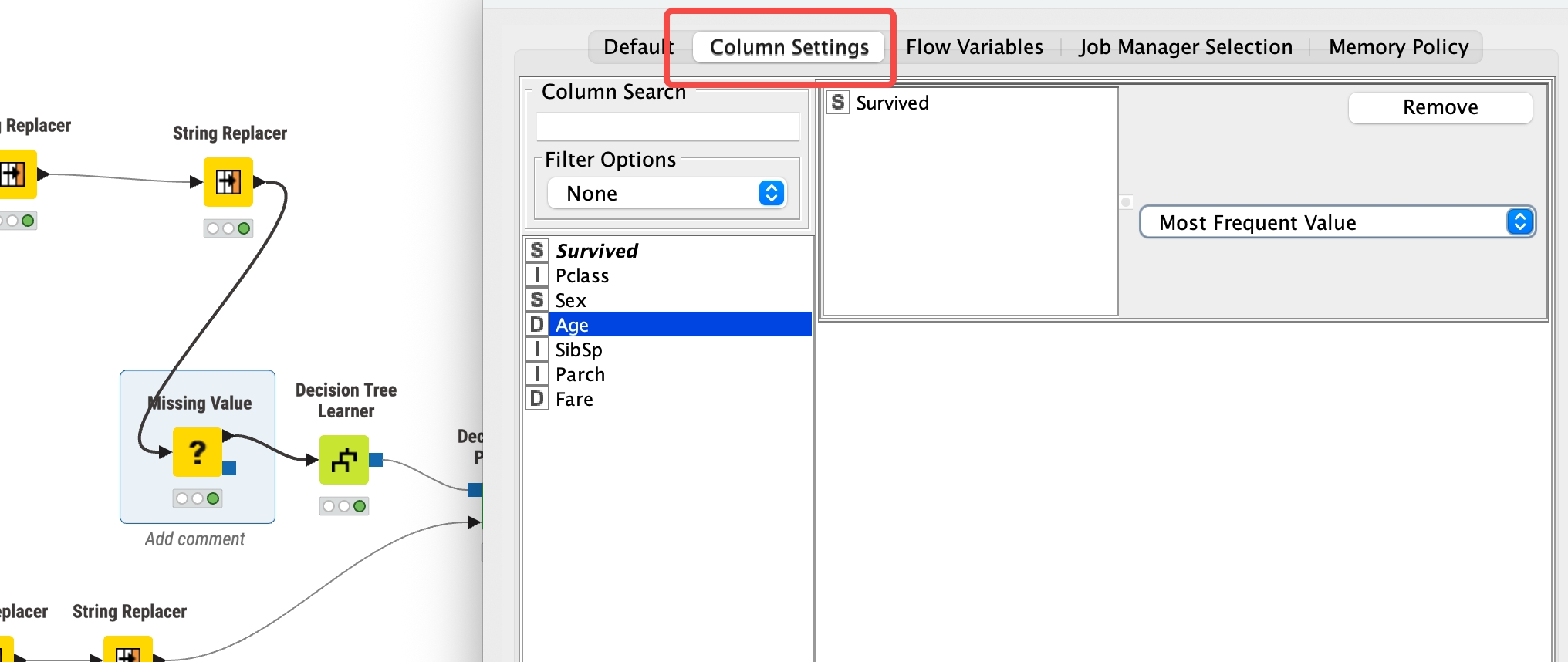
训练模型
选择算法指定,目标列
注意knime 只允许 数据类型为string 的列作为目标列,不是的话,要在前面步骤中进行转换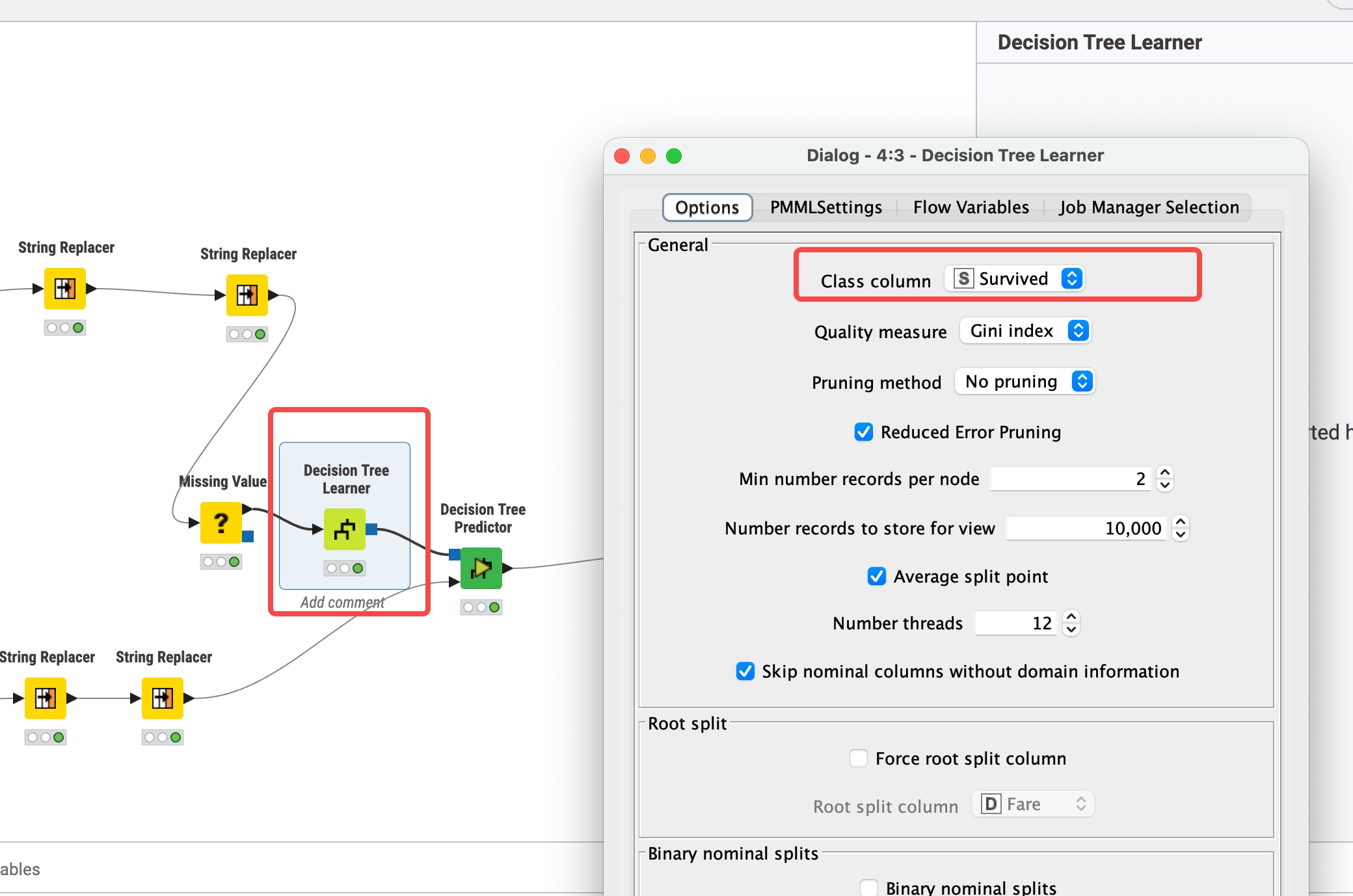
模型预测和结果保存
注意训练模型的算法和预测的算法要一致
添加模型预测,结果保存,csv Writer 需要指定保存的文件路径名称